ТЕМА «Кодирование текстовой информации»
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации:
N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
В оперативную память символы попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
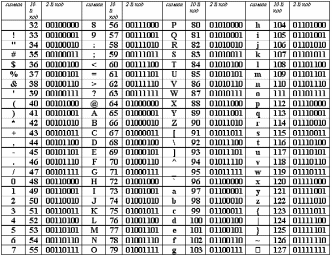
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части (смотреть приложение 2).
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
| Порядковый номер | Код | Символ |
| 0 — 31 | 00000000 — 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
| 32 — 127 | 00100000 — 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 — пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
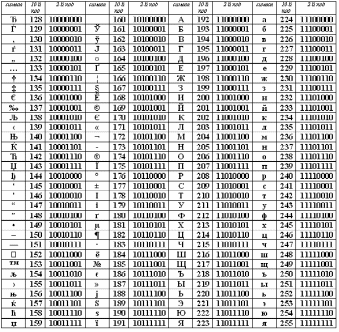
| 128 — 255 | 10000000 — 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита так же в основном соблюдается принцип последовательного кодирования.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
| Слово 1 | Память ПК | Слово 2 | Память ПК | ||
| file | f | 01100110 | disk | d | 01100100 |
| i | 01101001 | i | 01101001 | ||
| l | 01101100 | s | 01110011 | ||
| e | 01100101 | k | 01101011 |
Коротко о главном
Каждый символ текста кодируется восьмиразрядным двоичным кодом. Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код.
Все символы кодируются одинаковым числом бит (алфавитный подход)
Международным стандартом является код ASCII — американский стандартный код для информационного обмена.
Чаще всего используют кодировки, в которых на символ отводится 8 бит (8-битные ASCII) или 16 бит (16-битные Unicode)
После знака препинания внутри (не в конце!) текста ставится пробел
При измерении количества информации принимается, что в одном байте 8 бит, а в одном килобайте (1 Кбайт) – 1024 байта, в мегабайте (1 Мбайт) – 1024 Кбайта
Чтобы найти информационный объем текста I, нужно умножить количество символов N на число бит на символ K :
I=N*K
Примеры решения задач
Пример 1 Закодируйте кодом ASCII слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
| M | O | S | C | O | W |
| 01001101 | 01001111 | 01010011 | 01000011 | 01001111 | 01110111 |
ОТВЕТ:
100110110011111010011100001110011111110111
Пример 2
Задача 1. Информационный объём сообщения составляет 8,5 Кбайт (I). Данное сообщение содержит 8704 символа (N). Какое минимально возможное количество символов содержится в использованном алфавите?
Решение задачи 1.
Информационный объём сообщения 8,5 Кбайт = 8,5 * 1024 = 8704 байта
I / N = K (число бит на символ)
8704 байта / 8704 символа = Одному символу сообщения соответствует 1 байт = 8 бит
С помощью 8 бит (1 байта) можно закодировать 28 = 256 символов, это меньше количества символов, содержащихся в сообщении.
Ответ:
В использованном алфавите содержится 256 символов, что соответствует полному алфавиту ASCII.
Пример 3
Задача 2.
Автоматическое устройство осуществило перекодировку информационного сообщения, первоначально записанного в 7-битном коде ASCII, в 16-битную кодировку Unicode. При этом информационное сообщение увеличилось на 108 бит.
Какова длина сообщения в символах?
1) 12
2) 27
3) 6
4) 62
Решение задачи 2.
Изменение кодировки с 7 бит на 16 бит, равно 16 — 7 = 9 бит. Следовательно информационный объем каждого символа сообщения увеличился на 9 бит. По условиям задачи информационный объем сообщения после кодировки составил 108 бит, следовательно количество символов в сообщении = 108/9 = 12.
Ответ: 1) 12 символов.
Пример 4
Задача 3.
В одной из кодировок Unicode каждый символ кодируется 16 битами.
Определите размер следующего предложения в данной кодировке:
«Тише едешь – дальше будешь!»
-
216 бит
-
27 байт
-
54 байта
-
46 байт
Решение задачи 3:
Каждый символ кодируется 16 битами. Значит общее количество бит во всем предложении равно количеству символов умноженному на 16. Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Ответ: 3) 54 байта.
ЗАКРЕПЛЕНИЕ МАТЕРИАЛА.
Задание 1. Расшифруйте сообщение, используя таблицу ASCII.
| 1001001 | |
| 1101110 | |
| 1100110 | |
| 1101111 | |
| 1110010 | |
| 1101101 | |
| 1100001 | |
| 1110100 | |
| 1101001 | |
| 1101111 | |
| 1101110 |
Задание 2.
Задача. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения:
Один пуд – около 16,4 килограмм.
ПРИЛОЖЕНИЕ 1
Аналогичные (Базовой таблице кодировки ASCII) системы кодирования текстовых данных были разработаны и в других странах.
Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
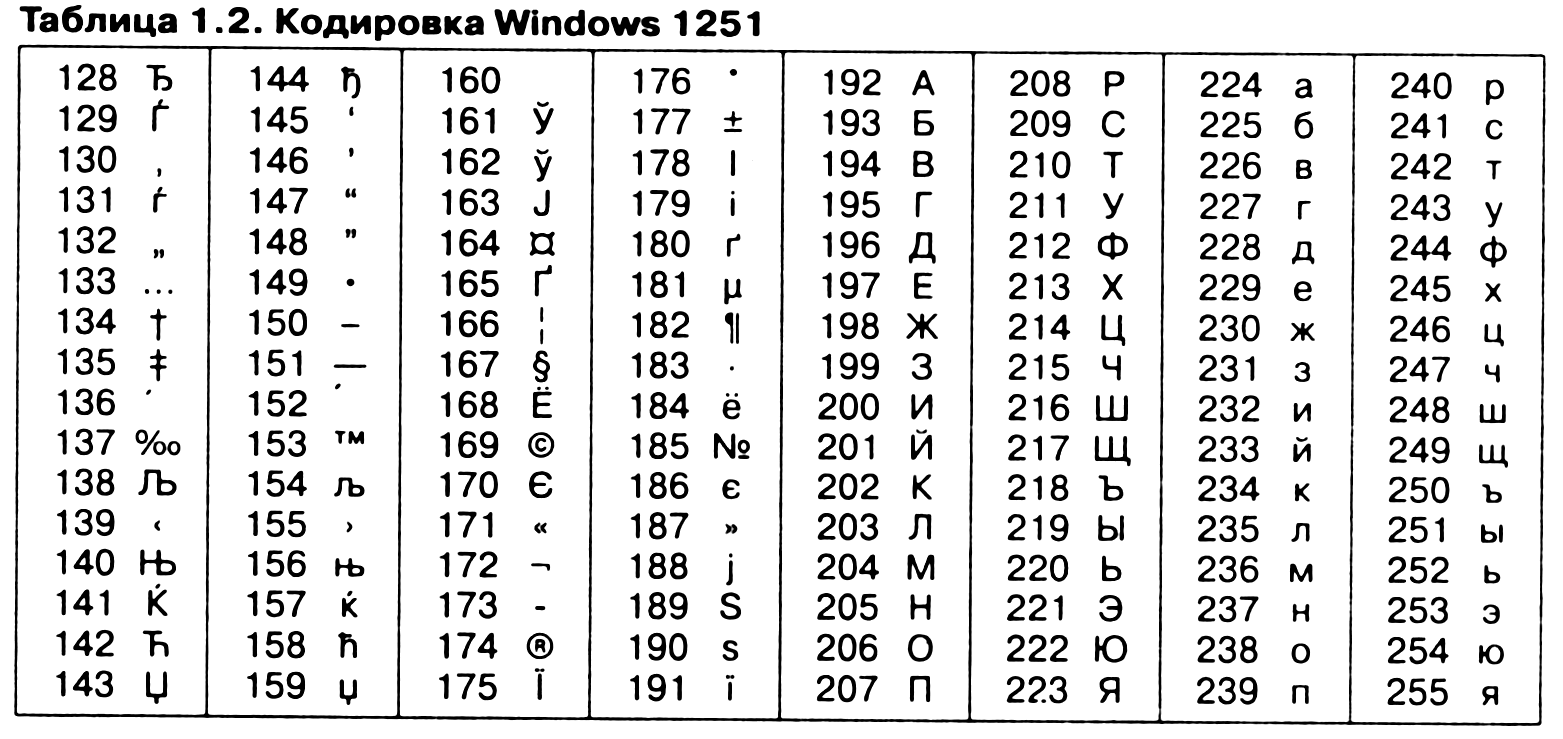
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
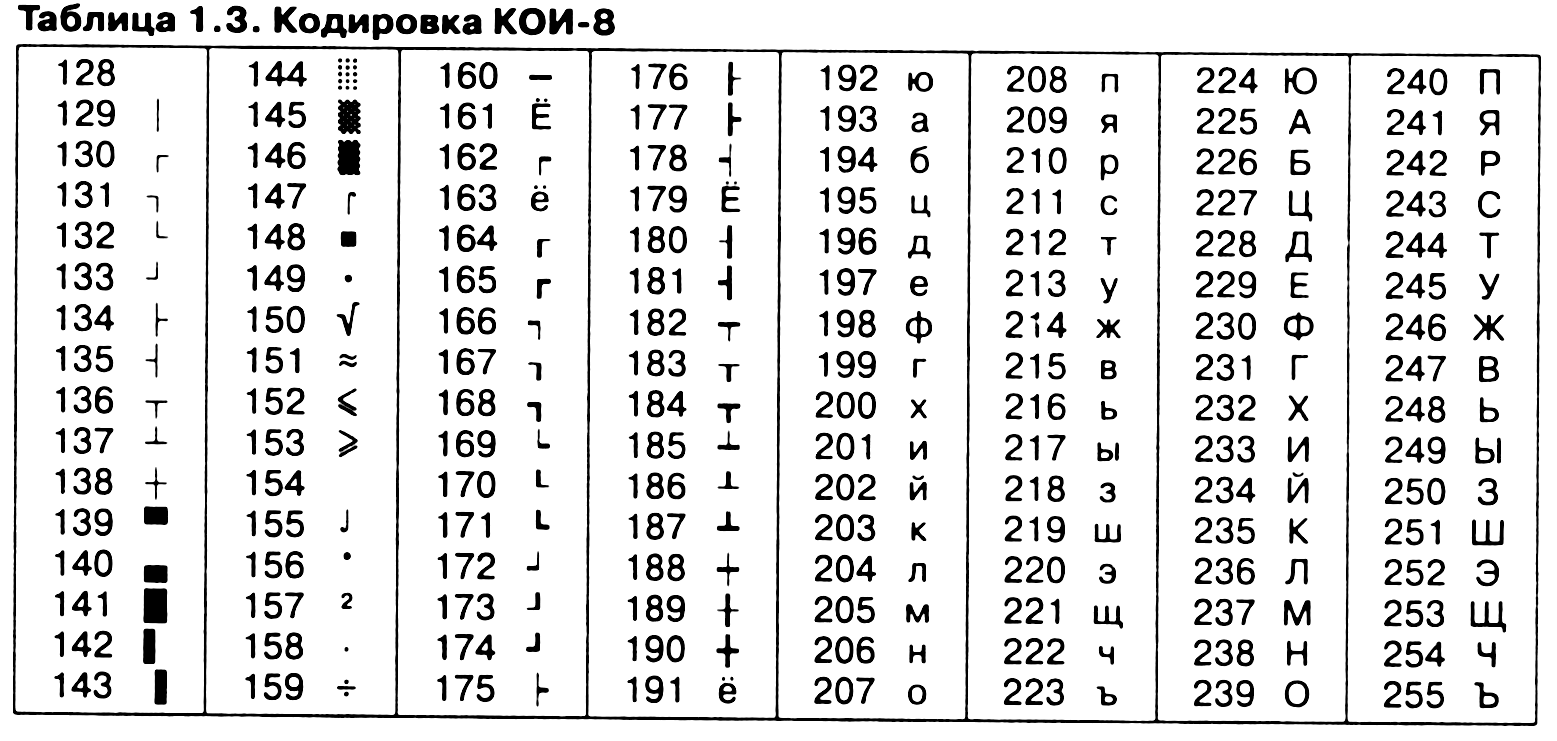
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).
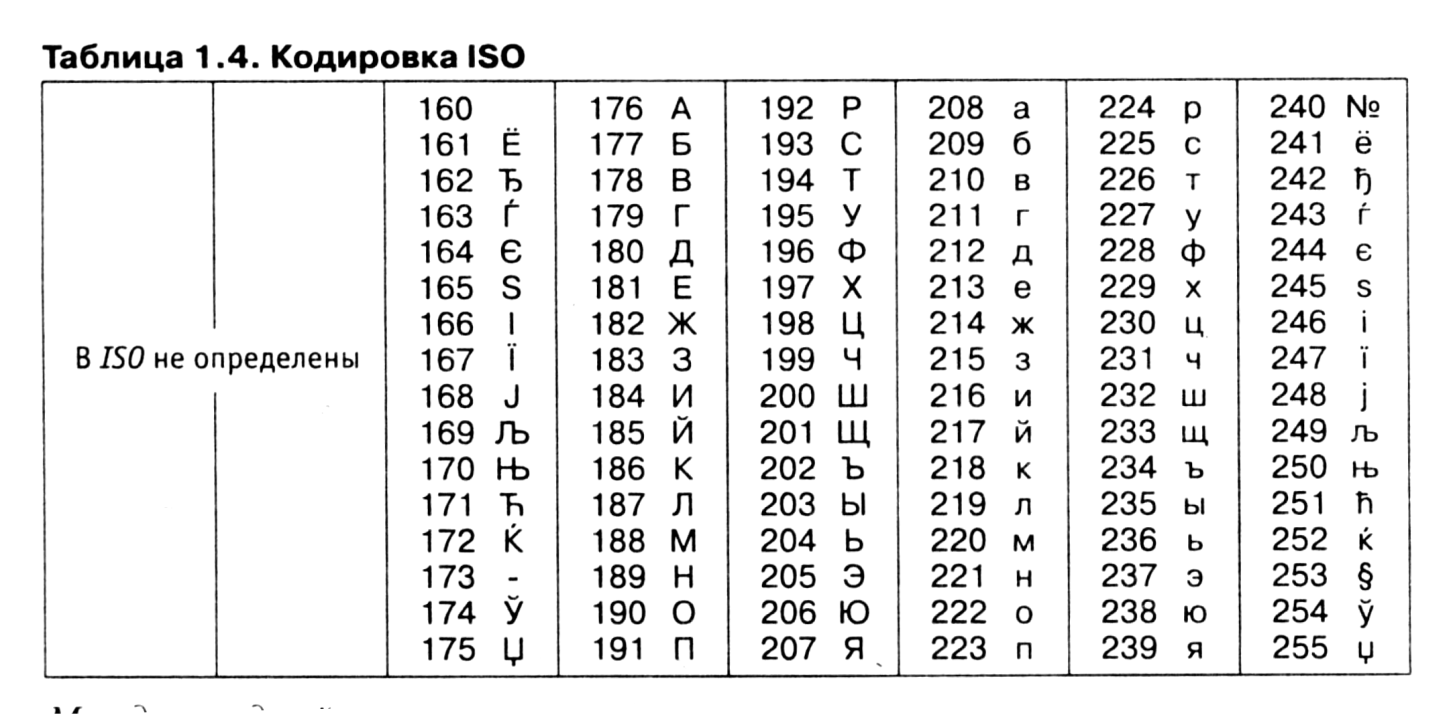
На компьютерах, работающих в операционных системах MS—DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).
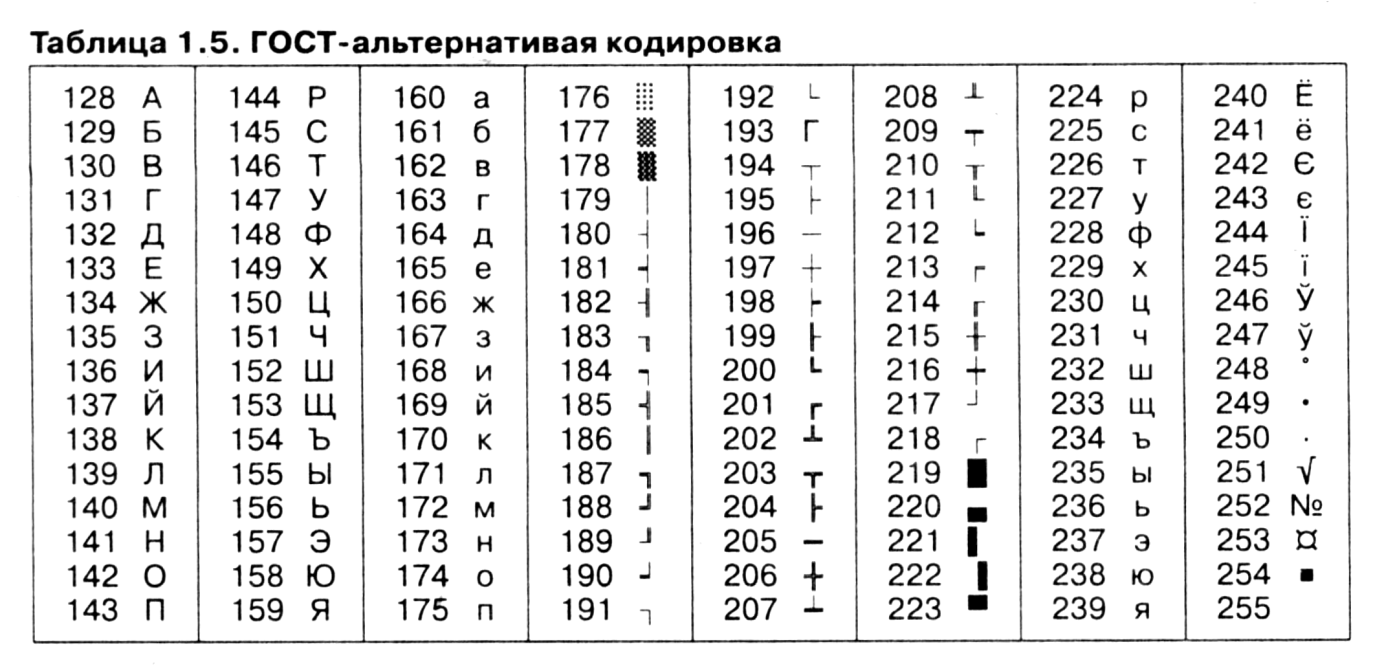
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Первая половина таблицы кодов ASCII
Вторая половина таблицы кодов ASCII
8
1 этап (теория) – представление урока в
виде презентации
(Приложение 1)
Для того чтобы сохранить на внешних носителях
текстовый документ, созданный с помощью
компьютера, он должен быть представлен двоичным
кодом с помощью двух цифр – 0 и 1.
Самый удобный и понятный способ такого
представления следующий:
1) записать алфавит;
2) пронумеровать все буквы по порядку;
3) номер буквы перевести в двоичную систему
счисления;
4) составить таблицу соответствия символов
двоичным или десятичным кодам.
А теперь посчитаем, сколько бит необходимо для
кодирования одновременно:
- Символов типа № % * ? – (не менее 15)
- Букв латинского алфавита (строчных и прописных)
– 52 - Букв кириллицы (русский алфавит) – 66
- Цифры – 10
Уже получилось 143 символа.
Чтобы закодировать такое количество символов
необходимо не менее 8 бит (или 1 байт)
Теперь мы знаем, что для кодирования одного
символа требуется один байт
информации.
И так кодирование заключается в том, что каждому
символу ставиться в соответствие уникальный
двоичный код от 00000000 до 11111111 (или десятичный код
от 0 до 255).
Важно, что присвоение символу конкретного кода –
это вопрос соглашения, которое фиксируется
кодовой таблицей.
Таблица, в которой всем символам компьютерного
алфавита поставлены в соответствие порядковые
номера (коды), называется таблицей кодировки.
Для разных типов ЭВМ используются различные
кодировки.
С распространением IBM PC международным стандартом
стала таблица кодировки ASCII (American Standart
Code for Information Interchange) – Американский стандартный
код для информационного обмена.
Стандартной в этой таблице является только
первая половина, т.е. символы с номерами от 0 (00000000)
до 127 (0111111). Сюда входят буква латинского
алфавита, цифры, знаки препинания, скобки и
некоторые другие символы.
Остальные 128 кодов используются в разных
вариантах. Например, в русских кодировках
размещаются символы русского алфавита.
Так же получил широкое распространение новый
международный стандарт Unicode (Юникод), который
отводит на каждый символ два байта. С его помощью
можно закодировать 65 536 (216= 65 536) различных
символов.
Решение задач
Пример1. Записать слово «stop» в
двоичном и десятичном кодах.
Решение. Двоичный 001110011 01110100 01101111 01110000
Десятичный 115 116 111 112
Пример 2. Сколько бит памяти
компьютера займет слово «Микропроцессор»?
Решение. Слово состоит из 14 букв. Каждая
буква является символом компьютерного алфавита,
поэтому занимает 1 байт памяти. Слово займет 14
байт (112 бит)
Пример 3. Текст занимает 0,25 Кбайт
памяти компьютера, Сколько символов содержит
этот текст?
Решение. 0,25 х 1024 = 256 (байт); 256 : 1 (байт) = 256
символов.
Пример 4. С помощью десятичных кодов
зашифровано слово «stop» 115 116 111 112.
Записать последовательность десятичных кодов
для этого же слова, но записанного заглавными
буквами.
Решение. При шифровке не обязательно
пользоваться таблицей. Достаточно учесть, что
разница между кодом строчных и прописных букв
равна 32. 115 – 32 = 83; 116 – 32 = 84; 111 – 32 = 79; 112 – 32 = 80.
Слову «STOP» соответствует последовательность
кодов: 83 84 79 80.
Пример 5. Оценить информационный объем
фразы, закодированной с помощью Юникода:
Без труда не вытащишь и рыбку из пруда
Решение. В Юникоде 1 символ закодирован 2
байтами или 16 битами. Во фразе 38 символов (с
учетом пробелов). В байтах – 38 х 2 = 76 байтов; в
битах 38 х 16 = 608 бит.
Домашнее задание: Тема «Тексты в
компьютерной памяти». Задание: Закодировать в
двоичной форме свою фамилию, используя таблицу в
учебнике.
Урок 2. Лабораторная работа
Цель: Познакомить учащихся с
различными кодировками символов, используя
текстовые редакторы.
Задача: Выполнить задания в различных
текстовых приложениях
1. Текстовый редактор Блокнот
Открыть блокнот.
а) Используя клавишу Alt и малую цифровую
клавиатуру раскодировать фразу:
145 170 174 224 174 255 170 160 173 168 170 227 171 235;
Технология выполнения задания: При
удерживаемой клавише Alt, набрать на малой
цифровой клавиатуре указанные цифры. Отпустить
клавишу Alt, после чего в тексте появится буква,
закодированная набранным кодом.
Ответ: скоро каникулы
б) Используя ключ к кодированию, закодировать
слово – зима;
Технология выполнения задания: Из
предыдущего задания выяснить, каким кодом
записана буква а. Учитывая, что буквы кодируются
в алфавитном порядке, выяснить коды остальных
букв.
Ответ: 167 168 172 160
Что вы заметили при выполнении этого задания во
время раскодировки? Запишите свои наблюдения.
Возможный вариант: в кодировочной таблице
нет буквы ё.
2. Текстовый процессор MS Word.
Технология выполнения задания: рассмотрим
на примере: представить в различных кодировках
слово Кодировка
Решение:
- Создать новый текстовый документ в Word;
- Выбрать – Команда – Вставка –
Символ.
В открывшемся окне «Символ» установить из:
Юникод (шестн.), - В наборе символов находим букву К и
щелкнем на ней левой кнопкой мыши (ЩЛКМ). - В строке код знака появится код выбранной
буквы 041А (незначащие нули тоже записываем). - У буквы о код – 043Е и так далее: д – 0434, и
– 0438, р – 0440, о – 043Е, в – 0432, к – 043А, а – 0430. - Установить Кириллица (дес.)
- К – 0202, о – 0238, д – 0228, и – 0232, р – 0240, о – 0238, в
–0226, к – 0202, а –0224.
Задание: Открыть Word.
Используя окно «Вставка символа» выполнить
задания: Закодировать слово Forest
а) Выбрать шрифт Courier New, кодировку ASCII(дес.)
Ответ: 70 111 114 101 115 116
б) Выбрать шрифт Courier New, кодировку Юникод(шест.)
Ответ: 0046 006F 0072 0665 0073 0074
в) Выбрать шрифт Times New Roman, кодировку
Кирилица(дес.) Ответ: 70 111 114 101 115 116
г) Выбрать шрифт Times New Roman, кодировку ASCII(дес.)
Ответ: 70 111 114 101 115 116
Вывод: _________________________________________________________
Ответ вывода: код символа не зависит
от типа шрифта. Предлагаемые MS Word кодировки
кодируют символы одинаково.
3. Составьте 3 варианта объявления о наборе
группы обучения работе в Текстовых приложениях.
а) в Текстовом редакторе Блокнот
б) в Текстовом процессоре Word
в) в Издательской системе Publisher (публикация)
Ответьте на вопрос: в чем отличительные
особенности (положительные и отрицательные)
каждого из использованных приложений. Оформите
ответ в виде вывода.
Вывод: __________________________________________________________
Ответ вывода: блокнот –
положительное: простота использования,
отрицательные: ограничение возможностей
Word положительное: множество возможностей,
отрицательные: сложность использования Publisher
положительное : множество профессиональных
возможностей, отрицательные: необходимость
определенных навыков работы и знаний
2 этап (практика) – Лабораторная работа
«Представление текстовой информации в
компьютере»
Практическая работа «Вставка
символов в тексте» (Приложение
3)
Выполнение лабораторной работы
оформить в виде таблицы:
| № | Задание | Ответ | Выводы |
| 1а | Раскодировать фразу | скоро каникулы | |
| 1б | закодировать слово – зима | 167 168 172 160 | код символа не зависит от типа |
| 1а | Закодировать слово Forest шрифт Courier New, кодировка ASCII(дес.) | 70 111 114 101 115 116 | |
| 2б | Закодировать слово Forest шрифт Courier New, кодировка Юникод(шест.) | 0046 006F 0072 0665 0073 0074 | |
| 2в | Закодировать слово Forest шрифт Times New Roman, кодировка Кирилица(дес.) | 70 111 114 101 115 116 | |
| 2г | Закодировать слово Forest шрифт Times New Roman, кодировка ASCII(дес.) | 70 111 114 101 115 116 | |
| 3а | Объявление в блокноте о наборе группы обучения работе в Текстовых приложениях. | Объявление.txt | положительное: простота использования, отрицательные: ограничение возможностей |
| 3б | Объявление в Word о наборе группы обучения работе в Текстовых приложениях. | Объявление.doc | положительное: множество возможностей, отрицательные: сложность использования |
| 3в | Объявление в Publisher о наборе группы обучения работе в Текстовых приложениях. | Объявление.pbl | положительное : множество профессиональных возможностей, отрицательные: необходимость определенных навыков работы и знаний |
3 этап (контроль) – Тест по
теме для 2-х вариантов (на 10-15 минут)
(Приложение 2)
Тест, выполненный в MS Excel, содержит задания типа
А и В для двух вариантов.
1 вариант.
1. Буква Z имеет десятичный код 90, а z – 122.
Записать слово «sport» в десятичном коде. Ответ: 115
112 111 114 116
2. С помощью десятичных кодов зашифровано слово
«info» 105 110 102 111. Записать последовательность
десятичных кодов для этого же слова, но
записанного заглавными буквами. Ответ: 73 78 70
79
3. Текст занимает 0,5 Кбайт памяти компьютера,
Сколько символов содержит этот текст? Ответ: 512
4. Сколько бит памяти компьютера займет слово
«Антивирус»? Ответ: 72
5. Буква Б имеет код 193, а б – 295. Запишите через
пробел коды букв Л и л. Ответ: 203 235
6. Оцените информационный объем фразы,
закодированной с помощью Юникода: Делу время,
потехе час Ответ: 352 бита
2 вариант.
1. Буква Z имеет десятичный код 90, а z – 122.
Записать слово «forma» в десятичном коде. Ответ: 102
111 114 109 97
2. С помощью десятичных кодов зашифровано слово
«port» 112 111 114 116. Записать последовательность
десятичных кодов для этого же слова, но
записанного заглавными буквами. Ответ: 80 79 82
84
3. Текст занимает 0,75 Кбайт памяти компьютера,
Сколько символов содержит этот текст? Ответ: 768
4. Сколько бит памяти компьютера займет слово
«Информация»? Ответ: 80
5. Буква Я имеет код 223, а я – 255. Запишите через
пробел коды букв Ш и ш. Ответ: 216 248
6. Оцените информационный объем фразы,
закодированной с помощью Юникода: Делу время,
потехе час Ответ: 44 байта
Кодирование текстовой информации
Текстовая
информация состоит из символов: букв,
цифр, знаков препинания и др. Одного
байта достаточно для хранения 256 различных
значений, что позволяет размещать в нем
любой из алфавитно-цифровых символов.
Первые 128 символов (занимающие семь
младших бит) стандартизированы с помощью
кодировки ASCII (American Standart Code for Information
Interchange). Суть кодирования заключается
в том, что каждому символу ставят в
соответствие двоичный код от 00000000 до
11111111 или соответствующий ему десятичный
код от 0 до 255. Для кодировки русских букв
используют различные кодовые таблицы
(КОI-8R,
СР1251, CP10007,
ISO-8859-5):
KOI8R
— восьмибитовый стандарт кодирования
букв кириллических алфавитов (для
операционной системы UNIX).
Разработчики KOI8R
поместили символы русского алфавита в
верхней части расширенной таблицы ASCII
таким образом, что позиции кириллических
символов соответствуют их фонетическим
аналогам в английском алфавите в нижней
части таблицы. Это означает, что из
текста написанного в KOI8R,
получается текст, написанный латинскими
символами. Например, слова «дом высокий»
приобретают форму «dom
vysokiy»;
СР1251
– восьмибитовый стандарт кодирования,
используемый в OS
Windows;
CP10007
—
восьмибитовый стандарт кодирования,
используемый в кириллице операционной
системы Macintosh (компьютеров фирмы Apple);
ISO-8859-5
– восьмибитовый код, утвержденный в
качестве стандарта для кодирования
русского языка.
Кодирование графической информации
Графическую
информацию можно представлять в двух
формах: аналоговой
и дискретной.
Живописное
полотно,
созданное художником, — это пример
аналогового представления,
а изображение, напечатанное
при помощи принтера,
состоящее из отдельных (элементов) точек
разного цвета, — это дискретное
представление.
Путем
разбиения графического изображения
(дискретизации) происходит преобразование
графической информации из аналоговой
формы в дискретную. При этом производится
кодирование — присвоение каждому элементу
графического изображения конкретного
значения в форме кода. Создание и хранение
графических объектов возможно в
нескольких видах — в виде векторного,
фрактального
или растрового
изображения. Отдельным предметом
считается
3D (трехмерная) графика,
в которой сочетаются векторный и
растровый способы формирования
изображений.
Векторная
графика
используется для представления таких
графических изображений как рисунки,
чертежи, схемы.
Они
формируются из объектов — набора
геометрических примитивов (точки, линии,
окружности, прямоугольники), которым
присваиваются некоторые характеристики,
например, толщина линий, цвет заполнения.
Изображение
в векторном формате упрощает процесс
редактирования, так как изображение
может без потерь масштабироваться,
поворачиваться, деформироваться. При
этом каждое преобразование уничтожает
старое изображение (или фрагмент), и
вместо него строится новое. Такой способ
представления хорош для схем и деловой
графики. При
кодировании векторного изображения
хранится не само изображение объекта,
а координаты точек,
используя которые программа каждый раз
воссоздает изображение заново.
Основным
недостатком
векторной графики является невозможность
изображения фотографического качества.
В векторном формате изображение всегда
будет выглядеть, как рисунок.
Растровая
графика.
Любую картинку можно разбить на квадраты,
получая, таким образом,
растр
— двумерный массив квадратов. Сами
квадраты —
элементы растра или пиксели
(picture’s element) — элементы картинки. Цвет
каждого пикселя кодируется числом, что
позволяет для описания картинки задавать
порядок номеров цветов (слева направо
или сверху вниз). В память записывается
номер каждой ячейки, в которой хранится
пиксель.
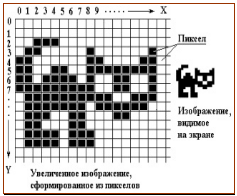
Рисунок
в растровом формате
Каждому
пикселю сопоставляются значения яркости,
цвета, и прозрачности или комбинация
этих значений. Растровый образ имеет
некоторое число строк и столбцов. Этот
способ хранения имеет свои недостатки:
больший объём памяти, необходимый для
работы с изображениями.
Объем
растрового изображения определяется
умножением количества пикселей на
информационный объем одной точки,
который зависит от количества возможных
цветов. В современных компьютерах в
основном используют следующие разрешающие
способности экрана: 640 на 480, 800 на 600, 1024
на 768 и 1280 на 1024 точки. Яркость каждой
точки и ее координаты можно выразить с
помощью целых чисел, что позволяет
использовать двоичный код для того
чтобы обрабатывать графические данные.
В
простейшем случае (черно-белое изображение
без градаций серого цвета) каждая точка
экрана может иметь одно из двух состояний
— «черная» или «белая», то есть для
хранения ее состояния
необходим 1 бит. Цветные изображения
формируются в соответствии с двоичным
кодом цвета каждой точки, хранящимся в
видеопамяти. Цветные изображения могут
иметь различную глубину
цвета,
которая задается количеством битов,
используемым для кодирования цвета
точки. Наиболее распространенными
значениями глубины цвета являются 8,
16, 24, 32, 64 бита.
Для
кодирования цветных графических
изображений произвольный цвет делят
на его составляющие. Используются
следующие системы кодирования:
HSB
(H
— оттенок (hue),
S
— насыщенность
(saturation), B
— яркость (brightness)),
RGB
(Red
— красный,
Green
— зелёный,
Blue
—
синий)
и
CMYK
(Cyan
— голубой, Magenta
– пурпурный, Yellow
— желтый и Black
– черный).
Первая
система удобна для человека,
вторая — для компьютерной
обработки,
а последняя — для типографий.
Использование этих цветовых систем
связано с тем, что световой поток может
формироваться излучениями, представляющими
собой комбинацию «чистых» спектральных
цветов: красного, зеленого, синего или
их производных.
Фрактал –
это объект, отдельные элементы которого
наследуют свойства родительских
структур. Поскольку более детальное
описание элементов меньшего масштаба
происходит по простому алгоритму,
описать такой объект можно всего лишь
несколькими математическими уравнениями.
Фракталы позволяют описывать изображения,
для детального представления которых
требуется относительно мало памяти.

Рисунок
в фрактальном формате
Трёхмерная
графика (3D)
оперирует с объектами в трёхмерном
пространстве. Трёхмерная компьютерная
графика широко используется в кино,
компьютерных играх, где все объекты
представляются как набор поверхностей
или частиц. Всеми визуальными
преобразованиями в 3D-графике управляют
с помощью операторов,
имеющих матричное представление.
Кодирование
звуковой информации
Музыка,
как и любой звук, является не чем иным,
как звуковыми колебаниями, зарегистрировав
которые, её можно достаточно точно
воспроизвести. Для представления
звукового сигнала в памяти компьютера,
необходимо поступившие акустические
колебания представить в цифровом виде,
то есть преобразовать в последовательность
нулей и единиц. С помощью микрофона звук
преобразуется в электрические колебания,
после чего можно измерить амплитуду
колебаний через равные промежутки
времени (несколько десятков тысяч раз
в секунду), используя специальное
устройство — аналого-цифровой
преобразователь
(АЦП).
Для воспроизведения звука цифровой
сигнал необходимо превратить в
аналоговый с помощью цифро-аналогового
преобразователя
(ЦАП).
Оба эти устройства встроены в звуковую
карту
компьютера. Указанная последовательность
превращений представлена на рис.
2.6.[41].
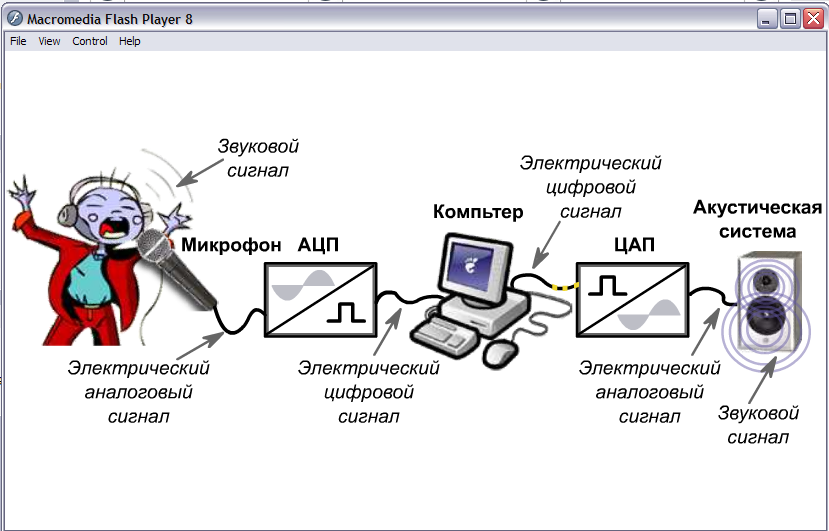
Трансформация
аналогового сигнала в цифровой и обратно
Каждое
измерение звука записывается в двоичном
коде. Этот процесс называется
дискретизацией (семплированием),
выполняемым
с помощью АЦП.
Семпл
(sample
англ. образец) — это промежуток времени
между двумя измерениями амплитуды
аналогового сигнала. Кроме промежутка
времени семплом называют также любую
последовательность цифровых данных,
которые получили путем аналого-цифрового
преобразования. Важным параметром
семплирования
является
частота — количество измерений амплитуды
аналогового сигнала в секунду. Диапазон
частоты дискретизации звука от 8000 до
48000 измерений за одну секунду.
Графическое
представление процесса дискретизации
На
качество воспроизведения влияют
частота дискретизации и разрешение
(размер
ячейки, отведённой под запись значения
амплитуды). Например, при записи музыки
на компакт-диски используются 16-разрядные
значения и частота дискретизации 44032
Гц.
На
слух человек воспринимает звуковые
волны, имеющие частоту в пределах от 16
Гц до 20 кГц (1 Гц — 1 колебание в секунду).
В
формате компакт-дисков Audio DVD за одну
секунду сигнал измеряется 96 000 раз, т.е.
применяют частоту семплирования 96 кГц.
Для экономии места на жестком диске в
мультимедийных приложениях довольно
часто применяют меньшие частоты: 11, 22,
32 кГц. Это приводит к уменьшению слышимого
диапазона частот, а, значит, происходит
искажение того, что слышно.
Соседние файлы в папке Информатика лекции вар.2
- #
17.04.20153.09 Mб15bt1_Основные понятия информатики.doc
- #
- #
- #
- #
Кодировать можно не только числа.
В зависимости от цели различные преобразования, включая представление в виде
последовательности нулей и единиц, можно выполнять с информацией разных видов.
Например, кодирование и декодирование текстовой информации выполняется для
шифровки и расшифровки секретных сообщений, для перевода слов и предложений с
одного языка на другой и обратно, а также для автоматизации хранения, обработки
или передачи текстовой информации с помощью компьютерной техники.
В информатике под текстом понимается
любая последовательность символов из определенного алфавита. Для применения
компьютера при работе с текстовой информацией необходим компьютерный алфавит.
Компьютерный алфавит состоит из букв, цифр, знаков препинания и других
символов. Все символы представлены в компьютере в виде двоичного кода.
В отличие от кодирования чисел, в
распоряжении человека нет правил или формул, которые позволили бы, зная любой
символ алфавита, вычислить соответствующее ему число. Тем не менее, существуют
подходы, позволяющие сопоставить символы и числа. Например, можно воспользоваться
тем, что все символы в алфавите упорядочены. Поэтому каждому символу алфавита
можно поставить в соответствие его порядковый номер. Соответствие между
символом алфавита и его порядковым номером устанавливается с помощью таблиц
кодировки, или, говоря другими словами, кодовых таблиц.
Таблица кодировки – таблица,
описывающая соответствие между каждым
символом алфавита и его порядковым
номером.
Поскольку символы в алфавите
могут быть упорядочены разными способами, то для кодирования текста можно придумать и
использовать разные таблицы кодировки, устанавливающие разные соответствия
между символами и числами.
Так, в одной из международных
таблиц кодировки компьютерного алфавита пробелу соответствует порядковый номер
32, знаку «!» — порядковый номер 33, цифре «0» — порядковый номер 48, цифре «1»
— порядковый номер 49, строчной английской букве «a» — порядковый номер 97, а строчной
английской букве «b» —
порядковый номер 98 и т.д. Таким образом, все символы и их номера оказываются
упорядоченными. Поэтому отдельные символы (буквы, цифры, знаки препинания), а
значит, и составленные из них слова текста компьютер может автоматически
сортировать, сравнивая порядковые номера символов (меньше, больше или равно).
Запись текста, как и запись числа,
может содержать цифры (например, номер телефона, математическая или химическая
формула, ответ к задаче). Однако, в отличие от числовых данных, которые можно
сравнивать и с которыми можно выполнять арифметические операции, символы можно
только сравнивать.
Поскольку информация в компьютере
представлена в виде последовательности нулей и единиц, то порядковый номер
каждого символа компьютерного алфавита переводится в двоичный код по известным
правилам кодирования. При нажатии на клавишу клавиатуры с изображением символа
компьютер, используя таблицу кодировки, производит замену этого символа
соответствующим ему двоичным кодом. При выводе символа на экран двоичный код
порядкового номера заменяется изображением символа.
Количество двоичных разрядов,
необходимых для кодирования каждого символа, а значит, и количество битов
памяти, требуемых для хранения символа, зависит от мощности компьютерного
алфавита. Мощность компьютерного алфавита, который содержит все символы,
расположенные на клавиатуре компьютера (прописные и строчные буквы английского
и русского алфавитов, цифры, различные знаки), больше чем 128 символов (128=27),
но меньше чем 256 (256=28). Поэтому для кодирования каждого символа
такого компьютерного алфавита достаточно 8 двоичных знаков, и информационные
вес одного символа составляет 8 бит, равных 1 байту. Значит, для хранения в
компьютере одного из 256 символов компьютерного алфавита необходим 1 байт памяти.
Получившая широкое
распространение таблица кодировки, в которой каждому символу компьютерного
алфавита ставится в соответствие 8-разрядный двоичный код, называется кодовой таблицей ASCII (American Standard Code for Information Interchange –
американский стандартный код для обмена информацией). С помощью кодовой таблицы
ASCII можно закодировать всего 256 символов: цифры,
некоторые знаки, алфавиты только двух естественных языков (например, английский
и русский алфавиты). Поскольку существует множество других естественных языков,
а английский язык используется в качестве международного языка, то кодовая
таблица ASCII
разделяется на две равные части – основную (стандартную) и дополнительную (альтернативную).
Основная часть таблицы используется для кодирования букв английского алфавита,
цифр и других общепринятых знаков. Дополнительная часть таблицы используется
для кодирования символов одного из национальных алфавитов (например, русского
алфавита).
Содержание основной части
кодового алфавита таблицы ASCII
не меняется для разных стран и компьютеров. Каждому символу основной части
таблицы ставится в соответствие порядковый номер от 0 до 127, который
соответствует 8-разрядному двоичному коду от 00000000 до 01111111 или
шестнадцатеричному коду от 00 до 7F.

В кодовой таблице ASCII:
- Порядковые номера с 0 по 31 соответствуют символам
управляющих операций (переходу на следующую строку, удалению символа, табуляции
и другим операциям); - Порядковые номера с 32 по 63 соответствуют пробелу, знакам
препинания, скобкам, знакам арифметических операций, цифрам и некоторым другим
символам; - Порядковые номера с 64 по 95 соответствуют заглавным буквам
английского алфавита и некоторым другим символам; - Порядковые номера с 96 по 127 соответствуют строчным буквам
английского алфавита и некоторым другим символам.
ПРИМЕР. Определить объем памяти, необходимый для хранения
слова «Hello», и
закодировать это слово для хранения в памяти компьютера.
Решение.
1)Определим объем памяти для хранения слова. Поскольку для
хранения каждого символа из 256-символьного алфавита необходим 1 байт памяти (2i = 256, i = 8 юит = 1 байт), то для
хранения пяти символов, составляющих слово «Hello», необходимо 5 байт памяти (I=i*k=1*5=5
байт).
2)Определим порядковые номера символов в основной части
таблицы кодировки ASCII. Пяти английским буквам, входящим
в слово «Hello»,
соответствуют порядковые номера: 72, 101, 108, 108, 111.
3)Определим 8-разрядные двоичные коды символов. Поскольку в
памяти компьютера хранятся двоичные коды, переведем каждое десятичное число в
двоичное число:
7210=10010002, 10110=11001012,
10810=11011002, 10810=11011002,
11110=11011112.
Зная, что каждому символу должен соответствовать 8-разрядный
двоичный код, дополним каждое двоичное число незначащими нулями до 8 цифр.
Получим последовательность двоичных кодов пяти символов:
01001000 01100101 01101100
01101100 01101111.
Ответ. Для хранения слова «Hello» необходимо 5 байтов памяти, в
битах которых необходимо сохранить двоичный код: 01001000 01100101
01101100 01101100 01101111.
Дополнительная часть кодовой таблицы ASCII может содержать разные наборы
символов: буквы национального алфавита, научные и другие дополнительные
символы. Каждому такому символу ставится в соответствие порядковый номер от 128
до 255, который соответствует 8-разрядному двоичному коду от 10000000 до
11111111 или шестнадцатеричному коду от 80 до FF.
Существует несколько вариантов дополнительной части кодовой
таблицы ASCII для кодирования символов русского алфавита. Например,
кодировка Windows-125,
используемая в операционной системе MS Windows, а также кодировка КОИ-8, используемая в операционной
системе Unix и при передаче текстовой информации с помощью компьютерных
сетей.
Эти кодировки отличаются последовательностью расположения
символов. В кодировке Windows-125
в алфавитном порядке вначале расположены прописные русские буквы, а затем
строчные русские буквы. В кодировке КОИ-8 последовательность букв другая,
следовательно, и кодирование букв другое. Поэтому тексты, закодированные с
использованием одной кодировки, будут неправильно отображаться при
декодировании с использованием другой кодировки. Например, слово «Привет»,
сохраненное в памяти компьютера с использованием кодировки Windows-125, будет выведено на экран
монитора как «оПХБЕР» с использованием кодировки КОИ-8. Для перекодировки
символов существуют программы-конвертеры, которые входят в состав операционных
систем и приложений.


Для того, чтобы решить проблему стандартизации кодирования
букв национальных алфавитов, была разработана таблица кодировки Unicode, в которой каждому
символу компьютерного алфавита ставится в соответствие 16-разрядный двоичный
код. Это дает возможность закодировать 65536 (216 = 65536) различных
символов. Такая таблица кодировки позволяет разместить алфавиты языков
большинства народов мира. Однако при этом коды символов становятся вдвое длиннее,
что требует дополнительных ресурсов компьютера.
Таким образом, аналогично числам символы могут быть
представлены в виде последовательности нулей и единиц. Существующие правила
кодирования символов позволяют сопоставлять символы с числами и, наоборот,
определять символ, зная число. Кодирование символов, их замена числами и запись
с помощью двоичных кодов дает много преимуществ, в числе которых автоматизация
поиска, сравнения и замены символов, возможность хранения, обработки и передачи
текстов с помощью компьютерной техники.
Информатика, 10 класс. Урок № 14.
Тема — Кодирование текстовой информации
Цели и задачи урока:
— познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
— познакомиться со способом определения информационного объема текстового сообщения;
— познакомиться с алгоритмом Хаффмана.

Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
N=2i, где
N — это количество вариантов,
i — это количество бит, не обходимых для кодирования.
Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.

N=2i, где N — кол-во возможных вариантов
i — кол-во бит, потребуемых для кодирования
Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.

И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.


Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.

Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:

Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:

Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.

АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:

У вас должно получиться:

Шаг 2.
Расположите буквы в порядке возрастания их частоты.

Шаг 3.
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:

Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:

Шаг 5.
Объединяем символ e и символ cd в ветку дерева:
d
C

Шаг 6.
Сортируем:

Шаг 7.

Шаг 8.
Сортируем:

Шаг 9.

Шаг 10.
Сортируем:

Шаг 11.

Шаг 12.
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.

Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
Тогда код для каждой буквы будет:


Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
| M | O | S | C | O | W |
| 1001101 | 1001111 | 1010011 | 1000011 | 1001111 | 1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
| К | О | М | П | Ь | Ю | Т | Е | Р |
| 234 | 206 | 204 | 239 | 252 | 254 | 242 | 197 | 208 |
Ответ: 234206204239252254242197208
Задание №3
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:





Давайте все левые ветви обозначим «1», а правые – «0»

Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110