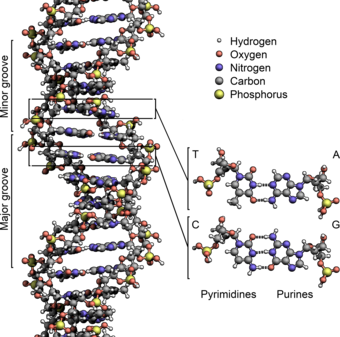
Deoxyribonucleic acid (;[1] DNA) is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.
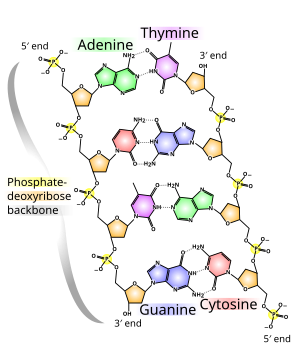
The two DNA strands are known as polynucleotides as they are composed of simpler monomeric units called nucleotides.[2][3] Each nucleotide is composed of one of four nitrogen-containing nucleobases (cytosine [C], guanine [G], adenine [A] or thymine [T]), a sugar called deoxyribose, and a phosphate group. The nucleotides are joined to one another in a chain by covalent bonds (known as the phosphodiester linkage) between the sugar of one nucleotide and the phosphate of the next, resulting in an alternating sugar-phosphate backbone. The nitrogenous bases of the two separate polynucleotide strands are bound together, according to base pairing rules (A with T and C with G), with hydrogen bonds to make double-stranded DNA. The complementary nitrogenous bases are divided into two groups, pyrimidines and purines. In DNA, the pyrimidines are thymine and cytosine; the purines are adenine and guanine.
Both strands of double-stranded DNA store the same biological information. This information is replicated when the two strands separate. A large part of DNA (more than 98% for humans) is non-coding, meaning that these sections do not serve as patterns for protein sequences. The two strands of DNA run in opposite directions to each other and are thus antiparallel. Attached to each sugar is one of four types of nucleobases (or bases). It is the sequence of these four nucleobases along the backbone that encodes genetic information. RNA strands are created using DNA strands as a template in a process called transcription, where DNA bases are exchanged for their corresponding bases except in the case of thymine (T), for which RNA substitutes uracil (U).[4] Under the genetic code, these RNA strands specify the sequence of amino acids within proteins in a process called translation.
Within eukaryotic cells, DNA is organized into long structures called chromosomes. Before typical cell division, these chromosomes are duplicated in the process of DNA replication, providing a complete set of chromosomes for each daughter cell. Eukaryotic organisms (animals, plants, fungi and protists) store most of their DNA inside the cell nucleus as nuclear DNA, and some in the mitochondria as mitochondrial DNA or in chloroplasts as chloroplast DNA.[5] In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm, in circular chromosomes. Within eukaryotic chromosomes, chromatin proteins, such as histones, compact and organize DNA. These compacting structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed.
Properties
Chemical structure of DNA; hydrogen bonds shown as dotted lines. Each end of the double helix has an exposed 5′ phosphate on one strand and an exposed 3′ hydroxyl group (—OH) on the other.
DNA is a long polymer made from repeating units called nucleotides.[6][7] The structure of DNA is dynamic along its length, being capable of coiling into tight loops and other shapes.[8] In all species it is composed of two helical chains, bound to each other by hydrogen bonds. Both chains are coiled around the same axis, and have the same pitch of 34 ångströms (3.4 nm). The pair of chains have a radius of 10 Å (1.0 nm).[9] According to another study, when measured in a different solution, the DNA chain measured 22–26 Å (2.2–2.6 nm) wide, and one nucleotide unit measured 3.3 Å (0.33 nm) long.[10]
DNA does not usually exist as a single strand, but instead as a pair of strands that are held tightly together.[9][11] These two long strands coil around each other, in the shape of a double helix. The nucleotide contains both a segment of the backbone of the molecule (which holds the chain together) and a nucleobase (which interacts with the other DNA strand in the helix). A nucleobase linked to a sugar is called a nucleoside, and a base linked to a sugar and to one or more phosphate groups is called a nucleotide. A biopolymer comprising multiple linked nucleotides (as in DNA) is called a polynucleotide.[12]
The backbone of the DNA strand is made from alternating phosphate and sugar groups.[13] The sugar in DNA is 2-deoxyribose, which is a pentose (five-carbon) sugar. The sugars are joined by phosphate groups that form phosphodiester bonds between the third and fifth carbon atoms of adjacent sugar rings. These are known as the 3′-end (three prime end), and 5′-end (five prime end) carbons, the prime symbol being used to distinguish these carbon atoms from those of the base to which the deoxyribose forms a glycosidic bond.[11]
Therefore, any DNA strand normally has one end at which there is a phosphate group attached to the 5′ carbon of a ribose (the 5′ phosphoryl) and another end at which there is a free hydroxyl group attached to the 3′ carbon of a ribose (the 3′ hydroxyl). The orientation of the 3′ and 5′ carbons along the sugar-phosphate backbone confers directionality (sometimes called polarity) to each DNA strand. In a nucleic acid double helix, the direction of the nucleotides in one strand is opposite to their direction in the other strand: the strands are antiparallel. The asymmetric ends of DNA strands are said to have a directionality of five prime end (5′ ), and three prime end (3′), with the 5′ end having a terminal phosphate group and the 3′ end a terminal hydroxyl group. One major difference between DNA and RNA is the sugar, with the 2-deoxyribose in DNA being replaced by the related pentose sugar ribose in RNA.[11]
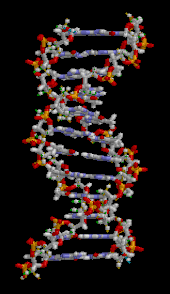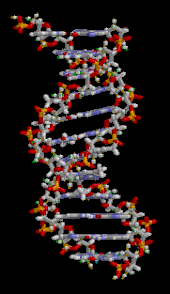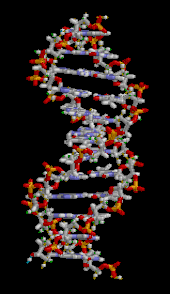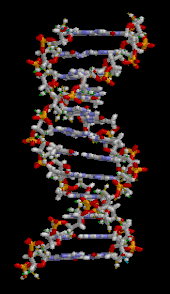
A section of DNA. The bases lie horizontally between the two spiraling strands[14] (animated version).
The DNA double helix is stabilized primarily by two forces: hydrogen bonds between nucleotides and base-stacking interactions among aromatic nucleobases.[15] The four bases found in DNA are adenine (A), cytosine (C), guanine (G) and thymine (T). These four bases are attached to the sugar-phosphate to form the complete nucleotide, as shown for adenosine monophosphate. Adenine pairs with thymine and guanine pairs with cytosine, forming A-T and G-C base pairs.[16][17]
Nucleobase classification
The nucleobases are classified into two types: the purines, A and G, which are fused five- and six-membered heterocyclic compounds, and the pyrimidines, the six-membered rings C and T.[11] A fifth pyrimidine nucleobase, uracil (U), usually takes the place of thymine in RNA and differs from thymine by lacking a methyl group on its ring. In addition to RNA and DNA, many artificial nucleic acid analogues have been created to study the properties of nucleic acids, or for use in biotechnology.[18]
Non-canonical bases
Modified bases occur in DNA. The first of these recognized was 5-methylcytosine, which was found in the genome of Mycobacterium tuberculosis in 1925.[19] The reason for the presence of these noncanonical bases in bacterial viruses (bacteriophages) is to avoid the restriction enzymes present in bacteria. This enzyme system acts at least in part as a molecular immune system protecting bacteria from infection by viruses.[20] Modifications of the bases cytosine and adenine, the more common and modified DNA bases, play vital roles in the epigenetic control of gene expression in plants and animals.[21]
A number of noncanonical bases are known to occur in DNA.[22] Most of these are modifications of the canonical bases plus uracil.
- Modified Adenosine
- N6-carbamoyl-methyladenine
- N6-methyadenine
- Modified Guanine
- 7-Deazaguanine
- 7-Methylguanine
- Modified Cytosine
- N4-Methylcytosine
- 5-Carboxylcytosine
- 5-Formylcytosine
- 5-Glycosylhydroxymethylcytosine
- 5-Hydroxycytosine
- 5-Methylcytosine
- Modified Thymidine
- α-Glutamythymidine
- α-Putrescinylthymine
- Uracil and modifications
- Base J
- Uracil
- 5-Dihydroxypentauracil
- 5-Hydroxymethyldeoxyuracil
- Others
- Deoxyarchaeosine
- 2,6-Diaminopurine (2-Aminoadenine)
Grooves
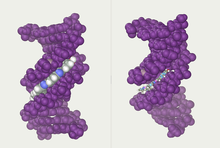
DNA major and minor grooves. The latter is a binding site for the Hoechst stain dye 33258.
Twin helical strands form the DNA backbone. Another double helix may be found tracing the spaces, or grooves, between the strands. These voids are adjacent to the base pairs and may provide a binding site. As the strands are not symmetrically located with respect to each other, the grooves are unequally sized. The major groove is 22 ångströms (2.2 nm) wide, while the minor groove is 12 Å (1.2 nm) in width.[23] Due to the larger width of the major groove, the edges of the bases are more accessible in the major groove than in the minor groove. As a result, proteins such as transcription factors that can bind to specific sequences in double-stranded DNA usually make contact with the sides of the bases exposed in the major groove.[24] This situation varies in unusual conformations of DNA within the cell (see below), but the major and minor grooves are always named to reflect the differences in width that would be seen if the DNA was twisted back into the ordinary B form.
Base pairing

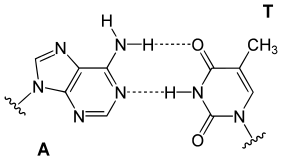
Top, a GC base pair with three hydrogen bonds. Bottom, an AT base pair with two hydrogen bonds. Non-covalent hydrogen bonds between the pairs are shown as dashed lines.
In a DNA double helix, each type of nucleobase on one strand bonds with just one type of nucleobase on the other strand. This is called complementary base pairing. Purines form hydrogen bonds to pyrimidines, with adenine bonding only to thymine in two hydrogen bonds, and cytosine bonding only to guanine in three hydrogen bonds. This arrangement of two nucleotides binding together across the double helix (from six-carbon ring to six-carbon ring) is called a Watson-Crick base pair. DNA with high GC-content is more stable than DNA with low GC-content. A Hoogsteen base pair (hydrogen bonding the 6-carbon ring to the 5-carbon ring) is a rare variation of base-pairing.[25] As hydrogen bonds are not covalent, they can be broken and rejoined relatively easily. The two strands of DNA in a double helix can thus be pulled apart like a zipper, either by a mechanical force or high temperature.[26] As a result of this base pair complementarity, all the information in the double-stranded sequence of a DNA helix is duplicated on each strand, which is vital in DNA replication. This reversible and specific interaction between complementary base pairs is critical for all the functions of DNA in organisms.[7]
ssDNA vs. dsDNA
As noted above, most DNA molecules are actually two polymer strands, bound together in a helical fashion by noncovalent bonds; this double-stranded (dsDNA) structure is maintained largely by the intrastrand base stacking interactions, which are strongest for G,C stacks. The two strands can come apart—a process known as melting—to form two single-stranded DNA (ssDNA) molecules. Melting occurs at high temperatures, low salt and high pH (low pH also melts DNA, but since DNA is unstable due to acid depurination, low pH is rarely used).
The stability of the dsDNA form depends not only on the GC-content (% G,C basepairs) but also on sequence (since stacking is sequence specific) and also length (longer molecules are more stable). The stability can be measured in various ways; a common way is the melting temperature (also called Tm value), which is the temperature at which 50% of the double-strand molecules are converted to single-strand molecules; melting temperature is dependent on ionic strength and the concentration of DNA. As a result, it is both the percentage of GC base pairs and the overall length of a DNA double helix that determines the strength of the association between the two strands of DNA. Long DNA helices with a high GC-content have more strongly interacting strands, while short helices with high AT content have more weakly interacting strands.[27] In biology, parts of the DNA double helix that need to separate easily, such as the TATAAT Pribnow box in some promoters, tend to have a high AT content, making the strands easier to pull apart.[28]
In the laboratory, the strength of this interaction can be measured by finding the melting temperature Tm necessary to break half of the hydrogen bonds. When all the base pairs in a DNA double helix melt, the strands separate and exist in solution as two entirely independent molecules. These single-stranded DNA molecules have no single common shape, but some conformations are more stable than others.[29]
Amount

In humans, the total female diploid nuclear genome per cell extends for 6.37 Gigabase pairs (Gbp), is 208.23 cm long and weighs 6.51 picograms (pg).[30] Male values are 6.27 Gbp, 205.00 cm, 6.41 pg.[30] Each DNA polymer can contain hundreds of millions of nucleotides, such as in chromosome 1. Chromosome 1 is the largest human chromosome with approximately 220 million base pairs, and would be 85 mm long if straightened.[31]
In eukaryotes, in addition to nuclear DNA, there is also mitochondrial DNA (mtDNA) which encodes certain proteins used by the mitochondria. The mtDNA is usually relatively small in comparison to the nuclear DNA. For example, the human mitochondrial DNA forms closed circular molecules, each of which contains 16,569[32][33] DNA base pairs,[34] with each such molecule normally containing a full set of the mitochondrial genes. Each human mitochondrion contains, on average, approximately 5 such mtDNA molecules.[34] Each human cell contains approximately 100 mitochondria, giving a total number of mtDNA molecules per human cell of approximately 500.[34] However, the amount of mitochondria per cell also varies by cell type, and an egg cell can contain 100,000 mitochondria, corresponding to up to 1,500,000 copies of the mitochondrial genome (constituting up to 90% of the DNA of the cell).[35]
Sense and antisense
A DNA sequence is called a «sense» sequence if it is the same as that of a messenger RNA copy that is translated into protein.[36] The sequence on the opposite strand is called the «antisense» sequence. Both sense and antisense sequences can exist on different parts of the same strand of DNA (i.e. both strands can contain both sense and antisense sequences). In both prokaryotes and eukaryotes, antisense RNA sequences are produced, but the functions of these RNAs are not entirely clear.[37] One proposal is that antisense RNAs are involved in regulating gene expression through RNA-RNA base pairing.[38]
A few DNA sequences in prokaryotes and eukaryotes, and more in plasmids and viruses, blur the distinction between sense and antisense strands by having overlapping genes.[39] In these cases, some DNA sequences do double duty, encoding one protein when read along one strand, and a second protein when read in the opposite direction along the other strand. In bacteria, this overlap may be involved in the regulation of gene transcription,[40] while in viruses, overlapping genes increase the amount of information that can be encoded within the small viral genome.[41]
Supercoiling
DNA can be twisted like a rope in a process called DNA supercoiling. With DNA in its «relaxed» state, a strand usually circles the axis of the double helix once every 10.4 base pairs, but if the DNA is twisted the strands become more tightly or more loosely wound.[42] If the DNA is twisted in the direction of the helix, this is positive supercoiling, and the bases are held more tightly together. If they are twisted in the opposite direction, this is negative supercoiling, and the bases come apart more easily. In nature, most DNA has slight negative supercoiling that is introduced by enzymes called topoisomerases.[43] These enzymes are also needed to relieve the twisting stresses introduced into DNA strands during processes such as transcription and DNA replication.[44]
Alternative DNA structures
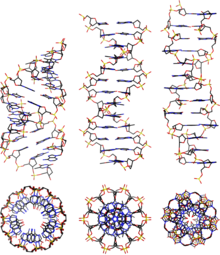
From left to right, the structures of A, B and Z-DNA
DNA exists in many possible conformations that include A-DNA, B-DNA, and Z-DNA forms, although only B-DNA and Z-DNA have been directly observed in functional organisms.[13] The conformation that DNA adopts depends on the hydration level, DNA sequence, the amount and direction of supercoiling, chemical modifications of the bases, the type and concentration of metal ions, and the presence of polyamines in solution.[45]
The first published reports of A-DNA X-ray diffraction patterns—and also B-DNA—used analyses based on Patterson functions that provided only a limited amount of structural information for oriented fibers of DNA.[46][47] An alternative analysis was proposed by Wilkins et al. in 1953 for the in vivo B-DNA X-ray diffraction-scattering patterns of highly hydrated DNA fibers in terms of squares of Bessel functions.[48] In the same journal, James Watson and Francis Crick presented their molecular modeling analysis of the DNA X-ray diffraction patterns to suggest that the structure was a double helix.[9]
Although the B-DNA form is most common under the conditions found in cells,[49] it is not a well-defined conformation but a family of related DNA conformations[50] that occur at the high hydration levels present in cells. Their corresponding X-ray diffraction and scattering patterns are characteristic of molecular paracrystals with a significant degree of disorder.[51][52]
Compared to B-DNA, the A-DNA form is a wider right-handed spiral, with a shallow, wide minor groove and a narrower, deeper major groove. The A form occurs under non-physiological conditions in partly dehydrated samples of DNA, while in the cell it may be produced in hybrid pairings of DNA and RNA strands, and in enzyme-DNA complexes.[53][54] Segments of DNA where the bases have been chemically modified by methylation may undergo a larger change in conformation and adopt the Z form. Here, the strands turn about the helical axis in a left-handed spiral, the opposite of the more common B form.[55] These unusual structures can be recognized by specific Z-DNA binding proteins and may be involved in the regulation of transcription.[56]
Alternative DNA chemistry
For many years, exobiologists have proposed the existence of a shadow biosphere, a postulated microbial biosphere of Earth that uses radically different biochemical and molecular processes than currently known life. One of the proposals was the existence of lifeforms that use arsenic instead of phosphorus in DNA. A report in 2010 of the possibility in the bacterium GFAJ-1 was announced,[57][58] though the research was disputed,[58][59] and evidence suggests the bacterium actively prevents the incorporation of arsenic into the DNA backbone and other biomolecules.[60]
Quadruplex structures
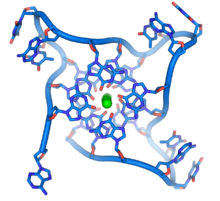
DNA quadruplex formed by telomere repeats. The looped conformation of the DNA backbone is very different from the typical DNA helix. The green spheres in the center represent potassium ions.[61]
At the ends of the linear chromosomes are specialized regions of DNA called telomeres. The main function of these regions is to allow the cell to replicate chromosome ends using the enzyme telomerase, as the enzymes that normally replicate DNA cannot copy the extreme 3′ ends of chromosomes.[62] These specialized chromosome caps also help protect the DNA ends, and stop the DNA repair systems in the cell from treating them as damage to be corrected.[63] In human cells, telomeres are usually lengths of single-stranded DNA containing several thousand repeats of a simple TTAGGG sequence.[64]
These guanine-rich sequences may stabilize chromosome ends by forming structures of stacked sets of four-base units, rather than the usual base pairs found in other DNA molecules. Here, four guanine bases, known as a guanine tetrad, form a flat plate. These flat four-base units then stack on top of each other to form a stable G-quadruplex structure.[65] These structures are stabilized by hydrogen bonding between the edges of the bases and chelation of a metal ion in the centre of each four-base unit.[66] Other structures can also be formed, with the central set of four bases coming from either a single strand folded around the bases, or several different parallel strands, each contributing one base to the central structure.
In addition to these stacked structures, telomeres also form large loop structures called telomere loops, or T-loops. Here, the single-stranded DNA curls around in a long circle stabilized by telomere-binding proteins.[67] At the very end of the T-loop, the single-stranded telomere DNA is held onto a region of double-stranded DNA by the telomere strand disrupting the double-helical DNA and base pairing to one of the two strands. This triple-stranded structure is called a displacement loop or D-loop.[65]
Branched DNA can form networks containing multiple branches.
Branched DNA
In DNA, fraying occurs when non-complementary regions exist at the end of an otherwise complementary double-strand of DNA. However, branched DNA can occur if a third strand of DNA is introduced and contains adjoining regions able to hybridize with the frayed regions of the pre-existing double-strand. Although the simplest example of branched DNA involves only three strands of DNA, complexes involving additional strands and multiple branches are also possible.[68] Branched DNA can be used in nanotechnology to construct geometric shapes, see the section on uses in technology below.
Artificial bases
Several artificial nucleobases have been synthesized, and successfully incorporated in the eight-base DNA analogue named Hachimoji DNA. Dubbed S, B, P, and Z, these artificial bases are capable of bonding with each other in a predictable way (S–B and P–Z), maintain the double helix structure of DNA, and be transcribed to RNA. Their existence could be seen as an indication that there is nothing special about the four natural nucleobases that evolved on Earth.[69][70] On the other hand, DNA is tightly related to RNA which does not only act as a transcript of DNA but also performs as moleular machines many tasks in cells. For this purpose it has to fold into a structure. It has been shown that to allow to create all possible structures at least four bases are required for the corresponding RNA,[71] while a higher number is also possible but this would be against the natural principle of least effort.
Acidity
The phosphate groups of DNA give it similar acidic properties to phosphoric acid and it can be considered as a strong acid. It will be fully ionized at a normal cellular pH, releasing protons which leave behind negative charges on the phosphate groups. These negative charges protect DNA from breakdown by hydrolysis by repelling nucleophiles which could hydrolyze it.[72]
Macroscopic appearance

Impure DNA extracted from an orange
Pure DNA extracted from cells forms white, stringy clumps.[73]
Chemical modifications and altered DNA packaging
Structure of cytosine with and without the 5-methyl group. Deamination converts 5-methylcytosine into thymine.
Base modifications and DNA packaging
The expression of genes is influenced by how the DNA is packaged in chromosomes, in a structure called chromatin. Base modifications can be involved in packaging, with regions that have low or no gene expression usually containing high levels of methylation of cytosine bases. DNA packaging and its influence on gene expression can also occur by covalent modifications of the histone protein core around which DNA is wrapped in the chromatin structure or else by remodeling carried out by chromatin remodeling complexes (see Chromatin remodeling). There is, further, crosstalk between DNA methylation and histone modification, so they can coordinately affect chromatin and gene expression.[74]
For one example, cytosine methylation produces 5-methylcytosine, which is important for X-inactivation of chromosomes.[75] The average level of methylation varies between organisms—the worm Caenorhabditis elegans lacks cytosine methylation, while vertebrates have higher levels, with up to 1% of their DNA containing 5-methylcytosine.[76] Despite the importance of 5-methylcytosine, it can deaminate to leave a thymine base, so methylated cytosines are particularly prone to mutations.[77] Other base modifications include adenine methylation in bacteria, the presence of 5-hydroxymethylcytosine in the brain,[78] and the glycosylation of uracil to produce the «J-base» in kinetoplastids.[79][80]
Damage
DNA can be damaged by many sorts of mutagens, which change the DNA sequence. Mutagens include oxidizing agents, alkylating agents and also high-energy electromagnetic radiation such as ultraviolet light and X-rays. The type of DNA damage produced depends on the type of mutagen. For example, UV light can damage DNA by producing thymine dimers, which are cross-links between pyrimidine bases.[82] On the other hand, oxidants such as free radicals or hydrogen peroxide produce multiple forms of damage, including base modifications, particularly of guanosine, and double-strand breaks.[83] A typical human cell contains about 150,000 bases that have suffered oxidative damage.[84] Of these oxidative lesions, the most dangerous are double-strand breaks, as these are difficult to repair and can produce point mutations, insertions, deletions from the DNA sequence, and chromosomal translocations.[85] These mutations can cause cancer. Because of inherent limits in the DNA repair mechanisms, if humans lived long enough, they would all eventually develop cancer.[86][87] DNA damages that are naturally occurring, due to normal cellular processes that produce reactive oxygen species, the hydrolytic activities of cellular water, etc., also occur frequently. Although most of these damages are repaired, in any cell some DNA damage may remain despite the action of repair processes. These remaining DNA damages accumulate with age in mammalian postmitotic tissues. This accumulation appears to be an important underlying cause of aging.[88][89][90]
Many mutagens fit into the space between two adjacent base pairs, this is called intercalation. Most intercalators are aromatic and planar molecules; examples include ethidium bromide, acridines, daunomycin, and doxorubicin. For an intercalator to fit between base pairs, the bases must separate, distorting the DNA strands by unwinding of the double helix. This inhibits both transcription and DNA replication, causing toxicity and mutations.[91] As a result, DNA intercalators may be carcinogens, and in the case of thalidomide, a teratogen.[92] Others such as benzo[a]pyrene diol epoxide and aflatoxin form DNA adducts that induce errors in replication.[93] Nevertheless, due to their ability to inhibit DNA transcription and replication, other similar toxins are also used in chemotherapy to inhibit rapidly growing cancer cells.[94]
Biological functions
Location of eukaryote nuclear DNA within the chromosomes
DNA usually occurs as linear chromosomes in eukaryotes, and circular chromosomes in prokaryotes. The set of chromosomes in a cell makes up its genome; the human genome has approximately 3 billion base pairs of DNA arranged into 46 chromosomes.[95] The information carried by DNA is held in the sequence of pieces of DNA called genes. Transmission of genetic information in genes is achieved via complementary base pairing. For example, in transcription, when a cell uses the information in a gene, the DNA sequence is copied into a complementary RNA sequence through the attraction between the DNA and the correct RNA nucleotides. Usually, this RNA copy is then used to make a matching protein sequence in a process called translation, which depends on the same interaction between RNA nucleotides. In an alternative fashion, a cell may copy its genetic information in a process called DNA replication. The details of these functions are covered in other articles; here the focus is on the interactions between DNA and other molecules that mediate the function of the genome.
Genes and genomes
Genomic DNA is tightly and orderly packed in the process called DNA condensation, to fit the small available volumes of the cell. In eukaryotes, DNA is located in the cell nucleus, with small amounts in mitochondria and chloroplasts. In prokaryotes, the DNA is held within an irregularly shaped body in the cytoplasm called the nucleoid.[96] The genetic information in a genome is held within genes, and the complete set of this information in an organism is called its genotype. A gene is a unit of heredity and is a region of DNA that influences a particular characteristic in an organism. Genes contain an open reading frame that can be transcribed, and regulatory sequences such as promoters and enhancers, which control transcription of the open reading frame.
In many species, only a small fraction of the total sequence of the genome encodes protein. For example, only about 1.5% of the human genome consists of protein-coding exons, with over 50% of human DNA consisting of non-coding repetitive sequences.[97] The reasons for the presence of so much noncoding DNA in eukaryotic genomes and the extraordinary differences in genome size, or C-value, among species, represent a long-standing puzzle known as the «C-value enigma».[98] However, some DNA sequences that do not code protein may still encode functional non-coding RNA molecules, which are involved in the regulation of gene expression.[99]

Some noncoding DNA sequences play structural roles in chromosomes. Telomeres and centromeres typically contain few genes but are important for the function and stability of chromosomes.[63][101] An abundant form of noncoding DNA in humans are pseudogenes, which are copies of genes that have been disabled by mutation.[102] These sequences are usually just molecular fossils, although they can occasionally serve as raw genetic material for the creation of new genes through the process of gene duplication and divergence.[103]
Transcription and translation
A gene is a sequence of DNA that contains genetic information and can influence the phenotype of an organism. Within a gene, the sequence of bases along a DNA strand defines a messenger RNA sequence, which then defines one or more protein sequences. The relationship between the nucleotide sequences of genes and the amino-acid sequences of proteins is determined by the rules of translation, known collectively as the genetic code. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (e.g. ACT, CAG, TTT).
In transcription, the codons of a gene are copied into messenger RNA by RNA polymerase. This RNA copy is then decoded by a ribosome that reads the RNA sequence by base-pairing the messenger RNA to transfer RNA, which carries amino acids. Since there are 4 bases in 3-letter combinations, there are 64 possible codons (43 combinations). These encode the twenty standard amino acids, giving most amino acids more than one possible codon. There are also three ‘stop’ or ‘nonsense’ codons signifying the end of the coding region; these are the TAG, TAA, and TGA codons, (UAG, UAA, and UGA on the mRNA).
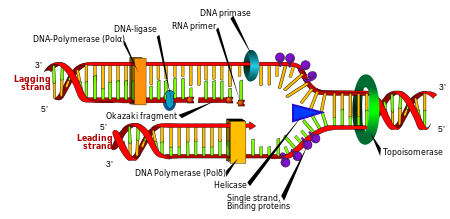
Replication
Cell division is essential for an organism to grow, but, when a cell divides, it must replicate the DNA in its genome so that the two daughter cells have the same genetic information as their parent. The double-stranded structure of DNA provides a simple mechanism for DNA replication. Here, the two strands are separated and then each strand’s complementary DNA sequence is recreated by an enzyme called DNA polymerase. This enzyme makes the complementary strand by finding the correct base through complementary base pairing and bonding it onto the original strand. As DNA polymerases can only extend a DNA strand in a 5′ to 3′ direction, different mechanisms are used to copy the antiparallel strands of the double helix.[104] In this way, the base on the old strand dictates which base appears on the new strand, and the cell ends up with a perfect copy of its DNA.
Naked extracellular DNA (eDNA), most of it released by cell death, is nearly ubiquitous in the environment. Its concentration in soil may be as high as 2 μg/L, and its concentration in natural aquatic environments may be as high at 88 μg/L.[105] Various possible functions have been proposed for eDNA: it may be involved in horizontal gene transfer;[106] it may provide nutrients;[107] and it may act as a buffer to recruit or titrate ions or antibiotics.[108] Extracellular DNA acts as a functional extracellular matrix component in the biofilms of several bacterial species. It may act as a recognition factor to regulate the attachment and dispersal of specific cell types in the biofilm;[109] it may contribute to biofilm formation;[110] and it may contribute to the biofilm’s physical strength and resistance to biological stress.[111]
Cell-free fetal DNA is found in the blood of the mother, and can be sequenced to determine a great deal of information about the developing fetus.[112]
Under the name of environmental DNA eDNA has seen increased use in the natural sciences as a survey tool for ecology, monitoring the movements and presence of species in water, air, or on land, and assessing an area’s biodiversity.[113][114]
Neutrophil extracellular traps (NETs) are networks of extracellular fibers, primarily composed of DNA, which allow neutrophils, a type of white blood cell, to kill extracellular pathogens while minimizing damage to the host cells.
Interactions with proteins
All the functions of DNA depend on interactions with proteins. These protein interactions can be non-specific, or the protein can bind specifically to a single DNA sequence. Enzymes can also bind to DNA and of these, the polymerases that copy the DNA base sequence in transcription and DNA replication are particularly important.
DNA-binding proteins

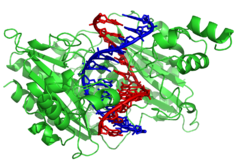
Interaction of DNA (in orange) with histones (in blue). These proteins’ basic amino acids bind to the acidic phosphate groups on DNA.
Structural proteins that bind DNA are well-understood examples of non-specific DNA-protein interactions. Within chromosomes, DNA is held in complexes with structural proteins. These proteins organize the DNA into a compact structure called chromatin. In eukaryotes, this structure involves DNA binding to a complex of small basic proteins called histones, while in prokaryotes multiple types of proteins are involved.[115][116] The histones form a disk-shaped complex called a nucleosome, which contains two complete turns of double-stranded DNA wrapped around its surface. These non-specific interactions are formed through basic residues in the histones, making ionic bonds to the acidic sugar-phosphate backbone of the DNA, and are thus largely independent of the base sequence.[117] Chemical modifications of these basic amino acid residues include methylation, phosphorylation, and acetylation.[118] These chemical changes alter the strength of the interaction between the DNA and the histones, making the DNA more or less accessible to transcription factors and changing the rate of transcription.[119] Other non-specific DNA-binding proteins in chromatin include the high-mobility group proteins, which bind to bent or distorted DNA.[120] These proteins are important in bending arrays of nucleosomes and arranging them into the larger structures that make up chromosomes.[121]
A distinct group of DNA-binding proteins is the DNA-binding proteins that specifically bind single-stranded DNA. In humans, replication protein A is the best-understood member of this family and is used in processes where the double helix is separated, including DNA replication, recombination, and DNA repair.[122] These binding proteins seem to stabilize single-stranded DNA and protect it from forming stem-loops or being degraded by nucleases.

In contrast, other proteins have evolved to bind to particular DNA sequences. The most intensively studied of these are the various transcription factors, which are proteins that regulate transcription. Each transcription factor binds to one particular set of DNA sequences and activates or inhibits the transcription of genes that have these sequences close to their promoters. The transcription factors do this in two ways. Firstly, they can bind the RNA polymerase responsible for transcription, either directly or through other mediator proteins; this locates the polymerase at the promoter and allows it to begin transcription.[124] Alternatively, transcription factors can bind enzymes that modify the histones at the promoter. This changes the accessibility of the DNA template to the polymerase.[125]
As these DNA targets can occur throughout an organism’s genome, changes in the activity of one type of transcription factor can affect thousands of genes.[126] Consequently, these proteins are often the targets of the signal transduction processes that control responses to environmental changes or cellular differentiation and development. The specificity of these transcription factors’ interactions with DNA come from the proteins making multiple contacts to the edges of the DNA bases, allowing them to «read» the DNA sequence. Most of these base-interactions are made in the major groove, where the bases are most accessible.[24]
DNA-modifying enzymes
Nucleases and ligases
Nucleases are enzymes that cut DNA strands by catalyzing the hydrolysis of the phosphodiester bonds. Nucleases that hydrolyse nucleotides from the ends of DNA strands are called exonucleases, while endonucleases cut within strands. The most frequently used nucleases in molecular biology are the restriction endonucleases, which cut DNA at specific sequences. For instance, the EcoRV enzyme shown to the left recognizes the 6-base sequence 5′-GATATC-3′ and makes a cut at the horizontal line. In nature, these enzymes protect bacteria against phage infection by digesting the phage DNA when it enters the bacterial cell, acting as part of the restriction modification system.[128] In technology, these sequence-specific nucleases are used in molecular cloning and DNA fingerprinting.
Enzymes called DNA ligases can rejoin cut or broken DNA strands.[129] Ligases are particularly important in lagging strand DNA replication, as they join the short segments of DNA produced at the replication fork into a complete copy of the DNA template. They are also used in DNA repair and genetic recombination.[129]
Topoisomerases and helicases
Topoisomerases are enzymes with both nuclease and ligase activity. These proteins change the amount of supercoiling in DNA. Some of these enzymes work by cutting the DNA helix and allowing one section to rotate, thereby reducing its level of supercoiling; the enzyme then seals the DNA break.[43] Other types of these enzymes are capable of cutting one DNA helix and then passing a second strand of DNA through this break, before rejoining the helix.[130] Topoisomerases are required for many processes involving DNA, such as DNA replication and transcription.[44]
Helicases are proteins that are a type of molecular motor. They use the chemical energy in nucleoside triphosphates, predominantly adenosine triphosphate (ATP), to break hydrogen bonds between bases and unwind the DNA double helix into single strands.[131] These enzymes are essential for most processes where enzymes need to access the DNA bases.
Polymerases
Polymerases are enzymes that synthesize polynucleotide chains from nucleoside triphosphates. The sequence of their products is created based on existing polynucleotide chains—which are called templates. These enzymes function by repeatedly adding a nucleotide to the 3′ hydroxyl group at the end of the growing polynucleotide chain. As a consequence, all polymerases work in a 5′ to 3′ direction.[132] In the active site of these enzymes, the incoming nucleoside triphosphate base-pairs to the template: this allows polymerases to accurately synthesize the complementary strand of their template. Polymerases are classified according to the type of template that they use.
In DNA replication, DNA-dependent DNA polymerases make copies of DNA polynucleotide chains. To preserve biological information, it is essential that the sequence of bases in each copy are precisely complementary to the sequence of bases in the template strand. Many DNA polymerases have a proofreading activity. Here, the polymerase recognizes the occasional mistakes in the synthesis reaction by the lack of base pairing between the mismatched nucleotides. If a mismatch is detected, a 3′ to 5′ exonuclease activity is activated and the incorrect base removed.[133] In most organisms, DNA polymerases function in a large complex called the replisome that contains multiple accessory subunits, such as the DNA clamp or helicases.[134]
RNA-dependent DNA polymerases are a specialized class of polymerases that copy the sequence of an RNA strand into DNA. They include reverse transcriptase, which is a viral enzyme involved in the infection of cells by retroviruses, and telomerase, which is required for the replication of telomeres.[62][135] For example, HIV reverse transcriptase is an enzyme for AIDS virus replication.[135] Telomerase is an unusual polymerase because it contains its own RNA template as part of its structure. It synthesizes telomeres at the ends of chromosomes. Telomeres prevent fusion of the ends of neighboring chromosomes and protect chromosome ends from damage.[63]
Transcription is carried out by a DNA-dependent RNA polymerase that copies the sequence of a DNA strand into RNA. To begin transcribing a gene, the RNA polymerase binds to a sequence of DNA called a promoter and separates the DNA strands. It then copies the gene sequence into a messenger RNA transcript until it reaches a region of DNA called the terminator, where it halts and detaches from the DNA. As with human DNA-dependent DNA polymerases, RNA polymerase II, the enzyme that transcribes most of the genes in the human genome, operates as part of a large protein complex with multiple regulatory and accessory subunits.[136]
Genetic recombination
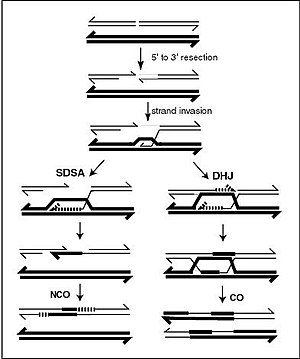
A current model of meiotic recombination, initiated by a double-strand break or gap, followed by pairing with an homologous chromosome and strand invasion to initiate the recombinational repair process. Repair of the gap can lead to crossover (CO) or non-crossover (NCO) of the flanking regions. CO recombination is thought to occur by the Double Holliday Junction (DHJ) model, illustrated on the right, above. NCO recombinants are thought to occur primarily by the Synthesis Dependent Strand Annealing (SDSA) model, illustrated on the left, above. Most recombination events appear to be the SDSA type.
A DNA helix usually does not interact with other segments of DNA, and in human cells, the different chromosomes even occupy separate areas in the nucleus called «chromosome territories».[138] This physical separation of different chromosomes is important for the ability of DNA to function as a stable repository for information, as one of the few times chromosomes interact is in chromosomal crossover which occurs during sexual reproduction, when genetic recombination occurs. Chromosomal crossover is when two DNA helices break, swap a section and then rejoin.
Recombination allows chromosomes to exchange genetic information and produces new combinations of genes, which increases the efficiency of natural selection and can be important in the rapid evolution of new proteins.[139] Genetic recombination can also be involved in DNA repair, particularly in the cell’s response to double-strand breaks.[140]
The most common form of chromosomal crossover is homologous recombination, where the two chromosomes involved share very similar sequences. Non-homologous recombination can be damaging to cells, as it can produce chromosomal translocations and genetic abnormalities. The recombination reaction is catalyzed by enzymes known as recombinases, such as RAD51.[141] The first step in recombination is a double-stranded break caused by either an endonuclease or damage to the DNA.[142] A series of steps catalyzed in part by the recombinase then leads to joining of the two helices by at least one Holliday junction, in which a segment of a single strand in each helix is annealed to the complementary strand in the other helix. The Holliday junction is a tetrahedral junction structure that can be moved along the pair of chromosomes, swapping one strand for another. The recombination reaction is then halted by cleavage of the junction and re-ligation of the released DNA.[143] Only strands of like polarity exchange DNA during recombination. There are two types of cleavage: east-west cleavage and north–south cleavage. The north–south cleavage nicks both strands of DNA, while the east–west cleavage has one strand of DNA intact. The formation of a Holliday junction during recombination makes it possible for genetic diversity, genes to exchange on chromosomes, and expression of wild-type viral genomes.
Evolution
DNA contains the genetic information that allows all forms of life to function, grow and reproduce. However, it is unclear how long in the 4-billion-year history of life DNA has performed this function, as it has been proposed that the earliest forms of life may have used RNA as their genetic material.[144][145] RNA may have acted as the central part of early cell metabolism as it can both transmit genetic information and carry out catalysis as part of ribozymes.[146] This ancient RNA world where nucleic acid would have been used for both catalysis and genetics may have influenced the evolution of the current genetic code based on four nucleotide bases. This would occur, since the number of different bases in such an organism is a trade-off between a small number of bases increasing replication accuracy and a large number of bases increasing the catalytic efficiency of ribozymes.[147] However, there is no direct evidence of ancient genetic systems, as recovery of DNA from most fossils is impossible because DNA survives in the environment for less than one million years, and slowly degrades into short fragments in solution.[148] Claims for older DNA have been made, most notably a report of the isolation of a viable bacterium from a salt crystal 250 million years old,[149] but these claims are controversial.[150][151]
Building blocks of DNA (adenine, guanine, and related organic molecules) may have been formed extraterrestrially in outer space.[152][153][154] Complex DNA and RNA organic compounds of life, including uracil, cytosine, and thymine, have also been formed in the laboratory under conditions mimicking those found in outer space, using starting chemicals, such as pyrimidine, found in meteorites. Pyrimidine, like polycyclic aromatic hydrocarbons (PAHs), the most carbon-rich chemical found in the universe, may have been formed in red giants or in interstellar cosmic dust and gas clouds.[155]
In February 2021, scientists reported, for the first time, the sequencing of DNA from animal remains, a mammoth in this instance over a million years old, the oldest DNA sequenced to date.[156][157]
Uses in technology
Genetic engineering
Methods have been developed to purify DNA from organisms, such as phenol-chloroform extraction, and to manipulate it in the laboratory, such as restriction digests and the polymerase chain reaction. Modern biology and biochemistry make intensive use of these techniques in recombinant DNA technology. Recombinant DNA is a man-made DNA sequence that has been assembled from other DNA sequences. They can be transformed into organisms in the form of plasmids or in the appropriate format, by using a viral vector.[158] The genetically modified organisms produced can be used to produce products such as recombinant proteins, used in medical research,[159] or be grown in agriculture.[160][161]
DNA profiling
Forensic scientists can use DNA in blood, semen, skin, saliva or hair found at a crime scene to identify a matching DNA of an individual, such as a perpetrator.[162] This process is formally termed DNA profiling, also called DNA fingerprinting. In DNA profiling, the lengths of variable sections of repetitive DNA, such as short tandem repeats and minisatellites, are compared between people. This method is usually an extremely reliable technique for identifying a matching DNA.[163] However, identification can be complicated if the scene is contaminated with DNA from several people.[164] DNA profiling was developed in 1984 by British geneticist Sir Alec Jeffreys,[165] and first used in forensic science to convict Colin Pitchfork in the 1988 Enderby murders case.[166]
The development of forensic science and the ability to now obtain genetic matching on minute samples of blood, skin, saliva, or hair has led to re-examining many cases. Evidence can now be uncovered that was scientifically impossible at the time of the original examination. Combined with the removal of the double jeopardy law in some places, this can allow cases to be reopened where prior trials have failed to produce sufficient evidence to convince a jury. People charged with serious crimes may be required to provide a sample of DNA for matching purposes. The most obvious defense to DNA matches obtained forensically is to claim that cross-contamination of evidence has occurred. This has resulted in meticulous strict handling procedures with new cases of serious crime.
DNA profiling is also used successfully to positively identify victims of mass casualty incidents,[167] bodies or body parts in serious accidents, and individual victims in mass war graves, via matching to family members.
DNA profiling is also used in DNA paternity testing to determine if someone is the biological parent or grandparent of a child with the probability of parentage is typically 99.99% when the alleged parent is biologically related to the child. Normal DNA sequencing methods happen after birth, but there are new methods to test paternity while a mother is still pregnant.[168]
DNA enzymes or catalytic DNA
Deoxyribozymes, also called DNAzymes or catalytic DNA, were first discovered in 1994.[169] They are mostly single stranded DNA sequences isolated from a large pool of random DNA sequences through a combinatorial approach called in vitro selection or systematic evolution of ligands by exponential enrichment (SELEX). DNAzymes catalyze variety of chemical reactions including RNA-DNA cleavage, RNA-DNA ligation, amino acids phosphorylation-dephosphorylation, carbon-carbon bond formation, etc. DNAzymes can enhance catalytic rate of chemical reactions up to 100,000,000,000-fold over the uncatalyzed reaction.[170] The most extensively studied class of DNAzymes is RNA-cleaving types which have been used to detect different metal ions and designing therapeutic agents. Several metal-specific DNAzymes have been reported including the GR-5 DNAzyme (lead-specific),[169] the CA1-3 DNAzymes (copper-specific),[171] the 39E DNAzyme (uranyl-specific) and the NaA43 DNAzyme (sodium-specific).[172] The NaA43 DNAzyme, which is reported to be more than 10,000-fold selective for sodium over other metal ions, was used to make a real-time sodium sensor in cells.
Bioinformatics
Bioinformatics involves the development of techniques to store, data mine, search and manipulate biological data, including DNA nucleic acid sequence data. These have led to widely applied advances in computer science, especially string searching algorithms, machine learning, and database theory.[173] String searching or matching algorithms, which find an occurrence of a sequence of letters inside a larger sequence of letters, were developed to search for specific sequences of nucleotides.[174] The DNA sequence may be aligned with other DNA sequences to identify homologous sequences and locate the specific mutations that make them distinct. These techniques, especially multiple sequence alignment, are used in studying phylogenetic relationships and protein function.[175] Data sets representing entire genomes’ worth of DNA sequences, such as those produced by the Human Genome Project, are difficult to use without the annotations that identify the locations of genes and regulatory elements on each chromosome. Regions of DNA sequence that have the characteristic patterns associated with protein- or RNA-coding genes can be identified by gene finding algorithms, which allow researchers to predict the presence of particular gene products and their possible functions in an organism even before they have been isolated experimentally.[176] Entire genomes may also be compared, which can shed light on the evolutionary history of particular organism and permit the examination of complex evolutionary events.
DNA nanotechnology

DNA nanotechnology uses the unique molecular recognition properties of DNA and other nucleic acids to create self-assembling branched DNA complexes with useful properties.[178] DNA is thus used as a structural material rather than as a carrier of biological information. This has led to the creation of two-dimensional periodic lattices (both tile-based and using the DNA origami method) and three-dimensional structures in the shapes of polyhedra.[179] Nanomechanical devices and algorithmic self-assembly have also been demonstrated,[180] and these DNA structures have been used to template the arrangement of other molecules such as gold nanoparticles and streptavidin proteins.[181] DNA and other nucleic acids are the basis of aptamers, synthetic oligonucleotide ligands for specific target molecules used in a range of biotechnology and biomedical applications.[182]
History and anthropology
Because DNA collects mutations over time, which are then inherited, it contains historical information, and, by comparing DNA sequences, geneticists can infer the evolutionary history of organisms, their phylogeny.[183] This field of phylogenetics is a powerful tool in evolutionary biology. If DNA sequences within a species are compared, population geneticists can learn the history of particular populations. This can be used in studies ranging from ecological genetics to anthropology.
Information storage
DNA as a storage device for information has enormous potential since it has much higher storage density compared to electronic devices. However, high costs, slow read and write times (memory latency), and insufficient reliability has prevented its practical use.[184][185]
History

Maclyn McCarty (left) shakes hands with Francis Crick and James Watson, co-originators of the double-helix model based on the X-ray diffraction data and insights of Rosalind Franklin and Raymond Gosling.
Pencil sketch of the DNA double helix by Francis Crick in 1953
DNA was first isolated by the Swiss physician Friedrich Miescher who, in 1869, discovered a microscopic substance in the pus of discarded surgical bandages. As it resided in the nuclei of cells, he called it «nuclein».[186][187] In 1878, Albrecht Kossel isolated the non-protein component of «nuclein», nucleic acid, and later isolated its five primary nucleobases.[188][189]
In 1909, Phoebus Levene identified the base, sugar, and phosphate nucleotide unit of the RNA (then named «yeast nucleic acid»).[190][191][192] In 1929, Levene identified deoxyribose sugar in «thymus nucleic acid» (DNA).[193] Levene suggested that DNA consisted of a string of four nucleotide units linked together through the phosphate groups («tetranucleotide hypothesis»). Levene thought the chain was short and the bases repeated in a fixed order. In 1927, Nikolai Koltsov proposed that inherited traits would be inherited via a «giant hereditary molecule» made up of «two mirror strands that would replicate in a semi-conservative fashion using each strand as a template».[194][195] In 1928, Frederick Griffith in his experiment discovered that traits of the «smooth» form of Pneumococcus could be transferred to the «rough» form of the same bacteria by mixing killed «smooth» bacteria with the live «rough» form.[196][197] This system provided the first clear suggestion that DNA carries genetic information.
In 1933, while studying virgin sea urchin eggs, Jean Brachet suggested that DNA is found in the cell nucleus and that RNA is present exclusively in the cytoplasm. At the time, «yeast nucleic acid» (RNA) was thought to occur only in plants, while «thymus nucleic acid» (DNA) only in animals. The latter was thought to be a tetramer, with the function of buffering cellular pH.[198][199]
In 1937, William Astbury produced the first X-ray diffraction patterns that showed that DNA had a regular structure.[200]
In 1943, Oswald Avery, along with co-workers Colin MacLeod and Maclyn McCarty, identified DNA as the transforming principle, supporting Griffith’s suggestion (Avery–MacLeod–McCarty experiment).[201] Erwin Chargaff developed and published observations now known as Chargaff’s rules, stating that in DNA from any species of any organism, the amount of guanine should be equal to cytosine and the amount of adenine should be equal to thymine.[202][203] Late in 1951, Francis Crick started working with James Watson at the Cavendish Laboratory within the University of Cambridge. DNA’s role in heredity was confirmed in 1952 when Alfred Hershey and Martha Chase in the Hershey–Chase experiment showed that DNA is the genetic material of the enterobacteria phage T2.[204]

In May 1952, Raymond Gosling, a graduate student working under the supervision of Rosalind Franklin, took an X-ray diffraction image, labeled as «Photo 51»,[205] at high hydration levels of DNA. This photo was given to Watson and Crick by Maurice Wilkins and was critical to their obtaining the correct structure of DNA. Franklin told Crick and Watson that the backbones had to be on the outside. Before then, Linus Pauling, and Watson and Crick, had erroneous models with the chains inside and the bases pointing outwards. Franklin’s identification of the space group for DNA crystals revealed to Crick that the two DNA strands were antiparallel.[206] In February 1953, Linus Pauling and Robert Corey proposed a model for nucleic acids containing three intertwined chains, with the phosphates near the axis, and the bases on the outside.[207] Watson and Crick completed their model, which is now accepted as the first correct model of the double helix of DNA. On 28 February 1953 Crick interrupted patrons’ lunchtime at The Eagle pub in Cambridge to announce that he and Watson had «discovered the secret of life».[208]
The 25 April 1953 issue of the journal Nature published a series of five articles giving the Watson and Crick double-helix structure DNA and evidence supporting it.[209] The structure was reported in a letter titled «MOLECULAR STRUCTURE OF NUCLEIC ACIDS A Structure for Deoxyribose Nucleic Acid«, in which they said, «It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.»[9] This letter was followed by a letter from Franklin and Gosling, which was the first publication of their own X-ray diffraction data and of their original analysis method.[47][210] Then followed a letter by Wilkins and two of his colleagues, which contained an analysis of in vivo B-DNA X-ray patterns, and which supported the presence in vivo of the Watson and Crick structure.[48]
In 1962, after Franklin’s death, Watson, Crick, and Wilkins jointly received the Nobel Prize in Physiology or Medicine.[211] Nobel Prizes are awarded only to living recipients. A debate continues about who should receive credit for the discovery.[212]
In an influential presentation in 1957, Crick laid out the central dogma of molecular biology, which foretold the relationship between DNA, RNA, and proteins, and articulated the «adaptor hypothesis».[213] Final confirmation of the replication mechanism that was implied by the double-helical structure followed in 1958 through the Meselson–Stahl experiment.[214] Further work by Crick and co-workers showed that the genetic code was based on non-overlapping triplets of bases, called codons, allowing Har Gobind Khorana, Robert W. Holley, and Marshall Warren Nirenberg to decipher the genetic code.[215] These findings represent the birth of molecular biology.[216]
See also
- Autosome – Any chromosome other than a sex chromosome
- Crystallography – Scientific study of crystal structures
- DNA Day – Holiday celebrated on April 25
- DNA microarray – Collection of microscopic DNA spots attached to a solid surface
- DNA sequencing – Process of determining the nucleic acid sequence
- Genetic disorder – Health problem caused by one or more abnormalities in the genome
- Genetic genealogy – DNA testing to infer relationships
- Haplotype – Group of genes from one parent
- Meiosis – Type of cell division in sexually-reproducing organisms used to produce gametes
- Nucleic acid notation – Universal notation using the Roman characters A, C, G, and T to call the four DNA nucleotides
- Nucleic acid sequence – Succession of nucleotides in a nucleic acid
- Ribosomal DNA
- Southern blot – DNA analysis technique
- X-ray scattering techniques
- Xeno nucleic acid
References
- ^ «deoxyribonucleic acid». Merriam-Webster Dictionary.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2014). Molecular Biology of the Cell (6th ed.). Garland. p. Chapter 4: DNA, Chromosomes and Genomes. ISBN 978-0-8153-4432-2. Archived from the original on 14 July 2014.
- ^ Purcell A. «DNA». Basic Biology. Archived from the original on 5 January 2017.
- ^ «Uracil». Genome.gov. Retrieved 21 November 2019.
- ^ Russell P (2001). iGenetics. New York: Benjamin Cummings. ISBN 0-8053-4553-1.
- ^ Saenger W (1984). Principles of Nucleic Acid Structure. New York: Springer-Verlag. ISBN 0-387-90762-9.
- ^ a b Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Peter W (2002). Molecular Biology of the Cell (Fourth ed.). New York and London: Garland Science. ISBN 0-8153-3218-1. OCLC 145080076. Archived from the original on 1 November 2016.
- ^ Irobalieva RN, Fogg JM, Catanese DJ, Catanese DJ, Sutthibutpong T, Chen M, Barker AK, Ludtke SJ, Harris SA, Schmid MF, Chiu W, Zechiedrich L (October 2015). «Structural diversity of supercoiled DNA». Nature Communications. 6: 8440. Bibcode:2015NatCo…6.8440I. doi:10.1038/ncomms9440. ISSN 2041-1723. PMC 4608029. PMID 26455586.
- ^ a b c d Watson JD, Crick FH (April 1953). «Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid» (PDF). Nature. 171 (4356): 737–38. Bibcode:1953Natur.171..737W. doi:10.1038/171737a0. ISSN 0028-0836. PMID 13054692. S2CID 4253007. Archived (PDF) from the original on 4 February 2007.
- ^ Mandelkern M, Elias JG, Eden D, Crothers DM (October 1981). «The dimensions of DNA in solution». Journal of Molecular Biology. 152 (1): 153–61. doi:10.1016/0022-2836(81)90099-1. ISSN 0022-2836. PMID 7338906.
- ^ a b c d Berg J, Tymoczko J, Stryer L (2002). Biochemistry. W.H. Freeman and Company. ISBN 0-7167-4955-6.
- ^ IUPAC-IUB Commission on Biochemical Nomenclature (CBN) (December 1970). «Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents. Recommendations 1970». The Biochemical Journal. 120 (3): 449–54. doi:10.1042/bj1200449. ISSN 0306-3283. PMC 1179624. PMID 5499957. Archived from the original on 5 February 2007.
- ^ a b Ghosh A, Bansal M (April 2003). «A glossary of DNA structures from A to Z». Acta Crystallographica Section D. 59 (Pt 4): 620–26. doi:10.1107/S0907444903003251. ISSN 0907-4449. PMID 12657780.
- ^ Created from PDB 1D65
- ^ Yakovchuk P, Protozanova E, Frank-Kamenetskii MD (2006). «Base-stacking and base-pairing contributions into thermal stability of the DNA double helix». Nucleic Acids Research. 34 (2): 564–74. doi:10.1093/nar/gkj454. ISSN 0305-1048. PMC 1360284. PMID 16449200.
- ^ Tropp BE (2012). Molecular Biology (4th ed.). Sudbury, Mass.: Jones and Barlett Learning. ISBN 978-0-7637-8663-2.
- ^ Carr S (1953). «Watson-Crick Structure of DNA». Memorial University of Newfoundland. Archived from the original on 19 July 2016. Retrieved 13 July 2016.
- ^ Verma S, Eckstein F (1998). «Modified oligonucleotides: synthesis and strategy for users». Annual Review of Biochemistry. 67: 99–134. doi:10.1146/annurev.biochem.67.1.99. ISSN 0066-4154. PMID 9759484.
- ^ Johnson TB, Coghill RD (1925). «Pyrimidines. CIII. The discovery of 5-methylcytosine in tuberculinic acid, the nucleic acid of the tubercle bacillus». Journal of the American Chemical Society. 47: 2838–44. doi:10.1021/ja01688a030. ISSN 0002-7863.
- ^ Weigele P, Raleigh EA (October 2016). «Biosynthesis and Function of Modified Bases in Bacteria and Their Viruses». Chemical Reviews. 116 (20): 12655–12687. doi:10.1021/acs.chemrev.6b00114. ISSN 0009-2665. PMID 27319741.
- ^ Kumar S, Chinnusamy V, Mohapatra T (2018). «Epigenetics of Modified DNA Bases: 5-Methylcytosine and Beyond». Frontiers in Genetics. 9: 640. doi:10.3389/fgene.2018.00640. ISSN 1664-8021. PMC 6305559. PMID 30619465.
- ^ Carell T, Kurz MQ, Müller M, Rossa M, Spada F (April 2018). «Non-canonical Bases in the Genome: The Regulatory Information Layer in DNA». Angewandte Chemie. 57 (16): 4296–4312. doi:10.1002/anie.201708228. PMID 28941008.
- ^ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson RE (October 1980). «Crystal structure analysis of a complete turn of B-DNA». Nature. 287 (5784): 755–58. Bibcode:1980Natur.287..755W. doi:10.1038/287755a0. PMID 7432492. S2CID 4315465.
- ^ a b Pabo CO, Sauer RT (1984). «Protein-DNA recognition». Annual Review of Biochemistry. 53: 293–321. doi:10.1146/annurev.bi.53.070184.001453. PMID 6236744.
- ^ Nikolova EN, Zhou H, Gottardo FL, Alvey HS, Kimsey IJ, Al-Hashimi HM (2013). «A historical account of Hoogsteen base-pairs in duplex DNA». Biopolymers. 99 (12): 955–68. doi:10.1002/bip.22334. PMC 3844552. PMID 23818176.
- ^ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub HE (April 2000). «Mechanical stability of single DNA molecules». Biophysical Journal. 78 (4): 1997–2007. Bibcode:2000BpJ….78.1997C. doi:10.1016/S0006-3495(00)76747-6. PMC 1300792. PMID 10733978.
- ^ Chalikian TV, Völker J, Plum GE, Breslauer KJ (July 1999). «A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques». Proceedings of the National Academy of Sciences of the United States of America. 96 (14): 7853–58. Bibcode:1999PNAS…96.7853C. doi:10.1073/pnas.96.14.7853. PMC 22151. PMID 10393911.
- ^ deHaseth PL, Helmann JD (June 1995). «Open complex formation by Escherichia coli RNA polymerase: the mechanism of polymerase-induced strand separation of double helical DNA». Molecular Microbiology. 16 (5): 817–24. doi:10.1111/j.1365-2958.1995.tb02309.x. PMID 7476180. S2CID 24479358.
- ^ Isaksson J, Acharya S, Barman J, Cheruku P, Chattopadhyaya J (December 2004). «Single-stranded adenine-rich DNA and RNA retain structural characteristics of their respective double-stranded conformations and show directional differences in stacking pattern» (PDF). Biochemistry. 43 (51): 15996–6010. doi:10.1021/bi048221v. PMID 15609994. Archived (PDF) from the original on 10 June 2007.
- ^ a b Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L (2019). «On the length, weight and GC content of the human genome». BMC Res Notes. 12 (1): 106. doi:10.1186/s13104-019-4137-z. PMC 6391780. PMID 30813969.
- ^ Gregory SG, Barlow KF, McLay KE, Kaul R, Swarbreck D, Dunham A, et al. (May 2006). «The DNA sequence and biological annotation of human chromosome 1». Nature. 441 (7091): 315–21. Bibcode:2006Natur.441..315G. doi:10.1038/nature04727. PMID 16710414.
- ^ Anderson, S.; Bankier, A. T.; Barrell, B. G.; de Bruijn, M. H. L.; Coulson, A. R.; Drouin, J.; Eperon, I. C.; Nierlich, D. P.; Roe, B. A.; Sanger, F.; Schreier, P. H.; Smith, A. J. H.; Staden, R.; Young, I. G. (April 1981). «Sequence and organization of the human mitochondrial genome». Nature. 290 (5806): 457–465. Bibcode:1981Natur.290..457A. doi:10.1038/290457a0. PMID 7219534. S2CID 4355527.
- ^ «Untitled». Archived from the original on 13 August 2011. Retrieved 13 June 2012.
- ^ a b c Satoh, M; Kuroiwa, T (September 1991). «Organization of multiple nucleoids and DNA molecules in mitochondria of a human cell». Experimental Cell Research. 196 (1): 137–140. doi:10.1016/0014-4827(91)90467-9. PMID 1715276.
- ^ Zhang D, Keilty D, Zhang ZF, Chian RC (2017). «Mitochondria in oocyte aging: current understanding». Facts Views Vis Obgyn. 9 (1): 29–38. PMC 5506767. PMID 28721182.
- ^ Designation of the two strands of DNA Archived 24 April 2008 at the Wayback Machine JCBN/NC-IUB Newsletter 1989. Retrieved 7 May 2008
- ^ Hüttenhofer A, Schattner P, Polacek N (May 2005). «Non-coding RNAs: hope or hype?». Trends in Genetics. 21 (5): 289–97. doi:10.1016/j.tig.2005.03.007. PMID 15851066.
- ^ Munroe SH (November 2004). «Diversity of antisense regulation in eukaryotes: multiple mechanisms, emerging patterns». Journal of Cellular Biochemistry. 93 (4): 664–71. doi:10.1002/jcb.20252. PMID 15389973. S2CID 23748148.
- ^ Makalowska I, Lin CF, Makalowski W (February 2005). «Overlapping genes in vertebrate genomes». Computational Biology and Chemistry. 29 (1): 1–12. doi:10.1016/j.compbiolchem.2004.12.006. PMID 15680581.
- ^ Johnson ZI, Chisholm SW (November 2004). «Properties of overlapping genes are conserved across microbial genomes». Genome Research. 14 (11): 2268–72. doi:10.1101/gr.2433104. PMC 525685. PMID 15520290.
- ^ Lamb RA, Horvath CM (August 1991). «Diversity of coding strategies in influenza viruses». Trends in Genetics. 7 (8): 261–66. doi:10.1016/0168-9525(91)90326-L. PMC 7173306. PMID 1771674.
- ^ Benham CJ, Mielke SP (2005). «DNA mechanics» (PDF). Annual Review of Biomedical Engineering. 7: 21–53. doi:10.1146/annurev.bioeng.6.062403.132016. PMID 16004565. S2CID 1427671. Archived from the original (PDF) on 1 March 2019.
- ^ a b Champoux JJ (2001). «DNA topoisomerases: structure, function, and mechanism» (PDF). Annual Review of Biochemistry. 70: 369–413. doi:10.1146/annurev.biochem.70.1.369. PMID 11395412. S2CID 18144189.
- ^ a b Wang JC (June 2002). «Cellular roles of DNA topoisomerases: a molecular perspective». Nature Reviews Molecular Cell Biology. 3 (6): 430–40. doi:10.1038/nrm831. PMID 12042765. S2CID 205496065.
- ^ Basu HS, Feuerstein BG, Zarling DA, Shafer RH, Marton LJ (October 1988). «Recognition of Z-RNA and Z-DNA determinants by polyamines in solution: experimental and theoretical studies». Journal of Biomolecular Structure & Dynamics. 6 (2): 299–309. doi:10.1080/07391102.1988.10507714. PMID 2482766.
- ^
- Franklin RE, Gosling RG (6 March 1953). «The Structure of Sodium Thymonucleate Fibres I. The Influence of Water Content» (PDF). Acta Crystallogr. 6 (8–9): 673–77. doi:10.1107/S0365110X53001939. Archived (PDF) from the original on 9 January 2016.
- Franklin RE, Gosling RG (1953). «The structure of sodium thymonucleate fibres. II. The cylindrically symmetrical Patterson function» (PDF). Acta Crystallogr. 6 (8–9): 678–85. doi:10.1107/S0365110X53001940. Archived (PDF) from the original on 29 June 2017.
- ^ a b Franklin RE, Gosling RG (April 1953). «Molecular configuration in sodium thymonucleate» (PDF). Nature. 171 (4356): 740–41. Bibcode:1953Natur.171..740F. doi:10.1038/171740a0. PMID 13054694. S2CID 4268222. Archived (PDF) from the original on 3 January 2011.
- ^ a b Wilkins MH, Stokes AR, Wilson HR (April 1953). «Molecular structure of deoxypentose nucleic acids» (PDF). Nature. 171 (4356): 738–40. Bibcode:1953Natur.171..738W. doi:10.1038/171738a0. PMID 13054693. S2CID 4280080. Archived (PDF) from the original on 13 May 2011.
- ^ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL (October 1980). «Polymorphism of DNA double helices». Journal of Molecular Biology. 143 (1): 49–72. doi:10.1016/0022-2836(80)90124-2. PMID 7441761.
- ^ Baianu IC (1980). «Structural Order and Partial Disorder in Biological systems». Bull. Math. Biol. 42 (4): 137–41. doi:10.1007/BF02462372. S2CID 189888972.
- ^ Hosemann R, Bagchi RN (1962). Direct analysis of diffraction by matter. Amsterdam – New York: North-Holland Publishers.
- ^ Baianu IC (1978). «X-ray scattering by partially disordered membrane systems» (PDF). Acta Crystallogr A. 34 (5): 751–53. Bibcode:1978AcCrA..34..751B. doi:10.1107/S0567739478001540. Archived from the original (PDF) on 14 March 2020. Retrieved 29 August 2019.
- ^ Wahl MC, Sundaralingam M (1997). «Crystal structures of A-DNA duplexes». Biopolymers. 44 (1): 45–63. doi:10.1002/(SICI)1097-0282(1997)44:1<45::AID-BIP4>3.0.CO;2-#. PMID 9097733.
- ^ Lu XJ, Shakked Z, Olson WK (July 2000). «A-form conformational motifs in ligand-bound DNA structures». Journal of Molecular Biology. 300 (4): 819–40. doi:10.1006/jmbi.2000.3690. PMID 10891271.
- ^ Rothenburg S, Koch-Nolte F, Haag F (December 2001). «DNA methylation and Z-DNA formation as mediators of quantitative differences in the expression of alleles». Immunological Reviews. 184: 286–98. doi:10.1034/j.1600-065x.2001.1840125.x. PMID 12086319. S2CID 20589136.
- ^ Oh DB, Kim YG, Rich A (December 2002). «Z-DNA-binding proteins can act as potent effectors of gene expression in vivo». Proceedings of the National Academy of Sciences of the United States of America. 99 (26): 16666–71. Bibcode:2002PNAS…9916666O. doi:10.1073/pnas.262672699. PMC 139201. PMID 12486233.
- ^ Palmer J (2 December 2010). «Arsenic-loving bacteria may help in hunt for alien life». BBC News. Archived from the original on 3 December 2010. Retrieved 2 December 2010.
- ^ a b Bortman H (2 December 2010). «Arsenic-Eating Bacteria Opens New Possibilities for Alien Life». Space.com. Archived from the original on 4 December 2010. Retrieved 2 December 2010.
- ^ Katsnelson A (2 December 2010). «Arsenic-eating microbe may redefine chemistry of life». Nature News. doi:10.1038/news.2010.645. Archived from the original on 12 February 2012.
- ^ Cressey D (3 October 2012). «‘Arsenic-life’ Bacterium Prefers Phosphorus after all». Nature News. doi:10.1038/nature.2012.11520. S2CID 87341731.
- ^ Created from Archived 17 October 2016 at the Wayback Machine
- ^ a b Greider CW, Blackburn EH (December 1985). «Identification of a specific telomere terminal transferase activity in Tetrahymena extracts». Cell. 43 (2 Pt 1): 405–13. doi:10.1016/0092-8674(85)90170-9. PMID 3907856.
- ^ a b c Nugent CI, Lundblad V (April 1998). «The telomerase reverse transcriptase: components and regulation». Genes & Development. 12 (8): 1073–85. doi:10.1101/gad.12.8.1073. PMID 9553037.
- ^ Wright WE, Tesmer VM, Huffman KE, Levene SD, Shay JW (November 1997). «Normal human chromosomes have long G-rich telomeric overhangs at one end». Genes & Development. 11 (21): 2801–09. doi:10.1101/gad.11.21.2801. PMC 316649. PMID 9353250.
- ^ a b Burge S, Parkinson GN, Hazel P, Todd AK, Neidle S (2006). «Quadruplex DNA: sequence, topology and structure». Nucleic Acids Research. 34 (19): 5402–15. doi:10.1093/nar/gkl655. PMC 1636468. PMID 17012276.
- ^ Parkinson GN, Lee MP, Neidle S (June 2002). «Crystal structure of parallel quadruplexes from human telomeric DNA». Nature. 417 (6891): 876–80. Bibcode:2002Natur.417..876P. doi:10.1038/nature755. PMID 12050675. S2CID 4422211.
- ^ Griffith JD, Comeau L, Rosenfield S, Stansel RM, Bianchi A, Moss H, de Lange T (May 1999). «Mammalian telomeres end in a large duplex loop». Cell. 97 (4): 503–14. CiteSeerX 10.1.1.335.2649. doi:10.1016/S0092-8674(00)80760-6. PMID 10338214. S2CID 721901.
- ^ Seeman NC (November 2005). «DNA enables nanoscale control of the structure of matter». Quarterly Reviews of Biophysics. 38 (4): 363–71. doi:10.1017/S0033583505004087. PMC 3478329. PMID 16515737.
- ^ Warren M (21 February 2019). «Four new DNA letters double life’s alphabet». Nature. 566 (7745): 436. Bibcode:2019Natur.566..436W. doi:10.1038/d41586-019-00650-8. PMID 30809059.
- ^ Hoshika S, Leal NA, Kim MJ, Kim MS, Karalkar NB, Kim HJ, et al. (22 February 2019). «Hachimoji DNA and RNA: A genetic system with eight building blocks (paywall)». Science. 363 (6429): 884–887. Bibcode:2019Sci…363..884H. doi:10.1126/science.aat0971. PMC 6413494. PMID 30792304.
- ^ Burghardt B, Hartmann AK (February 2007). «RNA secondary structure design». Physical Review E. 75 (2): 021920. arXiv:physics/0609135. Bibcode:2007PhRvE..75b1920B. doi:10.1103/PhysRevE.75.021920. PMID 17358380. S2CID 17574854.
- ^ Reusch, William. «Nucleic Acids». Michigan State University. Retrieved 30 June 2022.
- ^ «How To Extract DNA From Anything Living». University of Utah. Retrieved 30 June 2022.
- ^ Hu Q, Rosenfeld MG (2012). «Epigenetic regulation of human embryonic stem cells». Frontiers in Genetics. 3: 238. doi:10.3389/fgene.2012.00238. PMC 3488762. PMID 23133442.
- ^ Klose RJ, Bird AP (February 2006). «Genomic DNA methylation: the mark and its mediators». Trends in Biochemical Sciences. 31 (2): 89–97. doi:10.1016/j.tibs.2005.12.008. PMID 16403636.
- ^ Bird A (January 2002). «DNA methylation patterns and epigenetic memory». Genes & Development. 16 (1): 6–21. doi:10.1101/gad.947102. PMID 11782440.
- ^ Walsh CP, Xu GL (2006). «Cytosine methylation and DNA repair». Current Topics in Microbiology and Immunology. 301: 283–315. doi:10.1007/3-540-31390-7_11. ISBN 3-540-29114-8. PMID 16570853.
- ^ Kriaucionis S, Heintz N (May 2009). «The nuclear DNA base 5-hydroxymethylcytosine is present in Purkinje neurons and the brain». Science. 324 (5929): 929–30. Bibcode:2009Sci…324..929K. doi:10.1126/science.1169786. PMC 3263819. PMID 19372393.
- ^ Ratel D, Ravanat JL, Berger F, Wion D (March 2006). «N6-methyladenine: the other methylated base of DNA». BioEssays. 28 (3): 309–15. doi:10.1002/bies.20342. PMC 2754416. PMID 16479578.
- ^ Gommers-Ampt JH, Van Leeuwen F, de Beer AL, Vliegenthart JF, Dizdaroglu M, Kowalak JA, Crain PF, Borst P (December 1993). «beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei». Cell. 75 (6): 1129–36. doi:10.1016/0092-8674(93)90322-H. hdl:1874/5219. PMID 8261512. S2CID 24801094.
- ^ Created from PDB 1JDG Archived 22 September 2008 at the Wayback Machine
- ^ Douki T, Reynaud-Angelin A, Cadet J, Sage E (August 2003). «Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation». Biochemistry. 42 (30): 9221–26. doi:10.1021/bi034593c. PMID 12885257.
- ^ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget JP, Ravanat JL, Sauvaigo S (March 1999). «Hydroxyl radicals and DNA base damage». Mutation Research. 424 (1–2): 9–21. doi:10.1016/S0027-5107(99)00004-4. PMID 10064846.
- ^ Beckman KB, Ames BN (August 1997). «Oxidative decay of DNA». The Journal of Biological Chemistry. 272 (32): 19633–36. doi:10.1074/jbc.272.32.19633. PMID 9289489.
- ^ Valerie K, Povirk LF (September 2003). «Regulation and mechanisms of mammalian double-strand break repair». Oncogene. 22 (37): 5792–812. doi:10.1038/sj.onc.1206679. PMID 12947387.
- ^ Johnson G (28 December 2010). «Unearthing Prehistoric Tumors, and Debate». The New York Times. Archived from the original on 24 June 2017.
If we lived long enough, sooner or later we all would get cancer.
- ^ Alberts B, Johnson A, Lewis J, et al. (2002). «The Preventable Causes of Cancer». Molecular biology of the cell (4th ed.). New York: Garland Science. ISBN 0-8153-4072-9. Archived from the original on 2 January 2016.
A certain irreducible background incidence of cancer is to be expected regardless of circumstances: mutations can never be absolutely avoided, because they are an inescapable consequence of fundamental limitations on the accuracy of DNA replication, as discussed in Chapter 5. If a human could live long enough, it is inevitable that at least one of his or her cells would eventually accumulate a set of mutations sufficient for cancer to develop.
- ^ Bernstein H, Payne CM, Bernstein C, Garewal H, Dvorak K (2008). «Cancer and aging as consequences of un-repaired DNA damage». In Kimura H, Suzuki A (eds.). New Research on DNA Damage. New York: Nova Science Publishers. pp. 1–47. ISBN 978-1-60456-581-2. Archived from the original on 25 October 2014.
- ^ Hoeijmakers JH (October 2009). «DNA damage, aging, and cancer». The New England Journal of Medicine. 361 (15): 1475–85. doi:10.1056/NEJMra0804615. PMID 19812404.
- ^ Freitas AA, de Magalhães JP (2011). «A review and appraisal of the DNA damage theory of ageing». Mutation Research. 728 (1–2): 12–22. doi:10.1016/j.mrrev.2011.05.001. PMID 21600302.
- ^ Ferguson LR, Denny WA (September 1991). «The genetic toxicology of acridines». Mutation Research. 258 (2): 123–60. doi:10.1016/0165-1110(91)90006-H. PMID 1881402.
- ^ Stephens TD, Bunde CJ, Fillmore BJ (June 2000). «Mechanism of action in thalidomide teratogenesis». Biochemical Pharmacology. 59 (12): 1489–99. doi:10.1016/S0006-2952(99)00388-3. PMID 10799645.
- ^ Jeffrey AM (1985). «DNA modification by chemical carcinogens». Pharmacology & Therapeutics. 28 (2): 237–72. doi:10.1016/0163-7258(85)90013-0. PMID 3936066.
- ^ Braña MF, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (November 2001). «Intercalators as anticancer drugs». Current Pharmaceutical Design. 7 (17): 1745–80. doi:10.2174/1381612013397113. PMID 11562309.
- ^ Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. (February 2001). «The sequence of the human genome». Science. 291 (5507): 1304–51. Bibcode:2001Sci…291.1304V. doi:10.1126/science.1058040. PMID 11181995.
- ^ Thanbichler M, Wang SC, Shapiro L (October 2005). «The bacterial nucleoid: a highly organized and dynamic structure». Journal of Cellular Biochemistry. 96 (3): 506–21. doi:10.1002/jcb.20519. PMID 15988757.
- ^ Wolfsberg TG, McEntyre J, Schuler GD (February 2001). «Guide to the draft human genome». Nature. 409 (6822): 824–26. Bibcode:2001Natur.409..824W. doi:10.1038/35057000. PMID 11236998.
- ^ Gregory TR (January 2005). «The C-value enigma in plants and animals: a review of parallels and an appeal for partnership». Annals of Botany. 95 (1): 133–46. doi:10.1093/aob/mci009. PMC 4246714. PMID 15596463.
- ^ Birney E, Stamatoyannopoulos JA, Dutta A, Guigó R, Gingeras TR, Margulies EH, et al. (June 2007). «Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project». Nature. 447 (7146): 799–816. Bibcode:2007Natur.447..799B. doi:10.1038/nature05874. PMC 2212820. PMID 17571346.
- ^ Created from PDB 1MSW Archived 6 January 2008 at the Wayback Machine
- ^ Pidoux AL, Allshire RC (March 2005). «The role of heterochromatin in centromere function». Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 360 (1455): 569–79. doi:10.1098/rstb.2004.1611. PMC 1569473. PMID 15905142.
- ^ Harrison PM, Hegyi H, Balasubramanian S, Luscombe NM, Bertone P, Echols N, Johnson T, Gerstein M (February 2002). «Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22». Genome Research. 12 (2): 272–80. doi:10.1101/gr.207102. PMC 155275. PMID 11827946.
- ^ Harrison PM, Gerstein M (May 2002). «Studying genomes through the aeons: protein families, pseudogenes and proteome evolution». Journal of Molecular Biology. 318 (5): 1155–74. doi:10.1016/S0022-2836(02)00109-2. PMID 12083509.
- ^ Albà M (2001). «Replicative DNA polymerases». Genome Biology. 2 (1): REVIEWS3002. doi:10.1186/gb-2001-2-1-reviews3002. PMC 150442. PMID 11178285.
- ^ Tani K, Nasu M (2010). «Roles of Extracellular DNA in Bacterial Ecosystems». In Kikuchi Y, Rykova EY (eds.). Extracellular Nucleic Acids. Springer. pp. 25–38. ISBN 978-3-642-12616-1.
- ^ Vlassov VV, Laktionov PP, Rykova EY (July 2007). «Extracellular nucleic acids». BioEssays. 29 (7): 654–67. doi:10.1002/bies.20604. PMID 17563084. S2CID 32463239.
- ^ Finkel SE, Kolter R (November 2001). «DNA as a nutrient: novel role for bacterial competence gene homologs». Journal of Bacteriology. 183 (21): 6288–93. doi:10.1128/JB.183.21.6288-6293.2001. PMC 100116. PMID 11591672.
- ^ Mulcahy H, Charron-Mazenod L, Lewenza S (November 2008). «Extracellular DNA chelates cations and induces antibiotic resistance in Pseudomonas aeruginosa biofilms». PLOS Pathogens. 4 (11): e1000213. doi:10.1371/journal.ppat.1000213. PMC 2581603. PMID 19023416.
- ^ Berne C, Kysela DT, Brun YV (August 2010). «A bacterial extracellular DNA inhibits settling of motile progeny cells within a biofilm». Molecular Microbiology. 77 (4): 815–29. doi:10.1111/j.1365-2958.2010.07267.x. PMC 2962764. PMID 20598083.
- ^ Whitchurch CB, Tolker-Nielsen T, Ragas PC, Mattick JS (February 2002). «Extracellular DNA required for bacterial biofilm formation». Science. 295 (5559): 1487. doi:10.1126/science.295.5559.1487. PMID 11859186.
- ^ Hu W, Li L, Sharma S, Wang J, McHardy I, Lux R, Yang Z, He X, Gimzewski JK, Li Y, Shi W (2012). «DNA builds and strengthens the extracellular matrix in Myxococcus xanthus biofilms by interacting with exopolysaccharides». PLOS ONE. 7 (12): e51905. Bibcode:2012PLoSO…751905H. doi:10.1371/journal.pone.0051905. PMC 3530553. PMID 23300576.
- ^ Hui L, Bianchi DW (February 2013). «Recent advances in the prenatal interrogation of the human fetal genome». Trends in Genetics. 29 (2): 84–91. doi:10.1016/j.tig.2012.10.013. PMC 4378900. PMID 23158400.
- ^ Foote AD, Thomsen PF, Sveegaard S, Wahlberg M, Kielgast J, Kyhn LA, et al. (2012). «Investigating the potential use of environmental DNA (eDNA) for genetic monitoring of marine mammals». PLOS ONE. 7 (8): e41781. Bibcode:2012PLoSO…741781F. doi:10.1371/journal.pone.0041781. PMC 3430683. PMID 22952587.
- ^ «Researchers Detect Land Animals Using DNA in Nearby Water Bodies».
- ^ Sandman K, Pereira SL, Reeve JN (December 1998). «Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome». Cellular and Molecular Life Sciences. 54 (12): 1350–64. doi:10.1007/s000180050259. PMID 9893710. S2CID 21101836.
- ^ Dame RT (May 2005). «The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin». Molecular Microbiology. 56 (4): 858–70. doi:10.1111/j.1365-2958.2005.04598.x. PMID 15853876. S2CID 26965112.
- ^ Luger K, Mäder AW, Richmond RK, Sargent DF, Richmond TJ (September 1997). «Crystal structure of the nucleosome core particle at 2.8 A resolution». Nature. 389 (6648): 251–60. Bibcode:1997Natur.389..251L. doi:10.1038/38444. PMID 9305837. S2CID 4328827.
- ^ Jenuwein T, Allis CD (August 2001). «Translating the histone code» (PDF). Science. 293 (5532): 1074–80. doi:10.1126/science.1063127. PMID 11498575. S2CID 1883924. Archived (PDF) from the original on 8 August 2017.
- ^ Ito T (2003). «Nucleosome assembly and remodeling». Current Topics in Microbiology and Immunology. 274: 1–22. doi:10.1007/978-3-642-55747-7_1. ISBN 978-3-540-44208-0. PMID 12596902.
- ^ Thomas JO (August 2001). «HMG1 and 2: architectural DNA-binding proteins». Biochemical Society Transactions. 29 (Pt 4): 395–401. doi:10.1042/BST0290395. PMID 11497996.
- ^ Grosschedl R, Giese K, Pagel J (March 1994). «HMG domain proteins: architectural elements in the assembly of nucleoprotein structures». Trends in Genetics. 10 (3): 94–100. doi:10.1016/0168-9525(94)90232-1. PMID 8178371.
- ^ Iftode C, Daniely Y, Borowiec JA (1999). «Replication protein A (RPA): the eukaryotic SSB». Critical Reviews in Biochemistry and Molecular Biology. 34 (3): 141–80. doi:10.1080/10409239991209255. PMID 10473346.
- ^ Created from PDB 1LMB Archived 6 January 2008 at the Wayback Machine
- ^ Myers LC, Kornberg RD (2000). «Mediator of transcriptional regulation». Annual Review of Biochemistry. 69: 729–49. doi:10.1146/annurev.biochem.69.1.729. PMID 10966474.
- ^ Spiegelman BM, Heinrich R (October 2004). «Biological control through regulated transcriptional coactivators». Cell. 119 (2): 157–67. doi:10.1016/j.cell.2004.09.037. PMID 15479634.
- ^ Li Z, Van Calcar S, Qu C, Cavenee WK, Zhang MQ, Ren B (July 2003). «A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells». Proceedings of the National Academy of Sciences of the United States of America. 100 (14): 8164–69. Bibcode:2003PNAS..100.8164L. doi:10.1073/pnas.1332764100. PMC 166200. PMID 12808131.
- ^ Created from PDB 1RVA Archived 6 January 2008 at the Wayback Machine
- ^ Bickle TA, Krüger DH (June 1993). «Biology of DNA restriction». Microbiological Reviews. 57 (2): 434–50. doi:10.1128/MMBR.57.2.434-450.1993. PMC 372918. PMID 8336674.
- ^ a b Doherty AJ, Suh SW (November 2000). «Structural and mechanistic conservation in DNA ligases». Nucleic Acids Research. 28 (21): 4051–58. doi:10.1093/nar/28.21.4051. PMC 113121. PMID 11058099.
- ^ Schoeffler AJ, Berger JM (December 2005). «Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism». Biochemical Society Transactions. 33 (Pt 6): 1465–70. doi:10.1042/BST20051465. PMID 16246147.
- ^ Tuteja N, Tuteja R (May 2004). «Unraveling DNA helicases. Motif, structure, mechanism and function» (PDF). European Journal of Biochemistry. 271 (10): 1849–63. doi:10.1111/j.1432-1033.2004.04094.x. PMID 15128295.
- ^ Joyce CM, Steitz TA (November 1995). «Polymerase structures and function: variations on a theme?». Journal of Bacteriology. 177 (22): 6321–29. doi:10.1128/jb.177.22.6321-6329.1995. PMC 177480. PMID 7592405.
- ^ Hubscher U, Maga G, Spadari S (2002). «Eukaryotic DNA polymerases» (PDF). Annual Review of Biochemistry. 71: 133–63. doi:10.1146/annurev.biochem.71.090501.150041. PMID 12045093. S2CID 26171993. Archived from the original (PDF) on 26 January 2021.
- ^ Johnson A, O’Donnell M (2005). «Cellular DNA replicases: components and dynamics at the replication fork». Annual Review of Biochemistry. 74: 283–315. doi:10.1146/annurev.biochem.73.011303.073859. PMID 15952889.
- ^ a b Tarrago-Litvak L, Andréola ML, Nevinsky GA, Sarih-Cottin L, Litvak S (May 1994). «The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention». FASEB Journal. 8 (8): 497–503. doi:10.1096/fasebj.8.8.7514143. PMID 7514143. S2CID 39614573.
- ^ Martinez E (December 2002). «Multi-protein complexes in eukaryotic gene transcription». Plant Molecular Biology. 50 (6): 925–47. doi:10.1023/A:1021258713850. PMID 12516863. S2CID 24946189.
- ^ Created from PDB 1M6G Archived 10 January 2010 at the Wayback Machine
- ^ Cremer T, Cremer C (April 2001). «Chromosome territories, nuclear architecture and gene regulation in mammalian cells». Nature Reviews Genetics. 2 (4): 292–301. doi:10.1038/35066075. PMID 11283701. S2CID 8547149.
- ^ Pál C, Papp B, Lercher MJ (May 2006). «An integrated view of protein evolution». Nature Reviews Genetics. 7 (5): 337–48. doi:10.1038/nrg1838. PMID 16619049. S2CID 23225873.
- ^ O’Driscoll M, Jeggo PA (January 2006). «The role of double-strand break repair – insights from human genetics». Nature Reviews Genetics. 7 (1): 45–54. doi:10.1038/nrg1746. PMID 16369571. S2CID 7779574.
- ^ Vispé S, Defais M (October 1997). «Mammalian Rad51 protein: a RecA homologue with pleiotropic functions». Biochimie. 79 (9–10): 587–92. doi:10.1016/S0300-9084(97)82007-X. PMID 9466696.
- ^ Neale MJ, Keeney S (July 2006). «Clarifying the mechanics of DNA strand exchange in meiotic recombination». Nature. 442 (7099): 153–58. Bibcode:2006Natur.442..153N. doi:10.1038/nature04885. PMC 5607947. PMID 16838012.
- ^ Dickman MJ, Ingleston SM, Sedelnikova SE, Rafferty JB, Lloyd RG, Grasby JA, Hornby DP (November 2002). «The RuvABC resolvasome». European Journal of Biochemistry. 269 (22): 5492–501. doi:10.1046/j.1432-1033.2002.03250.x. PMID 12423347. S2CID 39505263.
- ^ Joyce GF (July 2002). «The antiquity of RNA-based evolution». Nature. 418 (6894): 214–21. Bibcode:2002Natur.418..214J. doi:10.1038/418214a. PMID 12110897. S2CID 4331004.
- ^ Orgel LE (2004). «Prebiotic chemistry and the origin of the RNA world». Critical Reviews in Biochemistry and Molecular Biology. 39 (2): 99–123. CiteSeerX 10.1.1.537.7679. doi:10.1080/10409230490460765. PMID 15217990.
- ^ Davenport RJ (May 2001). «Ribozymes. Making copies in the RNA world». Science. 292 (5520): 1278a–1278. doi:10.1126/science.292.5520.1278a. PMID 11360970. S2CID 85976762.
- ^ Szathmáry E (April 1992). «What is the optimum size for the genetic alphabet?». Proceedings of the National Academy of Sciences of the United States of America. 89 (7): 2614–18. Bibcode:1992PNAS…89.2614S. doi:10.1073/pnas.89.7.2614. PMC 48712. PMID 1372984.
- ^ Lindahl T (April 1993). «Instability and decay of the primary structure of DNA». Nature. 362 (6422): 709–15. Bibcode:1993Natur.362..709L. doi:10.1038/362709a0. PMID 8469282. S2CID 4283694.
- ^ Vreeland RH, Rosenzweig WD, Powers DW (October 2000). «Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal». Nature. 407 (6806): 897–900. Bibcode:2000Natur.407..897V. doi:10.1038/35038060. PMID 11057666. S2CID 9879073.
- ^ Hebsgaard MB, Phillips MJ, Willerslev E (May 2005). «Geologically ancient DNA: fact or artefact?». Trends in Microbiology. 13 (5): 212–20. doi:10.1016/j.tim.2005.03.010. PMID 15866038.
- ^ Nickle DC, Learn GH, Rain MW, Mullins JI, Mittler JE (January 2002). «Curiously modern DNA for a «250 million-year-old» bacterium». Journal of Molecular Evolution. 54 (1): 134–37. Bibcode:2002JMolE..54..134N. doi:10.1007/s00239-001-0025-x. PMID 11734907. S2CID 24740859.
- ^ Callahan MP, Smith KE, Cleaves HJ, Ruzicka J, Stern JC, Glavin DP, House CH, Dworkin JP (August 2011). «Carbonaceous meteorites contain a wide range of extraterrestrial nucleobases». Proceedings of the National Academy of Sciences of the United States of America. 108 (34): 13995–98. Bibcode:2011PNAS..10813995C. doi:10.1073/pnas.1106493108. PMC 3161613. PMID 21836052.
- ^ Steigerwald J (8 August 2011). «NASA Researchers: DNA Building Blocks Can Be Made in Space». NASA. Archived from the original on 23 June 2015. Retrieved 10 August 2011.
- ^ ScienceDaily Staff (9 August 2011). «DNA Building Blocks Can Be Made in Space, NASA Evidence Suggests». ScienceDaily. Archived from the original on 5 September 2011. Retrieved 9 August 2011.
- ^ Marlaire R (3 March 2015). «NASA Ames Reproduces the Building Blocks of Life in Laboratory». NASA. Archived from the original on 5 March 2015. Retrieved 5 March 2015.
- ^ Hunt, Katie (17 February 2021). «World’s oldest DNA sequenced from a mammoth that lived more than a million years ago». CNN News. Retrieved 17 February 2021.
- ^ Callaway, Ewen (17 February 2021). «Million-year-old mammoth genomes shatter record for oldest ancient DNA – Permafrost-preserved teeth, up to 1.6 million years old, identify a new kind of mammoth in Siberia». Nature. 590 (7847): 537–538. doi:10.1038/d41586-021-00436-x. ISSN 0028-0836. PMID 33597786.
- ^ Goff SP, Berg P (December 1976). «Construction of hybrid viruses containing SV40 and lambda phage DNA segments and their propagation in cultured monkey cells». Cell. 9 (4 PT 2): 695–705. doi:10.1016/0092-8674(76)90133-1. PMID 189942. S2CID 41788896.
- ^ Houdebine LM (2007). «Transgenic animal models in biomedical research». Target Discovery and Validation Reviews and Protocols. Methods in Molecular Biology. Vol. 360. pp. 163–202. doi:10.1385/1-59745-165-7:163. ISBN 978-1-59745-165-9. PMID 17172731.
- ^ Daniell H, Dhingra A (April 2002). «Multigene engineering: dawn of an exciting new era in biotechnology». Current Opinion in Biotechnology. 13 (2): 136–41. doi:10.1016/S0958-1669(02)00297-5. PMC 3481857. PMID 11950565.
- ^ Job D (November 2002). «Plant biotechnology in agriculture». Biochimie. 84 (11): 1105–10. doi:10.1016/S0300-9084(02)00013-5. PMID 12595138.
- ^ Curtis C, Hereward J (29 August 2017). «From the crime scene to the courtroom: the journey of a DNA sample». The Conversation. Archived from the original on 22 October 2017. Retrieved 22 October 2017.
- ^ Collins A, Morton NE (June 1994). «Likelihood ratios for DNA identification». Proceedings of the National Academy of Sciences of the United States of America. 91 (13): 6007–11. Bibcode:1994PNAS…91.6007C. doi:10.1073/pnas.91.13.6007. PMC 44126. PMID 8016106.
- ^ Weir BS, Triggs CM, Starling L, Stowell LI, Walsh KA, Buckleton J (March 1997). «Interpreting DNA mixtures» (PDF). Journal of Forensic Sciences. 42 (2): 213–22. doi:10.1520/JFS14100J. PMID 9068179. S2CID 14511630.
- ^ Jeffreys AJ, Wilson V, Thein SL (1985). «Individual-specific ‘fingerprints’ of human DNA». Nature. 316 (6023): 76–79. Bibcode:1985Natur.316…76J. doi:10.1038/316076a0. PMID 2989708. S2CID 4229883.
- ^ Colin Pitchfork – first murder conviction on DNA evidence also clears the prime suspect Forensic Science Service Accessed 23 December 2006
- ^ «DNA Identification in Mass Fatality Incidents». National Institute of Justice. September 2006. Archived from the original on 12 November 2006.
- ^ «Paternity Blood Tests That Work Early in a Pregnancy» New York Times June 20, 2012 Archived 24 June 2017 at the Wayback Machine
- ^ a b Breaker RR, Joyce GF (December 1994). «A DNA enzyme that cleaves RNA». Chemistry & Biology. 1 (4): 223–29. doi:10.1016/1074-5521(94)90014-0. PMID 9383394.
- ^ Chandra M, Sachdeva A, Silverman SK (October 2009). «DNA-catalyzed sequence-specific hydrolysis of DNA». Nature Chemical Biology. 5 (10): 718–20. doi:10.1038/nchembio.201. PMC 2746877. PMID 19684594.
- ^ Carmi N, Shultz LA, Breaker RR (December 1996). «In vitro selection of self-cleaving DNAs». Chemistry & Biology. 3 (12): 1039–46. doi:10.1016/S1074-5521(96)90170-2. PMID 9000012.
- ^ Torabi SF, Wu P, McGhee CE, Chen L, Hwang K, Zheng N, Cheng J, Lu Y (May 2015). «In vitro selection of a sodium-specific DNAzyme and its application in intracellular sensing». Proceedings of the National Academy of Sciences of the United States of America. 112 (19): 5903–08. Bibcode:2015PNAS..112.5903T. doi:10.1073/pnas.1420361112. PMC 4434688. PMID 25918425.
- ^ Baldi P, Brunak S (2001). Bioinformatics: The Machine Learning Approach. MIT Press. ISBN 978-0-262-02506-5. OCLC 45951728.
- ^ Gusfield D (15 January 1997). Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press. ISBN 978-0-521-58519-4.
- ^ Sjölander K (January 2004). «Phylogenomic inference of protein molecular function: advances and challenges». Bioinformatics. 20 (2): 170–79. CiteSeerX 10.1.1.412.943. doi:10.1093/bioinformatics/bth021. PMID 14734307.
- ^ Mount DM (2004). Bioinformatics: Sequence and Genome Analysis (2nd ed.). Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. ISBN 0-87969-712-1. OCLC 55106399.
- ^ Strong, Michael (2004). «Protein Nanomachines». PLOS Biology. 2 (3): e73. doi:10.1371/journal.pbio.0020073. PMC 368168. PMID 15024422. S2CID 13222080.
- ^ Rothemund PW (March 2006). «Folding DNA to create nanoscale shapes and patterns» (PDF). Nature. 440 (7082): 297–302. Bibcode:2006Natur.440..297R. doi:10.1038/nature04586. PMID 16541064. S2CID 4316391.
- ^ Andersen ES, Dong M, Nielsen MM, Jahn K, Subramani R, Mamdouh W, Golas MM, Sander B, Stark H, Oliveira CL, Pedersen JS, Birkedal V, Besenbacher F, Gothelf KV, Kjems J (May 2009). «Self-assembly of a nanoscale DNA box with a controllable lid». Nature. 459 (7243): 73–76. Bibcode:2009Natur.459…73A. doi:10.1038/nature07971. hdl:11858/00-001M-0000-0010-9362-B. PMID 19424153. S2CID 4430815.
- ^ Ishitsuka Y, Ha T (May 2009). «DNA nanotechnology: a nanomachine goes live». Nature Nanotechnology. 4 (5): 281–82. Bibcode:2009NatNa…4..281I. doi:10.1038/nnano.2009.101. PMID 19421208.
- ^ Aldaye FA, Palmer AL, Sleiman HF (September 2008). «Assembling materials with DNA as the guide». Science. 321 (5897): 1795–99. Bibcode:2008Sci…321.1795A. doi:10.1126/science.1154533. PMID 18818351. S2CID 2755388.
- ^ Dunn, Matthew; Jimenez, Randi; Chaput, John (2017). «Analysis of aptamer discovery and technology». Nature Reviews Chemistry. 1 (10). doi:10.1038/s41570-017-0076. Retrieved 30 June 2022.
- ^ Wray GA (2002). «Dating branches on the tree of life using DNA». Genome Biology. 3 (1): REVIEWS0001. doi:10.1186/gb-2001-3-1-reviews0001. PMC 150454. PMID 11806830.
- ^ Panda D, Molla KA, Baig MJ, Swain A, Behera D, Dash M (May 2018). «DNA as a digital information storage device: hope or hype?». 3 Biotech. 8 (5): 239. doi:10.1007/s13205-018-1246-7. PMC 5935598. PMID 29744271.
- ^ Akram F, Haq IU, Ali H, Laghari AT (October 2018). «Trends to store digital data in DNA: an overview». Molecular Biology Reports. 45 (5): 1479–1490. doi:10.1007/s11033-018-4280-y. PMID 30073589. S2CID 51905843.
- ^ Miescher F (1871). «Ueber die chemische Zusammensetzung der Eiterzellen» [On the chemical composition of pus cells]. Medicinisch-chemische Untersuchungen (in German). 4: 441–60.
[p. 456] Ich habe mich daher später mit meinen Versuchen an die ganzen Kerne gehalten, die Trennung der Körper, die ich einstweilen ohne weiteres Präjudiz als lösliches und unlösliches Nuclein bezeichnen will, einem günstigeren Material überlassend. (Therefore, in my experiments I subsequently limited myself to the whole nucleus, leaving to a more favorable material the separation of the substances, that for the present, without further prejudice, I will designate as soluble and insoluble nuclear material («Nuclein»))
- ^ Dahm R (January 2008). «Discovering DNA: Friedrich Miescher and the early years of nucleic acid research». Human Genetics. 122 (6): 565–81. doi:10.1007/s00439-007-0433-0. PMID 17901982. S2CID 915930.
- ^ See:
- Kossel A (1879). «Ueber Nucleïn der Hefe» [On nuclein in yeast]. Zeitschrift für physiologische Chemie (in German). 3: 284–91.
- Kossel A (1880). «Ueber Nucleïn der Hefe II» [On nuclein in yeast, Part 2]. Zeitschrift für physiologische Chemie (in German). 4: 290–95.
- Kossel A (1881). «Ueber die Verbreitung des Hypoxanthins im Thier- und Pflanzenreich» [On the distribution of hypoxanthins in the animal and plant kingdoms]. Zeitschrift für physiologische Chemie (in German). 5: 267–71.
- Kossel A (1881). Trübne KJ (ed.). Untersuchungen über die Nucleine und ihre Spaltungsprodukte [Investigations into nuclein and its cleavage products] (in German). Strassburg, Germany. p. 19.
- Kossel A (1882). «Ueber Xanthin und Hypoxanthin» [On xanthin and hypoxanthin]. Zeitschrift für physiologische Chemie. 6: 422–31.
- Albrect Kossel (1883) «Zur Chemie des Zellkerns» Archived 17 November 2017 at the Wayback Machine (On the chemistry of the cell nucleus), Zeitschrift für physiologische Chemie, 7 : 7–22.
- Kossel A (1886). «Weitere Beiträge zur Chemie des Zellkerns» [Further contributions to the chemistry of the cell nucleus]. Zeitschrift für Physiologische Chemie (in German). 10: 248–64.
On p. 264, Kossel remarked presciently: Der Erforschung der quantitativen Verhältnisse der vier stickstoffreichen Basen, der Abhängigkeit ihrer Menge von den physiologischen Zuständen der Zelle, verspricht wichtige Aufschlüsse über die elementaren physiologisch-chemischen Vorgänge. (The study of the quantitative relations of the four nitrogenous bases—[and] of the dependence of their quantity on the physiological states of the cell—promises important insights into the fundamental physiological-chemical processes.)
- ^ Jones ME (September 1953). «Albrecht Kossel, a biographical sketch». The Yale Journal of Biology and Medicine. 26 (1): 80–97. PMC 2599350. PMID 13103145.
- ^ Levene PA, Jacobs WA (1909). «Über Inosinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42: 1198–203. doi:10.1002/cber.190904201196.
- ^ Levene PA, Jacobs WA (1909). «Über die Hefe-Nucleinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42 (2): 2474–78. doi:10.1002/cber.190904202148.
- ^ Levene P (1919). «The structure of yeast nucleic acid». J Biol Chem. 40 (2): 415–24. doi:10.1016/S0021-9258(18)87254-4.
- ^ Cohen JS, Portugal FH (1974). «The search for the chemical structure of DNA» (PDF). Connecticut Medicine. 38 (10): 551–52, 554–57. PMID 4609088.
- ^ Koltsov proposed that a cell’s genetic information was encoded in a long chain of amino acids. See:
- Кольцов, Н. К. (12 December 1927). Физико-химические основы морфологии [The physical-chemical basis of morphology] (Speech). 3rd All-Union Meeting of Zoologist, Anatomists, and Histologists (in Russian). Leningrad, U.S.S.R.
- Reprinted in: Кольцов, Н. К. (1928). «Физико-химические основы морфологии» [The physical-chemical basis of morphology]. Успехи экспериментальной биологии (Advances in Experimental Biology) series B (in Russian). 7 (1): ?.
- Reprinted in German as: Koltzoff NK (1928). «Physikalisch-chemische Grundlagen der Morphologie» [The physical-chemical basis of morphology]. Biologisches Zentralblatt (in German). 48 (6): 345–69.
- In 1934, Koltsov contended that the proteins that contain a cell’s genetic information replicate. See: Koltzoff N (October 1934). «The structure of the chromosomes in the salivary glands of Drosophila». Science. 80 (2075): 312–13. Bibcode:1934Sci….80..312K. doi:10.1126/science.80.2075.312. PMID 17769043.
From page 313: «I think that the size of the chromosomes in the salivary glands [of Drosophila] is determined through the multiplication of genonemes. By this term I designate the axial thread of the chromosome, in which the geneticists locate the linear combination of genes; … In the normal chromosome there is usually only one genoneme; before cell-division this genoneme has become divided into two strands.»
- ^ Soyfer VN (September 2001). «The consequences of political dictatorship for Russian science». Nature Reviews Genetics. 2 (9): 723–29. doi:10.1038/35088598. PMID 11533721. S2CID 46277758.
- ^ Griffith F (January 1928). «The Significance of Pneumococcal Types». The Journal of Hygiene. 27 (2): 113–59. doi:10.1017/S0022172400031879. PMC 2167760. PMID 20474956.
- ^ Lorenz MG, Wackernagel W (September 1994). «Bacterial gene transfer by natural genetic transformation in the environment». Microbiological Reviews. 58 (3): 563–602. doi:10.1128/MMBR.58.3.563-602.1994. PMC 372978. PMID 7968924.
- ^ Brachet J (1933). «Recherches sur la synthese de l’acide thymonucleique pendant le developpement de l’oeuf d’Oursin». Archives de Biologie (in Italian). 44: 519–76.
- ^ Burian R (1994). «Jean Brachet’s Cytochemical Embryology: Connections with the Renovation of Biology in France?» (PDF). In Debru C, Gayon J, Picard JF (eds.). Les sciences biologiques et médicales en France 1920–1950. Cahiers pour I’histoire de la recherche. Vol. 2. Paris: CNRS Editions. pp. 207–20.
- ^ See:
- Astbury WT, Bell FO (1938). «Some recent developments in the X-ray study of proteins and related structures» (PDF). Cold Spring Harbor Symposia on Quantitative Biology. 6: 109–21. doi:10.1101/sqb.1938.006.01.013. Archived from the original (PDF) on 14 July 2014.
- Astbury WT (1947). «X-ray studies of nucleic acids». Symposia of the Society for Experimental Biology (1): 66–76. PMID 20257017. Archived from the original on 5 July 2014.
- ^ Avery OT, Macleod CM, McCarty M (February 1944). «Studies on the Chemical Nature of the Substance Inducing Transformation of Pneumococcal Types: Induction of Transformation by a Desoxyribonucleic Acid Fraction Isolated from Pneumococcus Type III». The Journal of Experimental Medicine. 79 (2): 137–58. doi:10.1084/jem.79.2.137. PMC 2135445. PMID 19871359.
- ^ Chargaff, Erwin (June 1950). «Chemical specificity of nucleic acids and mechanism of their enzymatic degradation». Experientia. 6 (6): 201–209. doi:10.1007/BF02173653. PMID 15421335. S2CID 2522535.
- ^ Kresge, Nicole; Simoni, Robert D.; Hill, Robert L. (June 2005). «Chargaff’s Rules: the Work of Erwin Chargaff». Journal of Biological Chemistry. 280 (24): 172–174. doi:10.1016/S0021-9258(20)61522-8.
- ^ Hershey AD, Chase M (May 1952). «Independent functions of viral protein and nucleic acid in growth of bacteriophage». The Journal of General Physiology. 36 (1): 39–56. doi:10.1085/jgp.36.1.39. PMC 2147348. PMID 12981234.
- ^ The B-DNA X-ray pattern on the right of this linked image Archived 10 July 2009 at the Wayback Machine
- ^ Schwartz J (2008). In pursuit of the gene : from Darwin to DNA. Cambridge, Mass.: Harvard University Press. ISBN 978-0-674-02670-4.
- ^ Pauling L, Corey RB (February 1953). «A Proposed Structure For The Nucleic Acids». Proceedings of the National Academy of Sciences of the United States of America. 39 (2): 84–97. Bibcode:1953PNAS…39…84P. doi:10.1073/pnas.39.2.84. PMC 1063734. PMID 16578429.
- ^ Regis E (2009). What Is Life?: investigating the nature of life in the age of synthetic biology. Oxford: Oxford University Press. p. 52. ISBN 978-0-19-538341-6.
- ^ «Double Helix of DNA: 50 Years». Nature Archives. Archived from the original on 5 April 2015.
- ^ «Original X-ray diffraction image». Oregon State Library. Archived from the original on 30 January 2009. Retrieved 6 February 2011.
- ^ «The Nobel Prize in Physiology or Medicine 1962». Nobelprize.org.
- ^ Maddox B (January 2003). «The double helix and the ‘wronged heroine’» (PDF). Nature. 421 (6921): 407–08. Bibcode:2003Natur.421..407M. doi:10.1038/nature01399. PMID 12540909. S2CID 4428347. Archived (PDF) from the original on 17 October 2016.
- ^ Crick F (1955). A Note for the RNA Tie Club (PDF) (Speech). Cambridge, England. Archived from the original (PDF) on 1 October 2008.
- ^ Meselson M, Stahl FW (July 1958). «The Replication of DNA in Escherichia Coli». Proceedings of the National Academy of Sciences of the United States of America. 44 (7): 671–82. Bibcode:1958PNAS…44..671M. doi:10.1073/pnas.44.7.671. PMC 528642. PMID 16590258.
- ^ «The Nobel Prize in Physiology or Medicine 1968». Nobelprize.org.
- ^ Pray L (2008). «Discovery of DNA structure and function: Watson and Crick». Nature Education. 1 (1): 100.
Further reading
- Berry A, Watson J (2003). DNA: the secret of life. New York: Alfred A. Knopf. ISBN 0-375-41546-7.
- Calladine CR, Drew HR, Luisi BF, Travers AA (2003). Understanding DNA: the molecule & how it works. Amsterdam: Elsevier Academic Press. ISBN 0-12-155089-3.
- Carina D, Clayton J (2003). 50 years of DNA. Basingstoke: Palgrave Macmillan. ISBN 1-4039-1479-6.
- Judson HF (1979). The Eighth Day of Creation: Makers of the Revolution in Biology (2nd ed.). Cold Spring Harbor Laboratory Press. ISBN 0-671-22540-5.
- Olby RC (1994). The path to the double helix: the discovery of DNA. New York: Dover Publications. ISBN 0-486-68117-3. First published in October 1974 by MacMillan, with foreword by Francis Crick; the definitive DNA textbook, revised in 1994 with a nine-page postscript.
- Olby R (January 2003). «Quiet debut for the double helix». Nature. 421 (6921): 402–05. Bibcode:2003Natur.421..402O. doi:10.1038/nature01397. PMID 12540907.
- Olby RC (2009). Francis Crick: A Biography. Plainview, N.Y: Cold Spring Harbor Laboratory Press. ISBN 978-0-87969-798-3.
- Micklas D (2003). DNA Science: A First Course. Cold Spring Harbor Press. ISBN 978-0-87969-636-8.
- Ridley M (2006). Francis Crick: discoverer of the genetic code. Ashland, OH: Eminent Lives, Atlas Books. ISBN 0-06-082333-X.
- Rosenfeld I (2010). DNA: A Graphic Guide to the Molecule that Shook the World. Columbia University Press. ISBN 978-0-231-14271-7.
- Schultz M, Cannon Z (2009). The Stuff of Life: A Graphic Guide to Genetics and DNA. Hill and Wang. ISBN 978-0-8090-8947-5.
- Stent GS, Watson J (1980). The Double Helix: A Personal Account of the Discovery of the Structure of DNA. New York: Norton. ISBN 0-393-95075-1.
- Watson J (2004). DNA: The Secret of Life. Random House. ISBN 978-0-09-945184-6.
- Wilkins M (2003). The third man of the double helix the autobiography of Maurice Wilkins. Cambridge, England: University Press. ISBN 0-19-860665-6.
External links
![]()
This audio file was created from a revision of this article dated 12 February 2007, and does not reflect subsequent edits.
- DNA at Curlie
- DNA binding site prediction on protein
- DNA the Double Helix Game From the official Nobel Prize web site
- DNA under electron microscope
- Dolan DNA Learning Center
- Double Helix: 50 years of DNA, Nature
- Proteopedia DNA
- Proteopedia Forms_of_DNA
- ENCODE threads explorer ENCODE home page at Nature
- Double Helix 1953–2003 National Centre for Biotechnology Education
- Genetic Education Modules for Teachers – DNA from the Beginning Study Guide
- PDB Molecule of the Month DNA
- «Clue to chemistry of heredity found». The New York Times, June 1953. First American newspaper coverage of the discovery of the DNA structure
- DNA from the Beginning Another DNA Learning Center site on DNA, genes, and heredity from Mendel to the human genome project.
- The Register of Francis Crick Personal Papers 1938 – 2007 at Mandeville Special Collections Library, University of California, San Diego
- Seven-page, handwritten letter that Crick sent to his 12-year-old son Michael in 1953 describing the structure of DNA. See Crick’s medal goes under the hammer, Nature, 5 April 2013.
Deoxyribonucleic acid (;[1] DNA) is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.
The two DNA strands are known as polynucleotides as they are composed of simpler monomeric units called nucleotides.[2][3] Each nucleotide is composed of one of four nitrogen-containing nucleobases (cytosine [C], guanine [G], adenine [A] or thymine [T]), a sugar called deoxyribose, and a phosphate group. The nucleotides are joined to one another in a chain by covalent bonds (known as the phosphodiester linkage) between the sugar of one nucleotide and the phosphate of the next, resulting in an alternating sugar-phosphate backbone. The nitrogenous bases of the two separate polynucleotide strands are bound together, according to base pairing rules (A with T and C with G), with hydrogen bonds to make double-stranded DNA. The complementary nitrogenous bases are divided into two groups, pyrimidines and purines. In DNA, the pyrimidines are thymine and cytosine; the purines are adenine and guanine.
Both strands of double-stranded DNA store the same biological information. This information is replicated when the two strands separate. A large part of DNA (more than 98% for humans) is non-coding, meaning that these sections do not serve as patterns for protein sequences. The two strands of DNA run in opposite directions to each other and are thus antiparallel. Attached to each sugar is one of four types of nucleobases (or bases). It is the sequence of these four nucleobases along the backbone that encodes genetic information. RNA strands are created using DNA strands as a template in a process called transcription, where DNA bases are exchanged for their corresponding bases except in the case of thymine (T), for which RNA substitutes uracil (U).[4] Under the genetic code, these RNA strands specify the sequence of amino acids within proteins in a process called translation.
Within eukaryotic cells, DNA is organized into long structures called chromosomes. Before typical cell division, these chromosomes are duplicated in the process of DNA replication, providing a complete set of chromosomes for each daughter cell. Eukaryotic organisms (animals, plants, fungi and protists) store most of their DNA inside the cell nucleus as nuclear DNA, and some in the mitochondria as mitochondrial DNA or in chloroplasts as chloroplast DNA.[5] In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm, in circular chromosomes. Within eukaryotic chromosomes, chromatin proteins, such as histones, compact and organize DNA. These compacting structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed.
Properties
Chemical structure of DNA; hydrogen bonds shown as dotted lines. Each end of the double helix has an exposed 5′ phosphate on one strand and an exposed 3′ hydroxyl group (—OH) on the other.
DNA is a long polymer made from repeating units called nucleotides.[6][7] The structure of DNA is dynamic along its length, being capable of coiling into tight loops and other shapes.[8] In all species it is composed of two helical chains, bound to each other by hydrogen bonds. Both chains are coiled around the same axis, and have the same pitch of 34 ångströms (3.4 nm). The pair of chains have a radius of 10 Å (1.0 nm).[9] According to another study, when measured in a different solution, the DNA chain measured 22–26 Å (2.2–2.6 nm) wide, and one nucleotide unit measured 3.3 Å (0.33 nm) long.[10]
DNA does not usually exist as a single strand, but instead as a pair of strands that are held tightly together.[9][11] These two long strands coil around each other, in the shape of a double helix. The nucleotide contains both a segment of the backbone of the molecule (which holds the chain together) and a nucleobase (which interacts with the other DNA strand in the helix). A nucleobase linked to a sugar is called a nucleoside, and a base linked to a sugar and to one or more phosphate groups is called a nucleotide. A biopolymer comprising multiple linked nucleotides (as in DNA) is called a polynucleotide.[12]
The backbone of the DNA strand is made from alternating phosphate and sugar groups.[13] The sugar in DNA is 2-deoxyribose, which is a pentose (five-carbon) sugar. The sugars are joined by phosphate groups that form phosphodiester bonds between the third and fifth carbon atoms of adjacent sugar rings. These are known as the 3′-end (three prime end), and 5′-end (five prime end) carbons, the prime symbol being used to distinguish these carbon atoms from those of the base to which the deoxyribose forms a glycosidic bond.[11]
Therefore, any DNA strand normally has one end at which there is a phosphate group attached to the 5′ carbon of a ribose (the 5′ phosphoryl) and another end at which there is a free hydroxyl group attached to the 3′ carbon of a ribose (the 3′ hydroxyl). The orientation of the 3′ and 5′ carbons along the sugar-phosphate backbone confers directionality (sometimes called polarity) to each DNA strand. In a nucleic acid double helix, the direction of the nucleotides in one strand is opposite to their direction in the other strand: the strands are antiparallel. The asymmetric ends of DNA strands are said to have a directionality of five prime end (5′ ), and three prime end (3′), with the 5′ end having a terminal phosphate group and the 3′ end a terminal hydroxyl group. One major difference between DNA and RNA is the sugar, with the 2-deoxyribose in DNA being replaced by the related pentose sugar ribose in RNA.[11]
A section of DNA. The bases lie horizontally between the two spiraling strands[14] (animated version).
The DNA double helix is stabilized primarily by two forces: hydrogen bonds between nucleotides and base-stacking interactions among aromatic nucleobases.[15] The four bases found in DNA are adenine (A), cytosine (C), guanine (G) and thymine (T). These four bases are attached to the sugar-phosphate to form the complete nucleotide, as shown for adenosine monophosphate. Adenine pairs with thymine and guanine pairs with cytosine, forming A-T and G-C base pairs.[16][17]
Nucleobase classification
The nucleobases are classified into two types: the purines, A and G, which are fused five- and six-membered heterocyclic compounds, and the pyrimidines, the six-membered rings C and T.[11] A fifth pyrimidine nucleobase, uracil (U), usually takes the place of thymine in RNA and differs from thymine by lacking a methyl group on its ring. In addition to RNA and DNA, many artificial nucleic acid analogues have been created to study the properties of nucleic acids, or for use in biotechnology.[18]
Non-canonical bases
Modified bases occur in DNA. The first of these recognized was 5-methylcytosine, which was found in the genome of Mycobacterium tuberculosis in 1925.[19] The reason for the presence of these noncanonical bases in bacterial viruses (bacteriophages) is to avoid the restriction enzymes present in bacteria. This enzyme system acts at least in part as a molecular immune system protecting bacteria from infection by viruses.[20] Modifications of the bases cytosine and adenine, the more common and modified DNA bases, play vital roles in the epigenetic control of gene expression in plants and animals.[21]
A number of noncanonical bases are known to occur in DNA.[22] Most of these are modifications of the canonical bases plus uracil.
- Modified Adenosine
- N6-carbamoyl-methyladenine
- N6-methyadenine
- Modified Guanine
- 7-Deazaguanine
- 7-Methylguanine
- Modified Cytosine
- N4-Methylcytosine
- 5-Carboxylcytosine
- 5-Formylcytosine
- 5-Glycosylhydroxymethylcytosine
- 5-Hydroxycytosine
- 5-Methylcytosine
- Modified Thymidine
- α-Glutamythymidine
- α-Putrescinylthymine
- Uracil and modifications
- Base J
- Uracil
- 5-Dihydroxypentauracil
- 5-Hydroxymethyldeoxyuracil
- Others
- Deoxyarchaeosine
- 2,6-Diaminopurine (2-Aminoadenine)
Grooves
DNA major and minor grooves. The latter is a binding site for the Hoechst stain dye 33258.
Twin helical strands form the DNA backbone. Another double helix may be found tracing the spaces, or grooves, between the strands. These voids are adjacent to the base pairs and may provide a binding site. As the strands are not symmetrically located with respect to each other, the grooves are unequally sized. The major groove is 22 ångströms (2.2 nm) wide, while the minor groove is 12 Å (1.2 nm) in width.[23] Due to the larger width of the major groove, the edges of the bases are more accessible in the major groove than in the minor groove. As a result, proteins such as transcription factors that can bind to specific sequences in double-stranded DNA usually make contact with the sides of the bases exposed in the major groove.[24] This situation varies in unusual conformations of DNA within the cell (see below), but the major and minor grooves are always named to reflect the differences in width that would be seen if the DNA was twisted back into the ordinary B form.
Base pairing
Top, a GC base pair with three hydrogen bonds. Bottom, an AT base pair with two hydrogen bonds. Non-covalent hydrogen bonds between the pairs are shown as dashed lines.
In a DNA double helix, each type of nucleobase on one strand bonds with just one type of nucleobase on the other strand. This is called complementary base pairing. Purines form hydrogen bonds to pyrimidines, with adenine bonding only to thymine in two hydrogen bonds, and cytosine bonding only to guanine in three hydrogen bonds. This arrangement of two nucleotides binding together across the double helix (from six-carbon ring to six-carbon ring) is called a Watson-Crick base pair. DNA with high GC-content is more stable than DNA with low GC-content. A Hoogsteen base pair (hydrogen bonding the 6-carbon ring to the 5-carbon ring) is a rare variation of base-pairing.[25] As hydrogen bonds are not covalent, they can be broken and rejoined relatively easily. The two strands of DNA in a double helix can thus be pulled apart like a zipper, either by a mechanical force or high temperature.[26] As a result of this base pair complementarity, all the information in the double-stranded sequence of a DNA helix is duplicated on each strand, which is vital in DNA replication. This reversible and specific interaction between complementary base pairs is critical for all the functions of DNA in organisms.[7]
ssDNA vs. dsDNA
As noted above, most DNA molecules are actually two polymer strands, bound together in a helical fashion by noncovalent bonds; this double-stranded (dsDNA) structure is maintained largely by the intrastrand base stacking interactions, which are strongest for G,C stacks. The two strands can come apart—a process known as melting—to form two single-stranded DNA (ssDNA) molecules. Melting occurs at high temperatures, low salt and high pH (low pH also melts DNA, but since DNA is unstable due to acid depurination, low pH is rarely used).
The stability of the dsDNA form depends not only on the GC-content (% G,C basepairs) but also on sequence (since stacking is sequence specific) and also length (longer molecules are more stable). The stability can be measured in various ways; a common way is the melting temperature (also called Tm value), which is the temperature at which 50% of the double-strand molecules are converted to single-strand molecules; melting temperature is dependent on ionic strength and the concentration of DNA. As a result, it is both the percentage of GC base pairs and the overall length of a DNA double helix that determines the strength of the association between the two strands of DNA. Long DNA helices with a high GC-content have more strongly interacting strands, while short helices with high AT content have more weakly interacting strands.[27] In biology, parts of the DNA double helix that need to separate easily, such as the TATAAT Pribnow box in some promoters, tend to have a high AT content, making the strands easier to pull apart.[28]
In the laboratory, the strength of this interaction can be measured by finding the melting temperature Tm necessary to break half of the hydrogen bonds. When all the base pairs in a DNA double helix melt, the strands separate and exist in solution as two entirely independent molecules. These single-stranded DNA molecules have no single common shape, but some conformations are more stable than others.[29]
Amount
In humans, the total female diploid nuclear genome per cell extends for 6.37 Gigabase pairs (Gbp), is 208.23 cm long and weighs 6.51 picograms (pg).[30] Male values are 6.27 Gbp, 205.00 cm, 6.41 pg.[30] Each DNA polymer can contain hundreds of millions of nucleotides, such as in chromosome 1. Chromosome 1 is the largest human chromosome with approximately 220 million base pairs, and would be 85 mm long if straightened.[31]
In eukaryotes, in addition to nuclear DNA, there is also mitochondrial DNA (mtDNA) which encodes certain proteins used by the mitochondria. The mtDNA is usually relatively small in comparison to the nuclear DNA. For example, the human mitochondrial DNA forms closed circular molecules, each of which contains 16,569[32][33] DNA base pairs,[34] with each such molecule normally containing a full set of the mitochondrial genes. Each human mitochondrion contains, on average, approximately 5 such mtDNA molecules.[34] Each human cell contains approximately 100 mitochondria, giving a total number of mtDNA molecules per human cell of approximately 500.[34] However, the amount of mitochondria per cell also varies by cell type, and an egg cell can contain 100,000 mitochondria, corresponding to up to 1,500,000 copies of the mitochondrial genome (constituting up to 90% of the DNA of the cell).[35]
Sense and antisense
A DNA sequence is called a «sense» sequence if it is the same as that of a messenger RNA copy that is translated into protein.[36] The sequence on the opposite strand is called the «antisense» sequence. Both sense and antisense sequences can exist on different parts of the same strand of DNA (i.e. both strands can contain both sense and antisense sequences). In both prokaryotes and eukaryotes, antisense RNA sequences are produced, but the functions of these RNAs are not entirely clear.[37] One proposal is that antisense RNAs are involved in regulating gene expression through RNA-RNA base pairing.[38]
A few DNA sequences in prokaryotes and eukaryotes, and more in plasmids and viruses, blur the distinction between sense and antisense strands by having overlapping genes.[39] In these cases, some DNA sequences do double duty, encoding one protein when read along one strand, and a second protein when read in the opposite direction along the other strand. In bacteria, this overlap may be involved in the regulation of gene transcription,[40] while in viruses, overlapping genes increase the amount of information that can be encoded within the small viral genome.[41]
Supercoiling
DNA can be twisted like a rope in a process called DNA supercoiling. With DNA in its «relaxed» state, a strand usually circles the axis of the double helix once every 10.4 base pairs, but if the DNA is twisted the strands become more tightly or more loosely wound.[42] If the DNA is twisted in the direction of the helix, this is positive supercoiling, and the bases are held more tightly together. If they are twisted in the opposite direction, this is negative supercoiling, and the bases come apart more easily. In nature, most DNA has slight negative supercoiling that is introduced by enzymes called topoisomerases.[43] These enzymes are also needed to relieve the twisting stresses introduced into DNA strands during processes such as transcription and DNA replication.[44]
Alternative DNA structures
From left to right, the structures of A, B and Z-DNA
DNA exists in many possible conformations that include A-DNA, B-DNA, and Z-DNA forms, although only B-DNA and Z-DNA have been directly observed in functional organisms.[13] The conformation that DNA adopts depends on the hydration level, DNA sequence, the amount and direction of supercoiling, chemical modifications of the bases, the type and concentration of metal ions, and the presence of polyamines in solution.[45]
The first published reports of A-DNA X-ray diffraction patterns—and also B-DNA—used analyses based on Patterson functions that provided only a limited amount of structural information for oriented fibers of DNA.[46][47] An alternative analysis was proposed by Wilkins et al. in 1953 for the in vivo B-DNA X-ray diffraction-scattering patterns of highly hydrated DNA fibers in terms of squares of Bessel functions.[48] In the same journal, James Watson and Francis Crick presented their molecular modeling analysis of the DNA X-ray diffraction patterns to suggest that the structure was a double helix.[9]
Although the B-DNA form is most common under the conditions found in cells,[49] it is not a well-defined conformation but a family of related DNA conformations[50] that occur at the high hydration levels present in cells. Their corresponding X-ray diffraction and scattering patterns are characteristic of molecular paracrystals with a significant degree of disorder.[51][52]
Compared to B-DNA, the A-DNA form is a wider right-handed spiral, with a shallow, wide minor groove and a narrower, deeper major groove. The A form occurs under non-physiological conditions in partly dehydrated samples of DNA, while in the cell it may be produced in hybrid pairings of DNA and RNA strands, and in enzyme-DNA complexes.[53][54] Segments of DNA where the bases have been chemically modified by methylation may undergo a larger change in conformation and adopt the Z form. Here, the strands turn about the helical axis in a left-handed spiral, the opposite of the more common B form.[55] These unusual structures can be recognized by specific Z-DNA binding proteins and may be involved in the regulation of transcription.[56]
Alternative DNA chemistry
For many years, exobiologists have proposed the existence of a shadow biosphere, a postulated microbial biosphere of Earth that uses radically different biochemical and molecular processes than currently known life. One of the proposals was the existence of lifeforms that use arsenic instead of phosphorus in DNA. A report in 2010 of the possibility in the bacterium GFAJ-1 was announced,[57][58] though the research was disputed,[58][59] and evidence suggests the bacterium actively prevents the incorporation of arsenic into the DNA backbone and other biomolecules.[60]
Quadruplex structures
DNA quadruplex formed by telomere repeats. The looped conformation of the DNA backbone is very different from the typical DNA helix. The green spheres in the center represent potassium ions.[61]
At the ends of the linear chromosomes are specialized regions of DNA called telomeres. The main function of these regions is to allow the cell to replicate chromosome ends using the enzyme telomerase, as the enzymes that normally replicate DNA cannot copy the extreme 3′ ends of chromosomes.[62] These specialized chromosome caps also help protect the DNA ends, and stop the DNA repair systems in the cell from treating them as damage to be corrected.[63] In human cells, telomeres are usually lengths of single-stranded DNA containing several thousand repeats of a simple TTAGGG sequence.[64]
These guanine-rich sequences may stabilize chromosome ends by forming structures of stacked sets of four-base units, rather than the usual base pairs found in other DNA molecules. Here, four guanine bases, known as a guanine tetrad, form a flat plate. These flat four-base units then stack on top of each other to form a stable G-quadruplex structure.[65] These structures are stabilized by hydrogen bonding between the edges of the bases and chelation of a metal ion in the centre of each four-base unit.[66] Other structures can also be formed, with the central set of four bases coming from either a single strand folded around the bases, or several different parallel strands, each contributing one base to the central structure.
In addition to these stacked structures, telomeres also form large loop structures called telomere loops, or T-loops. Here, the single-stranded DNA curls around in a long circle stabilized by telomere-binding proteins.[67] At the very end of the T-loop, the single-stranded telomere DNA is held onto a region of double-stranded DNA by the telomere strand disrupting the double-helical DNA and base pairing to one of the two strands. This triple-stranded structure is called a displacement loop or D-loop.[65]
Branched DNA can form networks containing multiple branches.
Branched DNA
In DNA, fraying occurs when non-complementary regions exist at the end of an otherwise complementary double-strand of DNA. However, branched DNA can occur if a third strand of DNA is introduced and contains adjoining regions able to hybridize with the frayed regions of the pre-existing double-strand. Although the simplest example of branched DNA involves only three strands of DNA, complexes involving additional strands and multiple branches are also possible.[68] Branched DNA can be used in nanotechnology to construct geometric shapes, see the section on uses in technology below.
Artificial bases
Several artificial nucleobases have been synthesized, and successfully incorporated in the eight-base DNA analogue named Hachimoji DNA. Dubbed S, B, P, and Z, these artificial bases are capable of bonding with each other in a predictable way (S–B and P–Z), maintain the double helix structure of DNA, and be transcribed to RNA. Their existence could be seen as an indication that there is nothing special about the four natural nucleobases that evolved on Earth.[69][70] On the other hand, DNA is tightly related to RNA which does not only act as a transcript of DNA but also performs as moleular machines many tasks in cells. For this purpose it has to fold into a structure. It has been shown that to allow to create all possible structures at least four bases are required for the corresponding RNA,[71] while a higher number is also possible but this would be against the natural principle of least effort.
Acidity
The phosphate groups of DNA give it similar acidic properties to phosphoric acid and it can be considered as a strong acid. It will be fully ionized at a normal cellular pH, releasing protons which leave behind negative charges on the phosphate groups. These negative charges protect DNA from breakdown by hydrolysis by repelling nucleophiles which could hydrolyze it.[72]
Macroscopic appearance
Impure DNA extracted from an orange
Pure DNA extracted from cells forms white, stringy clumps.[73]
Chemical modifications and altered DNA packaging
Structure of cytosine with and without the 5-methyl group. Deamination converts 5-methylcytosine into thymine.
Base modifications and DNA packaging
The expression of genes is influenced by how the DNA is packaged in chromosomes, in a structure called chromatin. Base modifications can be involved in packaging, with regions that have low or no gene expression usually containing high levels of methylation of cytosine bases. DNA packaging and its influence on gene expression can also occur by covalent modifications of the histone protein core around which DNA is wrapped in the chromatin structure or else by remodeling carried out by chromatin remodeling complexes (see Chromatin remodeling). There is, further, crosstalk between DNA methylation and histone modification, so they can coordinately affect chromatin and gene expression.[74]
For one example, cytosine methylation produces 5-methylcytosine, which is important for X-inactivation of chromosomes.[75] The average level of methylation varies between organisms—the worm Caenorhabditis elegans lacks cytosine methylation, while vertebrates have higher levels, with up to 1% of their DNA containing 5-methylcytosine.[76] Despite the importance of 5-methylcytosine, it can deaminate to leave a thymine base, so methylated cytosines are particularly prone to mutations.[77] Other base modifications include adenine methylation in bacteria, the presence of 5-hydroxymethylcytosine in the brain,[78] and the glycosylation of uracil to produce the «J-base» in kinetoplastids.[79][80]
Damage
DNA can be damaged by many sorts of mutagens, which change the DNA sequence. Mutagens include oxidizing agents, alkylating agents and also high-energy electromagnetic radiation such as ultraviolet light and X-rays. The type of DNA damage produced depends on the type of mutagen. For example, UV light can damage DNA by producing thymine dimers, which are cross-links between pyrimidine bases.[82] On the other hand, oxidants such as free radicals or hydrogen peroxide produce multiple forms of damage, including base modifications, particularly of guanosine, and double-strand breaks.[83] A typical human cell contains about 150,000 bases that have suffered oxidative damage.[84] Of these oxidative lesions, the most dangerous are double-strand breaks, as these are difficult to repair and can produce point mutations, insertions, deletions from the DNA sequence, and chromosomal translocations.[85] These mutations can cause cancer. Because of inherent limits in the DNA repair mechanisms, if humans lived long enough, they would all eventually develop cancer.[86][87] DNA damages that are naturally occurring, due to normal cellular processes that produce reactive oxygen species, the hydrolytic activities of cellular water, etc., also occur frequently. Although most of these damages are repaired, in any cell some DNA damage may remain despite the action of repair processes. These remaining DNA damages accumulate with age in mammalian postmitotic tissues. This accumulation appears to be an important underlying cause of aging.[88][89][90]
Many mutagens fit into the space between two adjacent base pairs, this is called intercalation. Most intercalators are aromatic and planar molecules; examples include ethidium bromide, acridines, daunomycin, and doxorubicin. For an intercalator to fit between base pairs, the bases must separate, distorting the DNA strands by unwinding of the double helix. This inhibits both transcription and DNA replication, causing toxicity and mutations.[91] As a result, DNA intercalators may be carcinogens, and in the case of thalidomide, a teratogen.[92] Others such as benzo[a]pyrene diol epoxide and aflatoxin form DNA adducts that induce errors in replication.[93] Nevertheless, due to their ability to inhibit DNA transcription and replication, other similar toxins are also used in chemotherapy to inhibit rapidly growing cancer cells.[94]
Biological functions
Location of eukaryote nuclear DNA within the chromosomes
DNA usually occurs as linear chromosomes in eukaryotes, and circular chromosomes in prokaryotes. The set of chromosomes in a cell makes up its genome; the human genome has approximately 3 billion base pairs of DNA arranged into 46 chromosomes.[95] The information carried by DNA is held in the sequence of pieces of DNA called genes. Transmission of genetic information in genes is achieved via complementary base pairing. For example, in transcription, when a cell uses the information in a gene, the DNA sequence is copied into a complementary RNA sequence through the attraction between the DNA and the correct RNA nucleotides. Usually, this RNA copy is then used to make a matching protein sequence in a process called translation, which depends on the same interaction between RNA nucleotides. In an alternative fashion, a cell may copy its genetic information in a process called DNA replication. The details of these functions are covered in other articles; here the focus is on the interactions between DNA and other molecules that mediate the function of the genome.
Genes and genomes
Genomic DNA is tightly and orderly packed in the process called DNA condensation, to fit the small available volumes of the cell. In eukaryotes, DNA is located in the cell nucleus, with small amounts in mitochondria and chloroplasts. In prokaryotes, the DNA is held within an irregularly shaped body in the cytoplasm called the nucleoid.[96] The genetic information in a genome is held within genes, and the complete set of this information in an organism is called its genotype. A gene is a unit of heredity and is a region of DNA that influences a particular characteristic in an organism. Genes contain an open reading frame that can be transcribed, and regulatory sequences such as promoters and enhancers, which control transcription of the open reading frame.
In many species, only a small fraction of the total sequence of the genome encodes protein. For example, only about 1.5% of the human genome consists of protein-coding exons, with over 50% of human DNA consisting of non-coding repetitive sequences.[97] The reasons for the presence of so much noncoding DNA in eukaryotic genomes and the extraordinary differences in genome size, or C-value, among species, represent a long-standing puzzle known as the «C-value enigma».[98] However, some DNA sequences that do not code protein may still encode functional non-coding RNA molecules, which are involved in the regulation of gene expression.[99]
Some noncoding DNA sequences play structural roles in chromosomes. Telomeres and centromeres typically contain few genes but are important for the function and stability of chromosomes.[63][101] An abundant form of noncoding DNA in humans are pseudogenes, which are copies of genes that have been disabled by mutation.[102] These sequences are usually just molecular fossils, although they can occasionally serve as raw genetic material for the creation of new genes through the process of gene duplication and divergence.[103]
Transcription and translation
A gene is a sequence of DNA that contains genetic information and can influence the phenotype of an organism. Within a gene, the sequence of bases along a DNA strand defines a messenger RNA sequence, which then defines one or more protein sequences. The relationship between the nucleotide sequences of genes and the amino-acid sequences of proteins is determined by the rules of translation, known collectively as the genetic code. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (e.g. ACT, CAG, TTT).
In transcription, the codons of a gene are copied into messenger RNA by RNA polymerase. This RNA copy is then decoded by a ribosome that reads the RNA sequence by base-pairing the messenger RNA to transfer RNA, which carries amino acids. Since there are 4 bases in 3-letter combinations, there are 64 possible codons (43 combinations). These encode the twenty standard amino acids, giving most amino acids more than one possible codon. There are also three ‘stop’ or ‘nonsense’ codons signifying the end of the coding region; these are the TAG, TAA, and TGA codons, (UAG, UAA, and UGA on the mRNA).
Replication
Cell division is essential for an organism to grow, but, when a cell divides, it must replicate the DNA in its genome so that the two daughter cells have the same genetic information as their parent. The double-stranded structure of DNA provides a simple mechanism for DNA replication. Here, the two strands are separated and then each strand’s complementary DNA sequence is recreated by an enzyme called DNA polymerase. This enzyme makes the complementary strand by finding the correct base through complementary base pairing and bonding it onto the original strand. As DNA polymerases can only extend a DNA strand in a 5′ to 3′ direction, different mechanisms are used to copy the antiparallel strands of the double helix.[104] In this way, the base on the old strand dictates which base appears on the new strand, and the cell ends up with a perfect copy of its DNA.
Naked extracellular DNA (eDNA), most of it released by cell death, is nearly ubiquitous in the environment. Its concentration in soil may be as high as 2 μg/L, and its concentration in natural aquatic environments may be as high at 88 μg/L.[105] Various possible functions have been proposed for eDNA: it may be involved in horizontal gene transfer;[106] it may provide nutrients;[107] and it may act as a buffer to recruit or titrate ions or antibiotics.[108] Extracellular DNA acts as a functional extracellular matrix component in the biofilms of several bacterial species. It may act as a recognition factor to regulate the attachment and dispersal of specific cell types in the biofilm;[109] it may contribute to biofilm formation;[110] and it may contribute to the biofilm’s physical strength and resistance to biological stress.[111]
Cell-free fetal DNA is found in the blood of the mother, and can be sequenced to determine a great deal of information about the developing fetus.[112]
Under the name of environmental DNA eDNA has seen increased use in the natural sciences as a survey tool for ecology, monitoring the movements and presence of species in water, air, or on land, and assessing an area’s biodiversity.[113][114]
Neutrophil extracellular traps (NETs) are networks of extracellular fibers, primarily composed of DNA, which allow neutrophils, a type of white blood cell, to kill extracellular pathogens while minimizing damage to the host cells.
Interactions with proteins
All the functions of DNA depend on interactions with proteins. These protein interactions can be non-specific, or the protein can bind specifically to a single DNA sequence. Enzymes can also bind to DNA and of these, the polymerases that copy the DNA base sequence in transcription and DNA replication are particularly important.
DNA-binding proteins
Interaction of DNA (in orange) with histones (in blue). These proteins’ basic amino acids bind to the acidic phosphate groups on DNA.
Structural proteins that bind DNA are well-understood examples of non-specific DNA-protein interactions. Within chromosomes, DNA is held in complexes with structural proteins. These proteins organize the DNA into a compact structure called chromatin. In eukaryotes, this structure involves DNA binding to a complex of small basic proteins called histones, while in prokaryotes multiple types of proteins are involved.[115][116] The histones form a disk-shaped complex called a nucleosome, which contains two complete turns of double-stranded DNA wrapped around its surface. These non-specific interactions are formed through basic residues in the histones, making ionic bonds to the acidic sugar-phosphate backbone of the DNA, and are thus largely independent of the base sequence.[117] Chemical modifications of these basic amino acid residues include methylation, phosphorylation, and acetylation.[118] These chemical changes alter the strength of the interaction between the DNA and the histones, making the DNA more or less accessible to transcription factors and changing the rate of transcription.[119] Other non-specific DNA-binding proteins in chromatin include the high-mobility group proteins, which bind to bent or distorted DNA.[120] These proteins are important in bending arrays of nucleosomes and arranging them into the larger structures that make up chromosomes.[121]
A distinct group of DNA-binding proteins is the DNA-binding proteins that specifically bind single-stranded DNA. In humans, replication protein A is the best-understood member of this family and is used in processes where the double helix is separated, including DNA replication, recombination, and DNA repair.[122] These binding proteins seem to stabilize single-stranded DNA and protect it from forming stem-loops or being degraded by nucleases.
In contrast, other proteins have evolved to bind to particular DNA sequences. The most intensively studied of these are the various transcription factors, which are proteins that regulate transcription. Each transcription factor binds to one particular set of DNA sequences and activates or inhibits the transcription of genes that have these sequences close to their promoters. The transcription factors do this in two ways. Firstly, they can bind the RNA polymerase responsible for transcription, either directly or through other mediator proteins; this locates the polymerase at the promoter and allows it to begin transcription.[124] Alternatively, transcription factors can bind enzymes that modify the histones at the promoter. This changes the accessibility of the DNA template to the polymerase.[125]
As these DNA targets can occur throughout an organism’s genome, changes in the activity of one type of transcription factor can affect thousands of genes.[126] Consequently, these proteins are often the targets of the signal transduction processes that control responses to environmental changes or cellular differentiation and development. The specificity of these transcription factors’ interactions with DNA come from the proteins making multiple contacts to the edges of the DNA bases, allowing them to «read» the DNA sequence. Most of these base-interactions are made in the major groove, where the bases are most accessible.[24]
DNA-modifying enzymes
Nucleases and ligases
Nucleases are enzymes that cut DNA strands by catalyzing the hydrolysis of the phosphodiester bonds. Nucleases that hydrolyse nucleotides from the ends of DNA strands are called exonucleases, while endonucleases cut within strands. The most frequently used nucleases in molecular biology are the restriction endonucleases, which cut DNA at specific sequences. For instance, the EcoRV enzyme shown to the left recognizes the 6-base sequence 5′-GATATC-3′ and makes a cut at the horizontal line. In nature, these enzymes protect bacteria against phage infection by digesting the phage DNA when it enters the bacterial cell, acting as part of the restriction modification system.[128] In technology, these sequence-specific nucleases are used in molecular cloning and DNA fingerprinting.
Enzymes called DNA ligases can rejoin cut or broken DNA strands.[129] Ligases are particularly important in lagging strand DNA replication, as they join the short segments of DNA produced at the replication fork into a complete copy of the DNA template. They are also used in DNA repair and genetic recombination.[129]
Topoisomerases and helicases
Topoisomerases are enzymes with both nuclease and ligase activity. These proteins change the amount of supercoiling in DNA. Some of these enzymes work by cutting the DNA helix and allowing one section to rotate, thereby reducing its level of supercoiling; the enzyme then seals the DNA break.[43] Other types of these enzymes are capable of cutting one DNA helix and then passing a second strand of DNA through this break, before rejoining the helix.[130] Topoisomerases are required for many processes involving DNA, such as DNA replication and transcription.[44]
Helicases are proteins that are a type of molecular motor. They use the chemical energy in nucleoside triphosphates, predominantly adenosine triphosphate (ATP), to break hydrogen bonds between bases and unwind the DNA double helix into single strands.[131] These enzymes are essential for most processes where enzymes need to access the DNA bases.
Polymerases
Polymerases are enzymes that synthesize polynucleotide chains from nucleoside triphosphates. The sequence of their products is created based on existing polynucleotide chains—which are called templates. These enzymes function by repeatedly adding a nucleotide to the 3′ hydroxyl group at the end of the growing polynucleotide chain. As a consequence, all polymerases work in a 5′ to 3′ direction.[132] In the active site of these enzymes, the incoming nucleoside triphosphate base-pairs to the template: this allows polymerases to accurately synthesize the complementary strand of their template. Polymerases are classified according to the type of template that they use.
In DNA replication, DNA-dependent DNA polymerases make copies of DNA polynucleotide chains. To preserve biological information, it is essential that the sequence of bases in each copy are precisely complementary to the sequence of bases in the template strand. Many DNA polymerases have a proofreading activity. Here, the polymerase recognizes the occasional mistakes in the synthesis reaction by the lack of base pairing between the mismatched nucleotides. If a mismatch is detected, a 3′ to 5′ exonuclease activity is activated and the incorrect base removed.[133] In most organisms, DNA polymerases function in a large complex called the replisome that contains multiple accessory subunits, such as the DNA clamp or helicases.[134]
RNA-dependent DNA polymerases are a specialized class of polymerases that copy the sequence of an RNA strand into DNA. They include reverse transcriptase, which is a viral enzyme involved in the infection of cells by retroviruses, and telomerase, which is required for the replication of telomeres.[62][135] For example, HIV reverse transcriptase is an enzyme for AIDS virus replication.[135] Telomerase is an unusual polymerase because it contains its own RNA template as part of its structure. It synthesizes telomeres at the ends of chromosomes. Telomeres prevent fusion of the ends of neighboring chromosomes and protect chromosome ends from damage.[63]
Transcription is carried out by a DNA-dependent RNA polymerase that copies the sequence of a DNA strand into RNA. To begin transcribing a gene, the RNA polymerase binds to a sequence of DNA called a promoter and separates the DNA strands. It then copies the gene sequence into a messenger RNA transcript until it reaches a region of DNA called the terminator, where it halts and detaches from the DNA. As with human DNA-dependent DNA polymerases, RNA polymerase II, the enzyme that transcribes most of the genes in the human genome, operates as part of a large protein complex with multiple regulatory and accessory subunits.[136]
Genetic recombination
A current model of meiotic recombination, initiated by a double-strand break or gap, followed by pairing with an homologous chromosome and strand invasion to initiate the recombinational repair process. Repair of the gap can lead to crossover (CO) or non-crossover (NCO) of the flanking regions. CO recombination is thought to occur by the Double Holliday Junction (DHJ) model, illustrated on the right, above. NCO recombinants are thought to occur primarily by the Synthesis Dependent Strand Annealing (SDSA) model, illustrated on the left, above. Most recombination events appear to be the SDSA type.
A DNA helix usually does not interact with other segments of DNA, and in human cells, the different chromosomes even occupy separate areas in the nucleus called «chromosome territories».[138] This physical separation of different chromosomes is important for the ability of DNA to function as a stable repository for information, as one of the few times chromosomes interact is in chromosomal crossover which occurs during sexual reproduction, when genetic recombination occurs. Chromosomal crossover is when two DNA helices break, swap a section and then rejoin.
Recombination allows chromosomes to exchange genetic information and produces new combinations of genes, which increases the efficiency of natural selection and can be important in the rapid evolution of new proteins.[139] Genetic recombination can also be involved in DNA repair, particularly in the cell’s response to double-strand breaks.[140]
The most common form of chromosomal crossover is homologous recombination, where the two chromosomes involved share very similar sequences. Non-homologous recombination can be damaging to cells, as it can produce chromosomal translocations and genetic abnormalities. The recombination reaction is catalyzed by enzymes known as recombinases, such as RAD51.[141] The first step in recombination is a double-stranded break caused by either an endonuclease or damage to the DNA.[142] A series of steps catalyzed in part by the recombinase then leads to joining of the two helices by at least one Holliday junction, in which a segment of a single strand in each helix is annealed to the complementary strand in the other helix. The Holliday junction is a tetrahedral junction structure that can be moved along the pair of chromosomes, swapping one strand for another. The recombination reaction is then halted by cleavage of the junction and re-ligation of the released DNA.[143] Only strands of like polarity exchange DNA during recombination. There are two types of cleavage: east-west cleavage and north–south cleavage. The north–south cleavage nicks both strands of DNA, while the east–west cleavage has one strand of DNA intact. The formation of a Holliday junction during recombination makes it possible for genetic diversity, genes to exchange on chromosomes, and expression of wild-type viral genomes.
Evolution
DNA contains the genetic information that allows all forms of life to function, grow and reproduce. However, it is unclear how long in the 4-billion-year history of life DNA has performed this function, as it has been proposed that the earliest forms of life may have used RNA as their genetic material.[144][145] RNA may have acted as the central part of early cell metabolism as it can both transmit genetic information and carry out catalysis as part of ribozymes.[146] This ancient RNA world where nucleic acid would have been used for both catalysis and genetics may have influenced the evolution of the current genetic code based on four nucleotide bases. This would occur, since the number of different bases in such an organism is a trade-off between a small number of bases increasing replication accuracy and a large number of bases increasing the catalytic efficiency of ribozymes.[147] However, there is no direct evidence of ancient genetic systems, as recovery of DNA from most fossils is impossible because DNA survives in the environment for less than one million years, and slowly degrades into short fragments in solution.[148] Claims for older DNA have been made, most notably a report of the isolation of a viable bacterium from a salt crystal 250 million years old,[149] but these claims are controversial.[150][151]
Building blocks of DNA (adenine, guanine, and related organic molecules) may have been formed extraterrestrially in outer space.[152][153][154] Complex DNA and RNA organic compounds of life, including uracil, cytosine, and thymine, have also been formed in the laboratory under conditions mimicking those found in outer space, using starting chemicals, such as pyrimidine, found in meteorites. Pyrimidine, like polycyclic aromatic hydrocarbons (PAHs), the most carbon-rich chemical found in the universe, may have been formed in red giants or in interstellar cosmic dust and gas clouds.[155]
In February 2021, scientists reported, for the first time, the sequencing of DNA from animal remains, a mammoth in this instance over a million years old, the oldest DNA sequenced to date.[156][157]
Uses in technology
Genetic engineering
Methods have been developed to purify DNA from organisms, such as phenol-chloroform extraction, and to manipulate it in the laboratory, such as restriction digests and the polymerase chain reaction. Modern biology and biochemistry make intensive use of these techniques in recombinant DNA technology. Recombinant DNA is a man-made DNA sequence that has been assembled from other DNA sequences. They can be transformed into organisms in the form of plasmids or in the appropriate format, by using a viral vector.[158] The genetically modified organisms produced can be used to produce products such as recombinant proteins, used in medical research,[159] or be grown in agriculture.[160][161]
DNA profiling
Forensic scientists can use DNA in blood, semen, skin, saliva or hair found at a crime scene to identify a matching DNA of an individual, such as a perpetrator.[162] This process is formally termed DNA profiling, also called DNA fingerprinting. In DNA profiling, the lengths of variable sections of repetitive DNA, such as short tandem repeats and minisatellites, are compared between people. This method is usually an extremely reliable technique for identifying a matching DNA.[163] However, identification can be complicated if the scene is contaminated with DNA from several people.[164] DNA profiling was developed in 1984 by British geneticist Sir Alec Jeffreys,[165] and first used in forensic science to convict Colin Pitchfork in the 1988 Enderby murders case.[166]
The development of forensic science and the ability to now obtain genetic matching on minute samples of blood, skin, saliva, or hair has led to re-examining many cases. Evidence can now be uncovered that was scientifically impossible at the time of the original examination. Combined with the removal of the double jeopardy law in some places, this can allow cases to be reopened where prior trials have failed to produce sufficient evidence to convince a jury. People charged with serious crimes may be required to provide a sample of DNA for matching purposes. The most obvious defense to DNA matches obtained forensically is to claim that cross-contamination of evidence has occurred. This has resulted in meticulous strict handling procedures with new cases of serious crime.
DNA profiling is also used successfully to positively identify victims of mass casualty incidents,[167] bodies or body parts in serious accidents, and individual victims in mass war graves, via matching to family members.
DNA profiling is also used in DNA paternity testing to determine if someone is the biological parent or grandparent of a child with the probability of parentage is typically 99.99% when the alleged parent is biologically related to the child. Normal DNA sequencing methods happen after birth, but there are new methods to test paternity while a mother is still pregnant.[168]
DNA enzymes or catalytic DNA
Deoxyribozymes, also called DNAzymes or catalytic DNA, were first discovered in 1994.[169] They are mostly single stranded DNA sequences isolated from a large pool of random DNA sequences through a combinatorial approach called in vitro selection or systematic evolution of ligands by exponential enrichment (SELEX). DNAzymes catalyze variety of chemical reactions including RNA-DNA cleavage, RNA-DNA ligation, amino acids phosphorylation-dephosphorylation, carbon-carbon bond formation, etc. DNAzymes can enhance catalytic rate of chemical reactions up to 100,000,000,000-fold over the uncatalyzed reaction.[170] The most extensively studied class of DNAzymes is RNA-cleaving types which have been used to detect different metal ions and designing therapeutic agents. Several metal-specific DNAzymes have been reported including the GR-5 DNAzyme (lead-specific),[169] the CA1-3 DNAzymes (copper-specific),[171] the 39E DNAzyme (uranyl-specific) and the NaA43 DNAzyme (sodium-specific).[172] The NaA43 DNAzyme, which is reported to be more than 10,000-fold selective for sodium over other metal ions, was used to make a real-time sodium sensor in cells.
Bioinformatics
Bioinformatics involves the development of techniques to store, data mine, search and manipulate biological data, including DNA nucleic acid sequence data. These have led to widely applied advances in computer science, especially string searching algorithms, machine learning, and database theory.[173] String searching or matching algorithms, which find an occurrence of a sequence of letters inside a larger sequence of letters, were developed to search for specific sequences of nucleotides.[174] The DNA sequence may be aligned with other DNA sequences to identify homologous sequences and locate the specific mutations that make them distinct. These techniques, especially multiple sequence alignment, are used in studying phylogenetic relationships and protein function.[175] Data sets representing entire genomes’ worth of DNA sequences, such as those produced by the Human Genome Project, are difficult to use without the annotations that identify the locations of genes and regulatory elements on each chromosome. Regions of DNA sequence that have the characteristic patterns associated with protein- or RNA-coding genes can be identified by gene finding algorithms, which allow researchers to predict the presence of particular gene products and their possible functions in an organism even before they have been isolated experimentally.[176] Entire genomes may also be compared, which can shed light on the evolutionary history of particular organism and permit the examination of complex evolutionary events.
DNA nanotechnology
DNA nanotechnology uses the unique molecular recognition properties of DNA and other nucleic acids to create self-assembling branched DNA complexes with useful properties.[178] DNA is thus used as a structural material rather than as a carrier of biological information. This has led to the creation of two-dimensional periodic lattices (both tile-based and using the DNA origami method) and three-dimensional structures in the shapes of polyhedra.[179] Nanomechanical devices and algorithmic self-assembly have also been demonstrated,[180] and these DNA structures have been used to template the arrangement of other molecules such as gold nanoparticles and streptavidin proteins.[181] DNA and other nucleic acids are the basis of aptamers, synthetic oligonucleotide ligands for specific target molecules used in a range of biotechnology and biomedical applications.[182]
History and anthropology
Because DNA collects mutations over time, which are then inherited, it contains historical information, and, by comparing DNA sequences, geneticists can infer the evolutionary history of organisms, their phylogeny.[183] This field of phylogenetics is a powerful tool in evolutionary biology. If DNA sequences within a species are compared, population geneticists can learn the history of particular populations. This can be used in studies ranging from ecological genetics to anthropology.
Information storage
DNA as a storage device for information has enormous potential since it has much higher storage density compared to electronic devices. However, high costs, slow read and write times (memory latency), and insufficient reliability has prevented its practical use.[184][185]
History
Maclyn McCarty (left) shakes hands with Francis Crick and James Watson, co-originators of the double-helix model based on the X-ray diffraction data and insights of Rosalind Franklin and Raymond Gosling.
Pencil sketch of the DNA double helix by Francis Crick in 1953
DNA was first isolated by the Swiss physician Friedrich Miescher who, in 1869, discovered a microscopic substance in the pus of discarded surgical bandages. As it resided in the nuclei of cells, he called it «nuclein».[186][187] In 1878, Albrecht Kossel isolated the non-protein component of «nuclein», nucleic acid, and later isolated its five primary nucleobases.[188][189]
In 1909, Phoebus Levene identified the base, sugar, and phosphate nucleotide unit of the RNA (then named «yeast nucleic acid»).[190][191][192] In 1929, Levene identified deoxyribose sugar in «thymus nucleic acid» (DNA).[193] Levene suggested that DNA consisted of a string of four nucleotide units linked together through the phosphate groups («tetranucleotide hypothesis»). Levene thought the chain was short and the bases repeated in a fixed order. In 1927, Nikolai Koltsov proposed that inherited traits would be inherited via a «giant hereditary molecule» made up of «two mirror strands that would replicate in a semi-conservative fashion using each strand as a template».[194][195] In 1928, Frederick Griffith in his experiment discovered that traits of the «smooth» form of Pneumococcus could be transferred to the «rough» form of the same bacteria by mixing killed «smooth» bacteria with the live «rough» form.[196][197] This system provided the first clear suggestion that DNA carries genetic information.
In 1933, while studying virgin sea urchin eggs, Jean Brachet suggested that DNA is found in the cell nucleus and that RNA is present exclusively in the cytoplasm. At the time, «yeast nucleic acid» (RNA) was thought to occur only in plants, while «thymus nucleic acid» (DNA) only in animals. The latter was thought to be a tetramer, with the function of buffering cellular pH.[198][199]
In 1937, William Astbury produced the first X-ray diffraction patterns that showed that DNA had a regular structure.[200]
In 1943, Oswald Avery, along with co-workers Colin MacLeod and Maclyn McCarty, identified DNA as the transforming principle, supporting Griffith’s suggestion (Avery–MacLeod–McCarty experiment).[201] Erwin Chargaff developed and published observations now known as Chargaff’s rules, stating that in DNA from any species of any organism, the amount of guanine should be equal to cytosine and the amount of adenine should be equal to thymine.[202][203] Late in 1951, Francis Crick started working with James Watson at the Cavendish Laboratory within the University of Cambridge. DNA’s role in heredity was confirmed in 1952 when Alfred Hershey and Martha Chase in the Hershey–Chase experiment showed that DNA is the genetic material of the enterobacteria phage T2.[204]
In May 1952, Raymond Gosling, a graduate student working under the supervision of Rosalind Franklin, took an X-ray diffraction image, labeled as «Photo 51»,[205] at high hydration levels of DNA. This photo was given to Watson and Crick by Maurice Wilkins and was critical to their obtaining the correct structure of DNA. Franklin told Crick and Watson that the backbones had to be on the outside. Before then, Linus Pauling, and Watson and Crick, had erroneous models with the chains inside and the bases pointing outwards. Franklin’s identification of the space group for DNA crystals revealed to Crick that the two DNA strands were antiparallel.[206] In February 1953, Linus Pauling and Robert Corey proposed a model for nucleic acids containing three intertwined chains, with the phosphates near the axis, and the bases on the outside.[207] Watson and Crick completed their model, which is now accepted as the first correct model of the double helix of DNA. On 28 February 1953 Crick interrupted patrons’ lunchtime at The Eagle pub in Cambridge to announce that he and Watson had «discovered the secret of life».[208]
The 25 April 1953 issue of the journal Nature published a series of five articles giving the Watson and Crick double-helix structure DNA and evidence supporting it.[209] The structure was reported in a letter titled «MOLECULAR STRUCTURE OF NUCLEIC ACIDS A Structure for Deoxyribose Nucleic Acid«, in which they said, «It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.»[9] This letter was followed by a letter from Franklin and Gosling, which was the first publication of their own X-ray diffraction data and of their original analysis method.[47][210] Then followed a letter by Wilkins and two of his colleagues, which contained an analysis of in vivo B-DNA X-ray patterns, and which supported the presence in vivo of the Watson and Crick structure.[48]
In 1962, after Franklin’s death, Watson, Crick, and Wilkins jointly received the Nobel Prize in Physiology or Medicine.[211] Nobel Prizes are awarded only to living recipients. A debate continues about who should receive credit for the discovery.[212]
In an influential presentation in 1957, Crick laid out the central dogma of molecular biology, which foretold the relationship between DNA, RNA, and proteins, and articulated the «adaptor hypothesis».[213] Final confirmation of the replication mechanism that was implied by the double-helical structure followed in 1958 through the Meselson–Stahl experiment.[214] Further work by Crick and co-workers showed that the genetic code was based on non-overlapping triplets of bases, called codons, allowing Har Gobind Khorana, Robert W. Holley, and Marshall Warren Nirenberg to decipher the genetic code.[215] These findings represent the birth of molecular biology.[216]
See also
- Autosome – Any chromosome other than a sex chromosome
- Crystallography – Scientific study of crystal structures
- DNA Day – Holiday celebrated on April 25
- DNA microarray – Collection of microscopic DNA spots attached to a solid surface
- DNA sequencing – Process of determining the nucleic acid sequence
- Genetic disorder – Health problem caused by one or more abnormalities in the genome
- Genetic genealogy – DNA testing to infer relationships
- Haplotype – Group of genes from one parent
- Meiosis – Type of cell division in sexually-reproducing organisms used to produce gametes
- Nucleic acid notation – Universal notation using the Roman characters A, C, G, and T to call the four DNA nucleotides
- Nucleic acid sequence – Succession of nucleotides in a nucleic acid
- Ribosomal DNA
- Southern blot – DNA analysis technique
- X-ray scattering techniques
- Xeno nucleic acid
References
- ^ «deoxyribonucleic acid». Merriam-Webster Dictionary.
- ^ Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2014). Molecular Biology of the Cell (6th ed.). Garland. p. Chapter 4: DNA, Chromosomes and Genomes. ISBN 978-0-8153-4432-2. Archived from the original on 14 July 2014.
- ^ Purcell A. «DNA». Basic Biology. Archived from the original on 5 January 2017.
- ^ «Uracil». Genome.gov. Retrieved 21 November 2019.
- ^ Russell P (2001). iGenetics. New York: Benjamin Cummings. ISBN 0-8053-4553-1.
- ^ Saenger W (1984). Principles of Nucleic Acid Structure. New York: Springer-Verlag. ISBN 0-387-90762-9.
- ^ a b Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Peter W (2002). Molecular Biology of the Cell (Fourth ed.). New York and London: Garland Science. ISBN 0-8153-3218-1. OCLC 145080076. Archived from the original on 1 November 2016.
- ^ Irobalieva RN, Fogg JM, Catanese DJ, Catanese DJ, Sutthibutpong T, Chen M, Barker AK, Ludtke SJ, Harris SA, Schmid MF, Chiu W, Zechiedrich L (October 2015). «Structural diversity of supercoiled DNA». Nature Communications. 6: 8440. Bibcode:2015NatCo…6.8440I. doi:10.1038/ncomms9440. ISSN 2041-1723. PMC 4608029. PMID 26455586.
- ^ a b c d Watson JD, Crick FH (April 1953). «Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid» (PDF). Nature. 171 (4356): 737–38. Bibcode:1953Natur.171..737W. doi:10.1038/171737a0. ISSN 0028-0836. PMID 13054692. S2CID 4253007. Archived (PDF) from the original on 4 February 2007.
- ^ Mandelkern M, Elias JG, Eden D, Crothers DM (October 1981). «The dimensions of DNA in solution». Journal of Molecular Biology. 152 (1): 153–61. doi:10.1016/0022-2836(81)90099-1. ISSN 0022-2836. PMID 7338906.
- ^ a b c d Berg J, Tymoczko J, Stryer L (2002). Biochemistry. W.H. Freeman and Company. ISBN 0-7167-4955-6.
- ^ IUPAC-IUB Commission on Biochemical Nomenclature (CBN) (December 1970). «Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents. Recommendations 1970». The Biochemical Journal. 120 (3): 449–54. doi:10.1042/bj1200449. ISSN 0306-3283. PMC 1179624. PMID 5499957. Archived from the original on 5 February 2007.
- ^ a b Ghosh A, Bansal M (April 2003). «A glossary of DNA structures from A to Z». Acta Crystallographica Section D. 59 (Pt 4): 620–26. doi:10.1107/S0907444903003251. ISSN 0907-4449. PMID 12657780.
- ^ Created from PDB 1D65
- ^ Yakovchuk P, Protozanova E, Frank-Kamenetskii MD (2006). «Base-stacking and base-pairing contributions into thermal stability of the DNA double helix». Nucleic Acids Research. 34 (2): 564–74. doi:10.1093/nar/gkj454. ISSN 0305-1048. PMC 1360284. PMID 16449200.
- ^ Tropp BE (2012). Molecular Biology (4th ed.). Sudbury, Mass.: Jones and Barlett Learning. ISBN 978-0-7637-8663-2.
- ^ Carr S (1953). «Watson-Crick Structure of DNA». Memorial University of Newfoundland. Archived from the original on 19 July 2016. Retrieved 13 July 2016.
- ^ Verma S, Eckstein F (1998). «Modified oligonucleotides: synthesis and strategy for users». Annual Review of Biochemistry. 67: 99–134. doi:10.1146/annurev.biochem.67.1.99. ISSN 0066-4154. PMID 9759484.
- ^ Johnson TB, Coghill RD (1925). «Pyrimidines. CIII. The discovery of 5-methylcytosine in tuberculinic acid, the nucleic acid of the tubercle bacillus». Journal of the American Chemical Society. 47: 2838–44. doi:10.1021/ja01688a030. ISSN 0002-7863.
- ^ Weigele P, Raleigh EA (October 2016). «Biosynthesis and Function of Modified Bases in Bacteria and Their Viruses». Chemical Reviews. 116 (20): 12655–12687. doi:10.1021/acs.chemrev.6b00114. ISSN 0009-2665. PMID 27319741.
- ^ Kumar S, Chinnusamy V, Mohapatra T (2018). «Epigenetics of Modified DNA Bases: 5-Methylcytosine and Beyond». Frontiers in Genetics. 9: 640. doi:10.3389/fgene.2018.00640. ISSN 1664-8021. PMC 6305559. PMID 30619465.
- ^ Carell T, Kurz MQ, Müller M, Rossa M, Spada F (April 2018). «Non-canonical Bases in the Genome: The Regulatory Information Layer in DNA». Angewandte Chemie. 57 (16): 4296–4312. doi:10.1002/anie.201708228. PMID 28941008.
- ^ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson RE (October 1980). «Crystal structure analysis of a complete turn of B-DNA». Nature. 287 (5784): 755–58. Bibcode:1980Natur.287..755W. doi:10.1038/287755a0. PMID 7432492. S2CID 4315465.
- ^ a b Pabo CO, Sauer RT (1984). «Protein-DNA recognition». Annual Review of Biochemistry. 53: 293–321. doi:10.1146/annurev.bi.53.070184.001453. PMID 6236744.
- ^ Nikolova EN, Zhou H, Gottardo FL, Alvey HS, Kimsey IJ, Al-Hashimi HM (2013). «A historical account of Hoogsteen base-pairs in duplex DNA». Biopolymers. 99 (12): 955–68. doi:10.1002/bip.22334. PMC 3844552. PMID 23818176.
- ^ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub HE (April 2000). «Mechanical stability of single DNA molecules». Biophysical Journal. 78 (4): 1997–2007. Bibcode:2000BpJ….78.1997C. doi:10.1016/S0006-3495(00)76747-6. PMC 1300792. PMID 10733978.
- ^ Chalikian TV, Völker J, Plum GE, Breslauer KJ (July 1999). «A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques». Proceedings of the National Academy of Sciences of the United States of America. 96 (14): 7853–58. Bibcode:1999PNAS…96.7853C. doi:10.1073/pnas.96.14.7853. PMC 22151. PMID 10393911.
- ^ deHaseth PL, Helmann JD (June 1995). «Open complex formation by Escherichia coli RNA polymerase: the mechanism of polymerase-induced strand separation of double helical DNA». Molecular Microbiology. 16 (5): 817–24. doi:10.1111/j.1365-2958.1995.tb02309.x. PMID 7476180. S2CID 24479358.
- ^ Isaksson J, Acharya S, Barman J, Cheruku P, Chattopadhyaya J (December 2004). «Single-stranded adenine-rich DNA and RNA retain structural characteristics of their respective double-stranded conformations and show directional differences in stacking pattern» (PDF). Biochemistry. 43 (51): 15996–6010. doi:10.1021/bi048221v. PMID 15609994. Archived (PDF) from the original on 10 June 2007.
- ^ a b Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L (2019). «On the length, weight and GC content of the human genome». BMC Res Notes. 12 (1): 106. doi:10.1186/s13104-019-4137-z. PMC 6391780. PMID 30813969.
- ^ Gregory SG, Barlow KF, McLay KE, Kaul R, Swarbreck D, Dunham A, et al. (May 2006). «The DNA sequence and biological annotation of human chromosome 1». Nature. 441 (7091): 315–21. Bibcode:2006Natur.441..315G. doi:10.1038/nature04727. PMID 16710414.
- ^ Anderson, S.; Bankier, A. T.; Barrell, B. G.; de Bruijn, M. H. L.; Coulson, A. R.; Drouin, J.; Eperon, I. C.; Nierlich, D. P.; Roe, B. A.; Sanger, F.; Schreier, P. H.; Smith, A. J. H.; Staden, R.; Young, I. G. (April 1981). «Sequence and organization of the human mitochondrial genome». Nature. 290 (5806): 457–465. Bibcode:1981Natur.290..457A. doi:10.1038/290457a0. PMID 7219534. S2CID 4355527.
- ^ «Untitled». Archived from the original on 13 August 2011. Retrieved 13 June 2012.
- ^ a b c Satoh, M; Kuroiwa, T (September 1991). «Organization of multiple nucleoids and DNA molecules in mitochondria of a human cell». Experimental Cell Research. 196 (1): 137–140. doi:10.1016/0014-4827(91)90467-9. PMID 1715276.
- ^ Zhang D, Keilty D, Zhang ZF, Chian RC (2017). «Mitochondria in oocyte aging: current understanding». Facts Views Vis Obgyn. 9 (1): 29–38. PMC 5506767. PMID 28721182.
- ^ Designation of the two strands of DNA Archived 24 April 2008 at the Wayback Machine JCBN/NC-IUB Newsletter 1989. Retrieved 7 May 2008
- ^ Hüttenhofer A, Schattner P, Polacek N (May 2005). «Non-coding RNAs: hope or hype?». Trends in Genetics. 21 (5): 289–97. doi:10.1016/j.tig.2005.03.007. PMID 15851066.
- ^ Munroe SH (November 2004). «Diversity of antisense regulation in eukaryotes: multiple mechanisms, emerging patterns». Journal of Cellular Biochemistry. 93 (4): 664–71. doi:10.1002/jcb.20252. PMID 15389973. S2CID 23748148.
- ^ Makalowska I, Lin CF, Makalowski W (February 2005). «Overlapping genes in vertebrate genomes». Computational Biology and Chemistry. 29 (1): 1–12. doi:10.1016/j.compbiolchem.2004.12.006. PMID 15680581.
- ^ Johnson ZI, Chisholm SW (November 2004). «Properties of overlapping genes are conserved across microbial genomes». Genome Research. 14 (11): 2268–72. doi:10.1101/gr.2433104. PMC 525685. PMID 15520290.
- ^ Lamb RA, Horvath CM (August 1991). «Diversity of coding strategies in influenza viruses». Trends in Genetics. 7 (8): 261–66. doi:10.1016/0168-9525(91)90326-L. PMC 7173306. PMID 1771674.
- ^ Benham CJ, Mielke SP (2005). «DNA mechanics» (PDF). Annual Review of Biomedical Engineering. 7: 21–53. doi:10.1146/annurev.bioeng.6.062403.132016. PMID 16004565. S2CID 1427671. Archived from the original (PDF) on 1 March 2019.
- ^ a b Champoux JJ (2001). «DNA topoisomerases: structure, function, and mechanism» (PDF). Annual Review of Biochemistry. 70: 369–413. doi:10.1146/annurev.biochem.70.1.369. PMID 11395412. S2CID 18144189.
- ^ a b Wang JC (June 2002). «Cellular roles of DNA topoisomerases: a molecular perspective». Nature Reviews Molecular Cell Biology. 3 (6): 430–40. doi:10.1038/nrm831. PMID 12042765. S2CID 205496065.
- ^ Basu HS, Feuerstein BG, Zarling DA, Shafer RH, Marton LJ (October 1988). «Recognition of Z-RNA and Z-DNA determinants by polyamines in solution: experimental and theoretical studies». Journal of Biomolecular Structure & Dynamics. 6 (2): 299–309. doi:10.1080/07391102.1988.10507714. PMID 2482766.
- ^
- Franklin RE, Gosling RG (6 March 1953). «The Structure of Sodium Thymonucleate Fibres I. The Influence of Water Content» (PDF). Acta Crystallogr. 6 (8–9): 673–77. doi:10.1107/S0365110X53001939. Archived (PDF) from the original on 9 January 2016.
- Franklin RE, Gosling RG (1953). «The structure of sodium thymonucleate fibres. II. The cylindrically symmetrical Patterson function» (PDF). Acta Crystallogr. 6 (8–9): 678–85. doi:10.1107/S0365110X53001940. Archived (PDF) from the original on 29 June 2017.
- ^ a b Franklin RE, Gosling RG (April 1953). «Molecular configuration in sodium thymonucleate» (PDF). Nature. 171 (4356): 740–41. Bibcode:1953Natur.171..740F. doi:10.1038/171740a0. PMID 13054694. S2CID 4268222. Archived (PDF) from the original on 3 January 2011.
- ^ a b Wilkins MH, Stokes AR, Wilson HR (April 1953). «Molecular structure of deoxypentose nucleic acids» (PDF). Nature. 171 (4356): 738–40. Bibcode:1953Natur.171..738W. doi:10.1038/171738a0. PMID 13054693. S2CID 4280080. Archived (PDF) from the original on 13 May 2011.
- ^ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL (October 1980). «Polymorphism of DNA double helices». Journal of Molecular Biology. 143 (1): 49–72. doi:10.1016/0022-2836(80)90124-2. PMID 7441761.
- ^ Baianu IC (1980). «Structural Order and Partial Disorder in Biological systems». Bull. Math. Biol. 42 (4): 137–41. doi:10.1007/BF02462372. S2CID 189888972.
- ^ Hosemann R, Bagchi RN (1962). Direct analysis of diffraction by matter. Amsterdam – New York: North-Holland Publishers.
- ^ Baianu IC (1978). «X-ray scattering by partially disordered membrane systems» (PDF). Acta Crystallogr A. 34 (5): 751–53. Bibcode:1978AcCrA..34..751B. doi:10.1107/S0567739478001540. Archived from the original (PDF) on 14 March 2020. Retrieved 29 August 2019.
- ^ Wahl MC, Sundaralingam M (1997). «Crystal structures of A-DNA duplexes». Biopolymers. 44 (1): 45–63. doi:10.1002/(SICI)1097-0282(1997)44:1<45::AID-BIP4>3.0.CO;2-#. PMID 9097733.
- ^ Lu XJ, Shakked Z, Olson WK (July 2000). «A-form conformational motifs in ligand-bound DNA structures». Journal of Molecular Biology. 300 (4): 819–40. doi:10.1006/jmbi.2000.3690. PMID 10891271.
- ^ Rothenburg S, Koch-Nolte F, Haag F (December 2001). «DNA methylation and Z-DNA formation as mediators of quantitative differences in the expression of alleles». Immunological Reviews. 184: 286–98. doi:10.1034/j.1600-065x.2001.1840125.x. PMID 12086319. S2CID 20589136.
- ^ Oh DB, Kim YG, Rich A (December 2002). «Z-DNA-binding proteins can act as potent effectors of gene expression in vivo». Proceedings of the National Academy of Sciences of the United States of America. 99 (26): 16666–71. Bibcode:2002PNAS…9916666O. doi:10.1073/pnas.262672699. PMC 139201. PMID 12486233.
- ^ Palmer J (2 December 2010). «Arsenic-loving bacteria may help in hunt for alien life». BBC News. Archived from the original on 3 December 2010. Retrieved 2 December 2010.
- ^ a b Bortman H (2 December 2010). «Arsenic-Eating Bacteria Opens New Possibilities for Alien Life». Space.com. Archived from the original on 4 December 2010. Retrieved 2 December 2010.
- ^ Katsnelson A (2 December 2010). «Arsenic-eating microbe may redefine chemistry of life». Nature News. doi:10.1038/news.2010.645. Archived from the original on 12 February 2012.
- ^ Cressey D (3 October 2012). «‘Arsenic-life’ Bacterium Prefers Phosphorus after all». Nature News. doi:10.1038/nature.2012.11520. S2CID 87341731.
- ^ Created from Archived 17 October 2016 at the Wayback Machine
- ^ a b Greider CW, Blackburn EH (December 1985). «Identification of a specific telomere terminal transferase activity in Tetrahymena extracts». Cell. 43 (2 Pt 1): 405–13. doi:10.1016/0092-8674(85)90170-9. PMID 3907856.
- ^ a b c Nugent CI, Lundblad V (April 1998). «The telomerase reverse transcriptase: components and regulation». Genes & Development. 12 (8): 1073–85. doi:10.1101/gad.12.8.1073. PMID 9553037.
- ^ Wright WE, Tesmer VM, Huffman KE, Levene SD, Shay JW (November 1997). «Normal human chromosomes have long G-rich telomeric overhangs at one end». Genes & Development. 11 (21): 2801–09. doi:10.1101/gad.11.21.2801. PMC 316649. PMID 9353250.
- ^ a b Burge S, Parkinson GN, Hazel P, Todd AK, Neidle S (2006). «Quadruplex DNA: sequence, topology and structure». Nucleic Acids Research. 34 (19): 5402–15. doi:10.1093/nar/gkl655. PMC 1636468. PMID 17012276.
- ^ Parkinson GN, Lee MP, Neidle S (June 2002). «Crystal structure of parallel quadruplexes from human telomeric DNA». Nature. 417 (6891): 876–80. Bibcode:2002Natur.417..876P. doi:10.1038/nature755. PMID 12050675. S2CID 4422211.
- ^ Griffith JD, Comeau L, Rosenfield S, Stansel RM, Bianchi A, Moss H, de Lange T (May 1999). «Mammalian telomeres end in a large duplex loop». Cell. 97 (4): 503–14. CiteSeerX 10.1.1.335.2649. doi:10.1016/S0092-8674(00)80760-6. PMID 10338214. S2CID 721901.
- ^ Seeman NC (November 2005). «DNA enables nanoscale control of the structure of matter». Quarterly Reviews of Biophysics. 38 (4): 363–71. doi:10.1017/S0033583505004087. PMC 3478329. PMID 16515737.
- ^ Warren M (21 February 2019). «Four new DNA letters double life’s alphabet». Nature. 566 (7745): 436. Bibcode:2019Natur.566..436W. doi:10.1038/d41586-019-00650-8. PMID 30809059.
- ^ Hoshika S, Leal NA, Kim MJ, Kim MS, Karalkar NB, Kim HJ, et al. (22 February 2019). «Hachimoji DNA and RNA: A genetic system with eight building blocks (paywall)». Science. 363 (6429): 884–887. Bibcode:2019Sci…363..884H. doi:10.1126/science.aat0971. PMC 6413494. PMID 30792304.
- ^ Burghardt B, Hartmann AK (February 2007). «RNA secondary structure design». Physical Review E. 75 (2): 021920. arXiv:physics/0609135. Bibcode:2007PhRvE..75b1920B. doi:10.1103/PhysRevE.75.021920. PMID 17358380. S2CID 17574854.
- ^ Reusch, William. «Nucleic Acids». Michigan State University. Retrieved 30 June 2022.
- ^ «How To Extract DNA From Anything Living». University of Utah. Retrieved 30 June 2022.
- ^ Hu Q, Rosenfeld MG (2012). «Epigenetic regulation of human embryonic stem cells». Frontiers in Genetics. 3: 238. doi:10.3389/fgene.2012.00238. PMC 3488762. PMID 23133442.
- ^ Klose RJ, Bird AP (February 2006). «Genomic DNA methylation: the mark and its mediators». Trends in Biochemical Sciences. 31 (2): 89–97. doi:10.1016/j.tibs.2005.12.008. PMID 16403636.
- ^ Bird A (January 2002). «DNA methylation patterns and epigenetic memory». Genes & Development. 16 (1): 6–21. doi:10.1101/gad.947102. PMID 11782440.
- ^ Walsh CP, Xu GL (2006). «Cytosine methylation and DNA repair». Current Topics in Microbiology and Immunology. 301: 283–315. doi:10.1007/3-540-31390-7_11. ISBN 3-540-29114-8. PMID 16570853.
- ^ Kriaucionis S, Heintz N (May 2009). «The nuclear DNA base 5-hydroxymethylcytosine is present in Purkinje neurons and the brain». Science. 324 (5929): 929–30. Bibcode:2009Sci…324..929K. doi:10.1126/science.1169786. PMC 3263819. PMID 19372393.
- ^ Ratel D, Ravanat JL, Berger F, Wion D (March 2006). «N6-methyladenine: the other methylated base of DNA». BioEssays. 28 (3): 309–15. doi:10.1002/bies.20342. PMC 2754416. PMID 16479578.
- ^ Gommers-Ampt JH, Van Leeuwen F, de Beer AL, Vliegenthart JF, Dizdaroglu M, Kowalak JA, Crain PF, Borst P (December 1993). «beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei». Cell. 75 (6): 1129–36. doi:10.1016/0092-8674(93)90322-H. hdl:1874/5219. PMID 8261512. S2CID 24801094.
- ^ Created from PDB 1JDG Archived 22 September 2008 at the Wayback Machine
- ^ Douki T, Reynaud-Angelin A, Cadet J, Sage E (August 2003). «Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation». Biochemistry. 42 (30): 9221–26. doi:10.1021/bi034593c. PMID 12885257.
- ^ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget JP, Ravanat JL, Sauvaigo S (March 1999). «Hydroxyl radicals and DNA base damage». Mutation Research. 424 (1–2): 9–21. doi:10.1016/S0027-5107(99)00004-4. PMID 10064846.
- ^ Beckman KB, Ames BN (August 1997). «Oxidative decay of DNA». The Journal of Biological Chemistry. 272 (32): 19633–36. doi:10.1074/jbc.272.32.19633. PMID 9289489.
- ^ Valerie K, Povirk LF (September 2003). «Regulation and mechanisms of mammalian double-strand break repair». Oncogene. 22 (37): 5792–812. doi:10.1038/sj.onc.1206679. PMID 12947387.
- ^ Johnson G (28 December 2010). «Unearthing Prehistoric Tumors, and Debate». The New York Times. Archived from the original on 24 June 2017.
If we lived long enough, sooner or later we all would get cancer.
- ^ Alberts B, Johnson A, Lewis J, et al. (2002). «The Preventable Causes of Cancer». Molecular biology of the cell (4th ed.). New York: Garland Science. ISBN 0-8153-4072-9. Archived from the original on 2 January 2016.
A certain irreducible background incidence of cancer is to be expected regardless of circumstances: mutations can never be absolutely avoided, because they are an inescapable consequence of fundamental limitations on the accuracy of DNA replication, as discussed in Chapter 5. If a human could live long enough, it is inevitable that at least one of his or her cells would eventually accumulate a set of mutations sufficient for cancer to develop.
- ^ Bernstein H, Payne CM, Bernstein C, Garewal H, Dvorak K (2008). «Cancer and aging as consequences of un-repaired DNA damage». In Kimura H, Suzuki A (eds.). New Research on DNA Damage. New York: Nova Science Publishers. pp. 1–47. ISBN 978-1-60456-581-2. Archived from the original on 25 October 2014.
- ^ Hoeijmakers JH (October 2009). «DNA damage, aging, and cancer». The New England Journal of Medicine. 361 (15): 1475–85. doi:10.1056/NEJMra0804615. PMID 19812404.
- ^ Freitas AA, de Magalhães JP (2011). «A review and appraisal of the DNA damage theory of ageing». Mutation Research. 728 (1–2): 12–22. doi:10.1016/j.mrrev.2011.05.001. PMID 21600302.
- ^ Ferguson LR, Denny WA (September 1991). «The genetic toxicology of acridines». Mutation Research. 258 (2): 123–60. doi:10.1016/0165-1110(91)90006-H. PMID 1881402.
- ^ Stephens TD, Bunde CJ, Fillmore BJ (June 2000). «Mechanism of action in thalidomide teratogenesis». Biochemical Pharmacology. 59 (12): 1489–99. doi:10.1016/S0006-2952(99)00388-3. PMID 10799645.
- ^ Jeffrey AM (1985). «DNA modification by chemical carcinogens». Pharmacology & Therapeutics. 28 (2): 237–72. doi:10.1016/0163-7258(85)90013-0. PMID 3936066.
- ^ Braña MF, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (November 2001). «Intercalators as anticancer drugs». Current Pharmaceutical Design. 7 (17): 1745–80. doi:10.2174/1381612013397113. PMID 11562309.
- ^ Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. (February 2001). «The sequence of the human genome». Science. 291 (5507): 1304–51. Bibcode:2001Sci…291.1304V. doi:10.1126/science.1058040. PMID 11181995.
- ^ Thanbichler M, Wang SC, Shapiro L (October 2005). «The bacterial nucleoid: a highly organized and dynamic structure». Journal of Cellular Biochemistry. 96 (3): 506–21. doi:10.1002/jcb.20519. PMID 15988757.
- ^ Wolfsberg TG, McEntyre J, Schuler GD (February 2001). «Guide to the draft human genome». Nature. 409 (6822): 824–26. Bibcode:2001Natur.409..824W. doi:10.1038/35057000. PMID 11236998.
- ^ Gregory TR (January 2005). «The C-value enigma in plants and animals: a review of parallels and an appeal for partnership». Annals of Botany. 95 (1): 133–46. doi:10.1093/aob/mci009. PMC 4246714. PMID 15596463.
- ^ Birney E, Stamatoyannopoulos JA, Dutta A, Guigó R, Gingeras TR, Margulies EH, et al. (June 2007). «Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project». Nature. 447 (7146): 799–816. Bibcode:2007Natur.447..799B. doi:10.1038/nature05874. PMC 2212820. PMID 17571346.
- ^ Created from PDB 1MSW Archived 6 January 2008 at the Wayback Machine
- ^ Pidoux AL, Allshire RC (March 2005). «The role of heterochromatin in centromere function». Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 360 (1455): 569–79. doi:10.1098/rstb.2004.1611. PMC 1569473. PMID 15905142.
- ^ Harrison PM, Hegyi H, Balasubramanian S, Luscombe NM, Bertone P, Echols N, Johnson T, Gerstein M (February 2002). «Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22». Genome Research. 12 (2): 272–80. doi:10.1101/gr.207102. PMC 155275. PMID 11827946.
- ^ Harrison PM, Gerstein M (May 2002). «Studying genomes through the aeons: protein families, pseudogenes and proteome evolution». Journal of Molecular Biology. 318 (5): 1155–74. doi:10.1016/S0022-2836(02)00109-2. PMID 12083509.
- ^ Albà M (2001). «Replicative DNA polymerases». Genome Biology. 2 (1): REVIEWS3002. doi:10.1186/gb-2001-2-1-reviews3002. PMC 150442. PMID 11178285.
- ^ Tani K, Nasu M (2010). «Roles of Extracellular DNA in Bacterial Ecosystems». In Kikuchi Y, Rykova EY (eds.). Extracellular Nucleic Acids. Springer. pp. 25–38. ISBN 978-3-642-12616-1.
- ^ Vlassov VV, Laktionov PP, Rykova EY (July 2007). «Extracellular nucleic acids». BioEssays. 29 (7): 654–67. doi:10.1002/bies.20604. PMID 17563084. S2CID 32463239.
- ^ Finkel SE, Kolter R (November 2001). «DNA as a nutrient: novel role for bacterial competence gene homologs». Journal of Bacteriology. 183 (21): 6288–93. doi:10.1128/JB.183.21.6288-6293.2001. PMC 100116. PMID 11591672.
- ^ Mulcahy H, Charron-Mazenod L, Lewenza S (November 2008). «Extracellular DNA chelates cations and induces antibiotic resistance in Pseudomonas aeruginosa biofilms». PLOS Pathogens. 4 (11): e1000213. doi:10.1371/journal.ppat.1000213. PMC 2581603. PMID 19023416.
- ^ Berne C, Kysela DT, Brun YV (August 2010). «A bacterial extracellular DNA inhibits settling of motile progeny cells within a biofilm». Molecular Microbiology. 77 (4): 815–29. doi:10.1111/j.1365-2958.2010.07267.x. PMC 2962764. PMID 20598083.
- ^ Whitchurch CB, Tolker-Nielsen T, Ragas PC, Mattick JS (February 2002). «Extracellular DNA required for bacterial biofilm formation». Science. 295 (5559): 1487. doi:10.1126/science.295.5559.1487. PMID 11859186.
- ^ Hu W, Li L, Sharma S, Wang J, McHardy I, Lux R, Yang Z, He X, Gimzewski JK, Li Y, Shi W (2012). «DNA builds and strengthens the extracellular matrix in Myxococcus xanthus biofilms by interacting with exopolysaccharides». PLOS ONE. 7 (12): e51905. Bibcode:2012PLoSO…751905H. doi:10.1371/journal.pone.0051905. PMC 3530553. PMID 23300576.
- ^ Hui L, Bianchi DW (February 2013). «Recent advances in the prenatal interrogation of the human fetal genome». Trends in Genetics. 29 (2): 84–91. doi:10.1016/j.tig.2012.10.013. PMC 4378900. PMID 23158400.
- ^ Foote AD, Thomsen PF, Sveegaard S, Wahlberg M, Kielgast J, Kyhn LA, et al. (2012). «Investigating the potential use of environmental DNA (eDNA) for genetic monitoring of marine mammals». PLOS ONE. 7 (8): e41781. Bibcode:2012PLoSO…741781F. doi:10.1371/journal.pone.0041781. PMC 3430683. PMID 22952587.
- ^ «Researchers Detect Land Animals Using DNA in Nearby Water Bodies».
- ^ Sandman K, Pereira SL, Reeve JN (December 1998). «Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome». Cellular and Molecular Life Sciences. 54 (12): 1350–64. doi:10.1007/s000180050259. PMID 9893710. S2CID 21101836.
- ^ Dame RT (May 2005). «The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin». Molecular Microbiology. 56 (4): 858–70. doi:10.1111/j.1365-2958.2005.04598.x. PMID 15853876. S2CID 26965112.
- ^ Luger K, Mäder AW, Richmond RK, Sargent DF, Richmond TJ (September 1997). «Crystal structure of the nucleosome core particle at 2.8 A resolution». Nature. 389 (6648): 251–60. Bibcode:1997Natur.389..251L. doi:10.1038/38444. PMID 9305837. S2CID 4328827.
- ^ Jenuwein T, Allis CD (August 2001). «Translating the histone code» (PDF). Science. 293 (5532): 1074–80. doi:10.1126/science.1063127. PMID 11498575. S2CID 1883924. Archived (PDF) from the original on 8 August 2017.
- ^ Ito T (2003). «Nucleosome assembly and remodeling». Current Topics in Microbiology and Immunology. 274: 1–22. doi:10.1007/978-3-642-55747-7_1. ISBN 978-3-540-44208-0. PMID 12596902.
- ^ Thomas JO (August 2001). «HMG1 and 2: architectural DNA-binding proteins». Biochemical Society Transactions. 29 (Pt 4): 395–401. doi:10.1042/BST0290395. PMID 11497996.
- ^ Grosschedl R, Giese K, Pagel J (March 1994). «HMG domain proteins: architectural elements in the assembly of nucleoprotein structures». Trends in Genetics. 10 (3): 94–100. doi:10.1016/0168-9525(94)90232-1. PMID 8178371.
- ^ Iftode C, Daniely Y, Borowiec JA (1999). «Replication protein A (RPA): the eukaryotic SSB». Critical Reviews in Biochemistry and Molecular Biology. 34 (3): 141–80. doi:10.1080/10409239991209255. PMID 10473346.
- ^ Created from PDB 1LMB Archived 6 January 2008 at the Wayback Machine
- ^ Myers LC, Kornberg RD (2000). «Mediator of transcriptional regulation». Annual Review of Biochemistry. 69: 729–49. doi:10.1146/annurev.biochem.69.1.729. PMID 10966474.
- ^ Spiegelman BM, Heinrich R (October 2004). «Biological control through regulated transcriptional coactivators». Cell. 119 (2): 157–67. doi:10.1016/j.cell.2004.09.037. PMID 15479634.
- ^ Li Z, Van Calcar S, Qu C, Cavenee WK, Zhang MQ, Ren B (July 2003). «A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells». Proceedings of the National Academy of Sciences of the United States of America. 100 (14): 8164–69. Bibcode:2003PNAS..100.8164L. doi:10.1073/pnas.1332764100. PMC 166200. PMID 12808131.
- ^ Created from PDB 1RVA Archived 6 January 2008 at the Wayback Machine
- ^ Bickle TA, Krüger DH (June 1993). «Biology of DNA restriction». Microbiological Reviews. 57 (2): 434–50. doi:10.1128/MMBR.57.2.434-450.1993. PMC 372918. PMID 8336674.
- ^ a b Doherty AJ, Suh SW (November 2000). «Structural and mechanistic conservation in DNA ligases». Nucleic Acids Research. 28 (21): 4051–58. doi:10.1093/nar/28.21.4051. PMC 113121. PMID 11058099.
- ^ Schoeffler AJ, Berger JM (December 2005). «Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism». Biochemical Society Transactions. 33 (Pt 6): 1465–70. doi:10.1042/BST20051465. PMID 16246147.
- ^ Tuteja N, Tuteja R (May 2004). «Unraveling DNA helicases. Motif, structure, mechanism and function» (PDF). European Journal of Biochemistry. 271 (10): 1849–63. doi:10.1111/j.1432-1033.2004.04094.x. PMID 15128295.
- ^ Joyce CM, Steitz TA (November 1995). «Polymerase structures and function: variations on a theme?». Journal of Bacteriology. 177 (22): 6321–29. doi:10.1128/jb.177.22.6321-6329.1995. PMC 177480. PMID 7592405.
- ^ Hubscher U, Maga G, Spadari S (2002). «Eukaryotic DNA polymerases» (PDF). Annual Review of Biochemistry. 71: 133–63. doi:10.1146/annurev.biochem.71.090501.150041. PMID 12045093. S2CID 26171993. Archived from the original (PDF) on 26 January 2021.
- ^ Johnson A, O’Donnell M (2005). «Cellular DNA replicases: components and dynamics at the replication fork». Annual Review of Biochemistry. 74: 283–315. doi:10.1146/annurev.biochem.73.011303.073859. PMID 15952889.
- ^ a b Tarrago-Litvak L, Andréola ML, Nevinsky GA, Sarih-Cottin L, Litvak S (May 1994). «The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention». FASEB Journal. 8 (8): 497–503. doi:10.1096/fasebj.8.8.7514143. PMID 7514143. S2CID 39614573.
- ^ Martinez E (December 2002). «Multi-protein complexes in eukaryotic gene transcription». Plant Molecular Biology. 50 (6): 925–47. doi:10.1023/A:1021258713850. PMID 12516863. S2CID 24946189.
- ^ Created from PDB 1M6G Archived 10 January 2010 at the Wayback Machine
- ^ Cremer T, Cremer C (April 2001). «Chromosome territories, nuclear architecture and gene regulation in mammalian cells». Nature Reviews Genetics. 2 (4): 292–301. doi:10.1038/35066075. PMID 11283701. S2CID 8547149.
- ^ Pál C, Papp B, Lercher MJ (May 2006). «An integrated view of protein evolution». Nature Reviews Genetics. 7 (5): 337–48. doi:10.1038/nrg1838. PMID 16619049. S2CID 23225873.
- ^ O’Driscoll M, Jeggo PA (January 2006). «The role of double-strand break repair – insights from human genetics». Nature Reviews Genetics. 7 (1): 45–54. doi:10.1038/nrg1746. PMID 16369571. S2CID 7779574.
- ^ Vispé S, Defais M (October 1997). «Mammalian Rad51 protein: a RecA homologue with pleiotropic functions». Biochimie. 79 (9–10): 587–92. doi:10.1016/S0300-9084(97)82007-X. PMID 9466696.
- ^ Neale MJ, Keeney S (July 2006). «Clarifying the mechanics of DNA strand exchange in meiotic recombination». Nature. 442 (7099): 153–58. Bibcode:2006Natur.442..153N. doi:10.1038/nature04885. PMC 5607947. PMID 16838012.
- ^ Dickman MJ, Ingleston SM, Sedelnikova SE, Rafferty JB, Lloyd RG, Grasby JA, Hornby DP (November 2002). «The RuvABC resolvasome». European Journal of Biochemistry. 269 (22): 5492–501. doi:10.1046/j.1432-1033.2002.03250.x. PMID 12423347. S2CID 39505263.
- ^ Joyce GF (July 2002). «The antiquity of RNA-based evolution». Nature. 418 (6894): 214–21. Bibcode:2002Natur.418..214J. doi:10.1038/418214a. PMID 12110897. S2CID 4331004.
- ^ Orgel LE (2004). «Prebiotic chemistry and the origin of the RNA world». Critical Reviews in Biochemistry and Molecular Biology. 39 (2): 99–123. CiteSeerX 10.1.1.537.7679. doi:10.1080/10409230490460765. PMID 15217990.
- ^ Davenport RJ (May 2001). «Ribozymes. Making copies in the RNA world». Science. 292 (5520): 1278a–1278. doi:10.1126/science.292.5520.1278a. PMID 11360970. S2CID 85976762.
- ^ Szathmáry E (April 1992). «What is the optimum size for the genetic alphabet?». Proceedings of the National Academy of Sciences of the United States of America. 89 (7): 2614–18. Bibcode:1992PNAS…89.2614S. doi:10.1073/pnas.89.7.2614. PMC 48712. PMID 1372984.
- ^ Lindahl T (April 1993). «Instability and decay of the primary structure of DNA». Nature. 362 (6422): 709–15. Bibcode:1993Natur.362..709L. doi:10.1038/362709a0. PMID 8469282. S2CID 4283694.
- ^ Vreeland RH, Rosenzweig WD, Powers DW (October 2000). «Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal». Nature. 407 (6806): 897–900. Bibcode:2000Natur.407..897V. doi:10.1038/35038060. PMID 11057666. S2CID 9879073.
- ^ Hebsgaard MB, Phillips MJ, Willerslev E (May 2005). «Geologically ancient DNA: fact or artefact?». Trends in Microbiology. 13 (5): 212–20. doi:10.1016/j.tim.2005.03.010. PMID 15866038.
- ^ Nickle DC, Learn GH, Rain MW, Mullins JI, Mittler JE (January 2002). «Curiously modern DNA for a «250 million-year-old» bacterium». Journal of Molecular Evolution. 54 (1): 134–37. Bibcode:2002JMolE..54..134N. doi:10.1007/s00239-001-0025-x. PMID 11734907. S2CID 24740859.
- ^ Callahan MP, Smith KE, Cleaves HJ, Ruzicka J, Stern JC, Glavin DP, House CH, Dworkin JP (August 2011). «Carbonaceous meteorites contain a wide range of extraterrestrial nucleobases». Proceedings of the National Academy of Sciences of the United States of America. 108 (34): 13995–98. Bibcode:2011PNAS..10813995C. doi:10.1073/pnas.1106493108. PMC 3161613. PMID 21836052.
- ^ Steigerwald J (8 August 2011). «NASA Researchers: DNA Building Blocks Can Be Made in Space». NASA. Archived from the original on 23 June 2015. Retrieved 10 August 2011.
- ^ ScienceDaily Staff (9 August 2011). «DNA Building Blocks Can Be Made in Space, NASA Evidence Suggests». ScienceDaily. Archived from the original on 5 September 2011. Retrieved 9 August 2011.
- ^ Marlaire R (3 March 2015). «NASA Ames Reproduces the Building Blocks of Life in Laboratory». NASA. Archived from the original on 5 March 2015. Retrieved 5 March 2015.
- ^ Hunt, Katie (17 February 2021). «World’s oldest DNA sequenced from a mammoth that lived more than a million years ago». CNN News. Retrieved 17 February 2021.
- ^ Callaway, Ewen (17 February 2021). «Million-year-old mammoth genomes shatter record for oldest ancient DNA – Permafrost-preserved teeth, up to 1.6 million years old, identify a new kind of mammoth in Siberia». Nature. 590 (7847): 537–538. doi:10.1038/d41586-021-00436-x. ISSN 0028-0836. PMID 33597786.
- ^ Goff SP, Berg P (December 1976). «Construction of hybrid viruses containing SV40 and lambda phage DNA segments and their propagation in cultured monkey cells». Cell. 9 (4 PT 2): 695–705. doi:10.1016/0092-8674(76)90133-1. PMID 189942. S2CID 41788896.
- ^ Houdebine LM (2007). «Transgenic animal models in biomedical research». Target Discovery and Validation Reviews and Protocols. Methods in Molecular Biology. Vol. 360. pp. 163–202. doi:10.1385/1-59745-165-7:163. ISBN 978-1-59745-165-9. PMID 17172731.
- ^ Daniell H, Dhingra A (April 2002). «Multigene engineering: dawn of an exciting new era in biotechnology». Current Opinion in Biotechnology. 13 (2): 136–41. doi:10.1016/S0958-1669(02)00297-5. PMC 3481857. PMID 11950565.
- ^ Job D (November 2002). «Plant biotechnology in agriculture». Biochimie. 84 (11): 1105–10. doi:10.1016/S0300-9084(02)00013-5. PMID 12595138.
- ^ Curtis C, Hereward J (29 August 2017). «From the crime scene to the courtroom: the journey of a DNA sample». The Conversation. Archived from the original on 22 October 2017. Retrieved 22 October 2017.
- ^ Collins A, Morton NE (June 1994). «Likelihood ratios for DNA identification». Proceedings of the National Academy of Sciences of the United States of America. 91 (13): 6007–11. Bibcode:1994PNAS…91.6007C. doi:10.1073/pnas.91.13.6007. PMC 44126. PMID 8016106.
- ^ Weir BS, Triggs CM, Starling L, Stowell LI, Walsh KA, Buckleton J (March 1997). «Interpreting DNA mixtures» (PDF). Journal of Forensic Sciences. 42 (2): 213–22. doi:10.1520/JFS14100J. PMID 9068179. S2CID 14511630.
- ^ Jeffreys AJ, Wilson V, Thein SL (1985). «Individual-specific ‘fingerprints’ of human DNA». Nature. 316 (6023): 76–79. Bibcode:1985Natur.316…76J. doi:10.1038/316076a0. PMID 2989708. S2CID 4229883.
- ^ Colin Pitchfork – first murder conviction on DNA evidence also clears the prime suspect Forensic Science Service Accessed 23 December 2006
- ^ «DNA Identification in Mass Fatality Incidents». National Institute of Justice. September 2006. Archived from the original on 12 November 2006.
- ^ «Paternity Blood Tests That Work Early in a Pregnancy» New York Times June 20, 2012 Archived 24 June 2017 at the Wayback Machine
- ^ a b Breaker RR, Joyce GF (December 1994). «A DNA enzyme that cleaves RNA». Chemistry & Biology. 1 (4): 223–29. doi:10.1016/1074-5521(94)90014-0. PMID 9383394.
- ^ Chandra M, Sachdeva A, Silverman SK (October 2009). «DNA-catalyzed sequence-specific hydrolysis of DNA». Nature Chemical Biology. 5 (10): 718–20. doi:10.1038/nchembio.201. PMC 2746877. PMID 19684594.
- ^ Carmi N, Shultz LA, Breaker RR (December 1996). «In vitro selection of self-cleaving DNAs». Chemistry & Biology. 3 (12): 1039–46. doi:10.1016/S1074-5521(96)90170-2. PMID 9000012.
- ^ Torabi SF, Wu P, McGhee CE, Chen L, Hwang K, Zheng N, Cheng J, Lu Y (May 2015). «In vitro selection of a sodium-specific DNAzyme and its application in intracellular sensing». Proceedings of the National Academy of Sciences of the United States of America. 112 (19): 5903–08. Bibcode:2015PNAS..112.5903T. doi:10.1073/pnas.1420361112. PMC 4434688. PMID 25918425.
- ^ Baldi P, Brunak S (2001). Bioinformatics: The Machine Learning Approach. MIT Press. ISBN 978-0-262-02506-5. OCLC 45951728.
- ^ Gusfield D (15 January 1997). Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press. ISBN 978-0-521-58519-4.
- ^ Sjölander K (January 2004). «Phylogenomic inference of protein molecular function: advances and challenges». Bioinformatics. 20 (2): 170–79. CiteSeerX 10.1.1.412.943. doi:10.1093/bioinformatics/bth021. PMID 14734307.
- ^ Mount DM (2004). Bioinformatics: Sequence and Genome Analysis (2nd ed.). Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. ISBN 0-87969-712-1. OCLC 55106399.
- ^ Strong, Michael (2004). «Protein Nanomachines». PLOS Biology. 2 (3): e73. doi:10.1371/journal.pbio.0020073. PMC 368168. PMID 15024422. S2CID 13222080.
- ^ Rothemund PW (March 2006). «Folding DNA to create nanoscale shapes and patterns» (PDF). Nature. 440 (7082): 297–302. Bibcode:2006Natur.440..297R. doi:10.1038/nature04586. PMID 16541064. S2CID 4316391.
- ^ Andersen ES, Dong M, Nielsen MM, Jahn K, Subramani R, Mamdouh W, Golas MM, Sander B, Stark H, Oliveira CL, Pedersen JS, Birkedal V, Besenbacher F, Gothelf KV, Kjems J (May 2009). «Self-assembly of a nanoscale DNA box with a controllable lid». Nature. 459 (7243): 73–76. Bibcode:2009Natur.459…73A. doi:10.1038/nature07971. hdl:11858/00-001M-0000-0010-9362-B. PMID 19424153. S2CID 4430815.
- ^ Ishitsuka Y, Ha T (May 2009). «DNA nanotechnology: a nanomachine goes live». Nature Nanotechnology. 4 (5): 281–82. Bibcode:2009NatNa…4..281I. doi:10.1038/nnano.2009.101. PMID 19421208.
- ^ Aldaye FA, Palmer AL, Sleiman HF (September 2008). «Assembling materials with DNA as the guide». Science. 321 (5897): 1795–99. Bibcode:2008Sci…321.1795A. doi:10.1126/science.1154533. PMID 18818351. S2CID 2755388.
- ^ Dunn, Matthew; Jimenez, Randi; Chaput, John (2017). «Analysis of aptamer discovery and technology». Nature Reviews Chemistry. 1 (10). doi:10.1038/s41570-017-0076. Retrieved 30 June 2022.
- ^ Wray GA (2002). «Dating branches on the tree of life using DNA». Genome Biology. 3 (1): REVIEWS0001. doi:10.1186/gb-2001-3-1-reviews0001. PMC 150454. PMID 11806830.
- ^ Panda D, Molla KA, Baig MJ, Swain A, Behera D, Dash M (May 2018). «DNA as a digital information storage device: hope or hype?». 3 Biotech. 8 (5): 239. doi:10.1007/s13205-018-1246-7. PMC 5935598. PMID 29744271.
- ^ Akram F, Haq IU, Ali H, Laghari AT (October 2018). «Trends to store digital data in DNA: an overview». Molecular Biology Reports. 45 (5): 1479–1490. doi:10.1007/s11033-018-4280-y. PMID 30073589. S2CID 51905843.
- ^ Miescher F (1871). «Ueber die chemische Zusammensetzung der Eiterzellen» [On the chemical composition of pus cells]. Medicinisch-chemische Untersuchungen (in German). 4: 441–60.
[p. 456] Ich habe mich daher später mit meinen Versuchen an die ganzen Kerne gehalten, die Trennung der Körper, die ich einstweilen ohne weiteres Präjudiz als lösliches und unlösliches Nuclein bezeichnen will, einem günstigeren Material überlassend. (Therefore, in my experiments I subsequently limited myself to the whole nucleus, leaving to a more favorable material the separation of the substances, that for the present, without further prejudice, I will designate as soluble and insoluble nuclear material («Nuclein»))
- ^ Dahm R (January 2008). «Discovering DNA: Friedrich Miescher and the early years of nucleic acid research». Human Genetics. 122 (6): 565–81. doi:10.1007/s00439-007-0433-0. PMID 17901982. S2CID 915930.
- ^ See:
- Kossel A (1879). «Ueber Nucleïn der Hefe» [On nuclein in yeast]. Zeitschrift für physiologische Chemie (in German). 3: 284–91.
- Kossel A (1880). «Ueber Nucleïn der Hefe II» [On nuclein in yeast, Part 2]. Zeitschrift für physiologische Chemie (in German). 4: 290–95.
- Kossel A (1881). «Ueber die Verbreitung des Hypoxanthins im Thier- und Pflanzenreich» [On the distribution of hypoxanthins in the animal and plant kingdoms]. Zeitschrift für physiologische Chemie (in German). 5: 267–71.
- Kossel A (1881). Trübne KJ (ed.). Untersuchungen über die Nucleine und ihre Spaltungsprodukte [Investigations into nuclein and its cleavage products] (in German). Strassburg, Germany. p. 19.
- Kossel A (1882). «Ueber Xanthin und Hypoxanthin» [On xanthin and hypoxanthin]. Zeitschrift für physiologische Chemie. 6: 422–31.
- Albrect Kossel (1883) «Zur Chemie des Zellkerns» Archived 17 November 2017 at the Wayback Machine (On the chemistry of the cell nucleus), Zeitschrift für physiologische Chemie, 7 : 7–22.
- Kossel A (1886). «Weitere Beiträge zur Chemie des Zellkerns» [Further contributions to the chemistry of the cell nucleus]. Zeitschrift für Physiologische Chemie (in German). 10: 248–64.
On p. 264, Kossel remarked presciently: Der Erforschung der quantitativen Verhältnisse der vier stickstoffreichen Basen, der Abhängigkeit ihrer Menge von den physiologischen Zuständen der Zelle, verspricht wichtige Aufschlüsse über die elementaren physiologisch-chemischen Vorgänge. (The study of the quantitative relations of the four nitrogenous bases—[and] of the dependence of their quantity on the physiological states of the cell—promises important insights into the fundamental physiological-chemical processes.)
- ^ Jones ME (September 1953). «Albrecht Kossel, a biographical sketch». The Yale Journal of Biology and Medicine. 26 (1): 80–97. PMC 2599350. PMID 13103145.
- ^ Levene PA, Jacobs WA (1909). «Über Inosinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42: 1198–203. doi:10.1002/cber.190904201196.
- ^ Levene PA, Jacobs WA (1909). «Über die Hefe-Nucleinsäure». Berichte der Deutschen Chemischen Gesellschaft (in German). 42 (2): 2474–78. doi:10.1002/cber.190904202148.
- ^ Levene P (1919). «The structure of yeast nucleic acid». J Biol Chem. 40 (2): 415–24. doi:10.1016/S0021-9258(18)87254-4.
- ^ Cohen JS, Portugal FH (1974). «The search for the chemical structure of DNA» (PDF). Connecticut Medicine. 38 (10): 551–52, 554–57. PMID 4609088.
- ^ Koltsov proposed that a cell’s genetic information was encoded in a long chain of amino acids. See:
- Кольцов, Н. К. (12 December 1927). Физико-химические основы морфологии [The physical-chemical basis of morphology] (Speech). 3rd All-Union Meeting of Zoologist, Anatomists, and Histologists (in Russian). Leningrad, U.S.S.R.
- Reprinted in: Кольцов, Н. К. (1928). «Физико-химические основы морфологии» [The physical-chemical basis of morphology]. Успехи экспериментальной биологии (Advances in Experimental Biology) series B (in Russian). 7 (1): ?.
- Reprinted in German as: Koltzoff NK (1928). «Physikalisch-chemische Grundlagen der Morphologie» [The physical-chemical basis of morphology]. Biologisches Zentralblatt (in German). 48 (6): 345–69.
- In 1934, Koltsov contended that the proteins that contain a cell’s genetic information replicate. See: Koltzoff N (October 1934). «The structure of the chromosomes in the salivary glands of Drosophila». Science. 80 (2075): 312–13. Bibcode:1934Sci….80..312K. doi:10.1126/science.80.2075.312. PMID 17769043.
From page 313: «I think that the size of the chromosomes in the salivary glands [of Drosophila] is determined through the multiplication of genonemes. By this term I designate the axial thread of the chromosome, in which the geneticists locate the linear combination of genes; … In the normal chromosome there is usually only one genoneme; before cell-division this genoneme has become divided into two strands.»
- ^ Soyfer VN (September 2001). «The consequences of political dictatorship for Russian science». Nature Reviews Genetics. 2 (9): 723–29. doi:10.1038/35088598. PMID 11533721. S2CID 46277758.
- ^ Griffith F (January 1928). «The Significance of Pneumococcal Types». The Journal of Hygiene. 27 (2): 113–59. doi:10.1017/S0022172400031879. PMC 2167760. PMID 20474956.
- ^ Lorenz MG, Wackernagel W (September 1994). «Bacterial gene transfer by natural genetic transformation in the environment». Microbiological Reviews. 58 (3): 563–602. doi:10.1128/MMBR.58.3.563-602.1994. PMC 372978. PMID 7968924.
- ^ Brachet J (1933). «Recherches sur la synthese de l’acide thymonucleique pendant le developpement de l’oeuf d’Oursin». Archives de Biologie (in Italian). 44: 519–76.
- ^ Burian R (1994). «Jean Brachet’s Cytochemical Embryology: Connections with the Renovation of Biology in France?» (PDF). In Debru C, Gayon J, Picard JF (eds.). Les sciences biologiques et médicales en France 1920–1950. Cahiers pour I’histoire de la recherche. Vol. 2. Paris: CNRS Editions. pp. 207–20.
- ^ See:
- Astbury WT, Bell FO (1938). «Some recent developments in the X-ray study of proteins and related structures» (PDF). Cold Spring Harbor Symposia on Quantitative Biology. 6: 109–21. doi:10.1101/sqb.1938.006.01.013. Archived from the original (PDF) on 14 July 2014.
- Astbury WT (1947). «X-ray studies of nucleic acids». Symposia of the Society for Experimental Biology (1): 66–76. PMID 20257017. Archived from the original on 5 July 2014.
- ^ Avery OT, Macleod CM, McCarty M (February 1944). «Studies on the Chemical Nature of the Substance Inducing Transformation of Pneumococcal Types: Induction of Transformation by a Desoxyribonucleic Acid Fraction Isolated from Pneumococcus Type III». The Journal of Experimental Medicine. 79 (2): 137–58. doi:10.1084/jem.79.2.137. PMC 2135445. PMID 19871359.
- ^ Chargaff, Erwin (June 1950). «Chemical specificity of nucleic acids and mechanism of their enzymatic degradation». Experientia. 6 (6): 201–209. doi:10.1007/BF02173653. PMID 15421335. S2CID 2522535.
- ^ Kresge, Nicole; Simoni, Robert D.; Hill, Robert L. (June 2005). «Chargaff’s Rules: the Work of Erwin Chargaff». Journal of Biological Chemistry. 280 (24): 172–174. doi:10.1016/S0021-9258(20)61522-8.
- ^ Hershey AD, Chase M (May 1952). «Independent functions of viral protein and nucleic acid in growth of bacteriophage». The Journal of General Physiology. 36 (1): 39–56. doi:10.1085/jgp.36.1.39. PMC 2147348. PMID 12981234.
- ^ The B-DNA X-ray pattern on the right of this linked image Archived 10 July 2009 at the Wayback Machine
- ^ Schwartz J (2008). In pursuit of the gene : from Darwin to DNA. Cambridge, Mass.: Harvard University Press. ISBN 978-0-674-02670-4.
- ^ Pauling L, Corey RB (February 1953). «A Proposed Structure For The Nucleic Acids». Proceedings of the National Academy of Sciences of the United States of America. 39 (2): 84–97. Bibcode:1953PNAS…39…84P. doi:10.1073/pnas.39.2.84. PMC 1063734. PMID 16578429.
- ^ Regis E (2009). What Is Life?: investigating the nature of life in the age of synthetic biology. Oxford: Oxford University Press. p. 52. ISBN 978-0-19-538341-6.
- ^ «Double Helix of DNA: 50 Years». Nature Archives. Archived from the original on 5 April 2015.
- ^ «Original X-ray diffraction image». Oregon State Library. Archived from the original on 30 January 2009. Retrieved 6 February 2011.
- ^ «The Nobel Prize in Physiology or Medicine 1962». Nobelprize.org.
- ^ Maddox B (January 2003). «The double helix and the ‘wronged heroine’» (PDF). Nature. 421 (6921): 407–08. Bibcode:2003Natur.421..407M. doi:10.1038/nature01399. PMID 12540909. S2CID 4428347. Archived (PDF) from the original on 17 October 2016.
- ^ Crick F (1955). A Note for the RNA Tie Club (PDF) (Speech). Cambridge, England. Archived from the original (PDF) on 1 October 2008.
- ^ Meselson M, Stahl FW (July 1958). «The Replication of DNA in Escherichia Coli». Proceedings of the National Academy of Sciences of the United States of America. 44 (7): 671–82. Bibcode:1958PNAS…44..671M. doi:10.1073/pnas.44.7.671. PMC 528642. PMID 16590258.
- ^ «The Nobel Prize in Physiology or Medicine 1968». Nobelprize.org.
- ^ Pray L (2008). «Discovery of DNA structure and function: Watson and Crick». Nature Education. 1 (1): 100.
Further reading
- Berry A, Watson J (2003). DNA: the secret of life. New York: Alfred A. Knopf. ISBN 0-375-41546-7.
- Calladine CR, Drew HR, Luisi BF, Travers AA (2003). Understanding DNA: the molecule & how it works. Amsterdam: Elsevier Academic Press. ISBN 0-12-155089-3.
- Carina D, Clayton J (2003). 50 years of DNA. Basingstoke: Palgrave Macmillan. ISBN 1-4039-1479-6.
- Judson HF (1979). The Eighth Day of Creation: Makers of the Revolution in Biology (2nd ed.). Cold Spring Harbor Laboratory Press. ISBN 0-671-22540-5.
- Olby RC (1994). The path to the double helix: the discovery of DNA. New York: Dover Publications. ISBN 0-486-68117-3. First published in October 1974 by MacMillan, with foreword by Francis Crick; the definitive DNA textbook, revised in 1994 with a nine-page postscript.
- Olby R (January 2003). «Quiet debut for the double helix». Nature. 421 (6921): 402–05. Bibcode:2003Natur.421..402O. doi:10.1038/nature01397. PMID 12540907.
- Olby RC (2009). Francis Crick: A Biography. Plainview, N.Y: Cold Spring Harbor Laboratory Press. ISBN 978-0-87969-798-3.
- Micklas D (2003). DNA Science: A First Course. Cold Spring Harbor Press. ISBN 978-0-87969-636-8.
- Ridley M (2006). Francis Crick: discoverer of the genetic code. Ashland, OH: Eminent Lives, Atlas Books. ISBN 0-06-082333-X.
- Rosenfeld I (2010). DNA: A Graphic Guide to the Molecule that Shook the World. Columbia University Press. ISBN 978-0-231-14271-7.
- Schultz M, Cannon Z (2009). The Stuff of Life: A Graphic Guide to Genetics and DNA. Hill and Wang. ISBN 978-0-8090-8947-5.
- Stent GS, Watson J (1980). The Double Helix: A Personal Account of the Discovery of the Structure of DNA. New York: Norton. ISBN 0-393-95075-1.
- Watson J (2004). DNA: The Secret of Life. Random House. ISBN 978-0-09-945184-6.
- Wilkins M (2003). The third man of the double helix the autobiography of Maurice Wilkins. Cambridge, England: University Press. ISBN 0-19-860665-6.
External links
![]()
This audio file was created from a revision of this article dated 12 February 2007, and does not reflect subsequent edits.
- DNA at Curlie
- DNA binding site prediction on protein
- DNA the Double Helix Game From the official Nobel Prize web site
- DNA under electron microscope
- Dolan DNA Learning Center
- Double Helix: 50 years of DNA, Nature
- Proteopedia DNA
- Proteopedia Forms_of_DNA
- ENCODE threads explorer ENCODE home page at Nature
- Double Helix 1953–2003 National Centre for Biotechnology Education
- Genetic Education Modules for Teachers – DNA from the Beginning Study Guide
- PDB Molecule of the Month DNA
- «Clue to chemistry of heredity found». The New York Times, June 1953. First American newspaper coverage of the discovery of the DNA structure
- DNA from the Beginning Another DNA Learning Center site on DNA, genes, and heredity from Mendel to the human genome project.
- The Register of Francis Crick Personal Papers 1938 – 2007 at Mandeville Special Collections Library, University of California, San Diego
- Seven-page, handwritten letter that Crick sent to his 12-year-old son Michael in 1953 describing the structure of DNA. See Crick’s medal goes under the hammer, Nature, 5 April 2013.
ДНК и гены
ДНК ПРОКАРИОТ И ЭУКАРИОТ
|
|

, вошедшая в книгу рекордов Гиннесса")
Справа крупнейшая спираль ДНК человека, выстроенная из людей на пляже в Варне (Болгария), вошедшая в книгу рекордов Гиннесса 23 апреля 2016 года
Дезоксирибонуклеиновая кислота. Общие сведения
 Содержание страницы:
Содержание страницы:
- Дезоксирибонуклеиновая кислота
- Строение нуклеиновых кислот
- Репликация
- Строение РНК
- Транскрипция
- Трансляция
- Генетический код
- Геном: гены и хромосомы
- Прокариоты
- Эукариоты
- Строение генов
- Строение генов прокариот
- Строение генов эукариот
- Сравнение строения генов
- Мутации и мутагенез
- Генные мутации
- Хромосомные мутации
- Геномные мутации
- Видео по теме ДНК
- Дополнительный материал
ДНК (дезоксирибонуклеиновая кислота) – своеобразный чертеж жизни, сложный код, в котором заключены данные о наследственной информации. Эта сложная макромолекула способна хранить и передавать наследственную генетическую информацию из поколения в поколение. ДНК определяет такие свойства любого живого организма как наследственность и изменчивость. Закодированная в ней информация задает всю программу развития любого живого организма. Генетически заложенные факторы предопределяют весь ход жизни как человека, так и любого др. организхма. Искусственное или естественное воздействие внешней среды способны лишь в незначительной степени повлиять на общую выраженность отдельных генетических признаков или сказаться на развитии запрограммированных процессов.
Дезоксирибонуклеи́новая кислота (ДНК) — макромолекула (одна из трёх основных, две другие — РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов. ДНК содержит информацию о структуре различных видов РНК и белков.
В клетках эукариот (животных, растений и грибов) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органоидах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У них и у низших эукариот (например, дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами.
С химической точки зрения ДНК — это длинная полимерная молекула, состоящая из повторяющихся блоков — нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в цепи образуются за счёт дезоксирибозы (С) и фосфатной (Ф) группы (фосфодиэфирные связи).
 и фосфатной группы.")
Рис. 2. Нуклертид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы
В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух цепей, ориентированных азотистыми основаниями друг к другу. Эта двухцепочечная молекула закручена по винтовой линии.
В ДНК встречается четыре вида азотистых оснований (аденин, гуанин, тимин и цитозин). Азотистые основания одной из цепей соединены с азотистыми основаниями другой цепи водородными связями согласно принципу комплементарности: аденин соединяется только с тимином (А-Т), гуанин — только с цитозином (Г-Ц). Именно эти пары и составляют «перекладины» винтовой «лестницы» ДНК (см.: рис. 2, 3 и 4).

Рис. 2. Азотистые основания
Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции, и принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК клеток содержит последовательности, выполняющие регуляторные и структурные функции.

Рис. 3. Репликация ДНК
Расположение базовых комбинаций химических соединений ДНК и количественные соотношения между этими комбинациями обеспечивают кодирование наследственной информации.
Образование новой ДНК (репликация)
- Процесс репликации: раскручивание двойной спирали ДНК — синтез комплементарных цепей ДНК-полимеразой — образование двух молекул ДНК из одной.
- Двойная спираль «расстегивается» на две ветви, когда ферменты разрушают связь между базовыми парами химических соединений.
- Каждая ветвь является элементом новой ДНК. Новые базовые пары соединяются в той же последовательности, что и в родительской ветви.
По завершении дупликации образуются две самостоятельные спирали, созданные из химических соединений родительской ДНК и имеющие с ней одинаковый генетический код. Таким путем ДНК способна перерывать информацию от клетки к клетке.
Более подробная информация:
СТРОЕНИЕ НУКЛЕИНОВЫХ КИСЛОТ

Рис. 4 . Азотистые основания: аденин, гуанин, цитозин, тимин
Дезоксирибонуклеиновая кислота (ДНК) относится к нуклеиновым кислотам. Нуклеиновые кислоты – это класс нерегулярных биополимеров, мономерами которых являются нуклеотиды.
НУКЛЕОТИДЫ состоят из азотистого основания, соединенного с пятиуглеродным углеводом (пентозой) – дезоксирибозой (в случае ДНК) или рибозой (в случае РНК), который соединяется с остатком фосфорной кислоты (H2PO3–).
Азотистые основания бывают двух типов: пиримидиновые основания – урацил (только в РНК), цитозин и тимин, пуриновые основания – аденин и гуанин.

Рис. 5. Структура нуклеотидов (слева), расположение нуклеотида в ДНК (снизу) и типы азотистых оснований (справа): пиримидиновые и пуриновые

Атомы углерода в молекуле пентозы нумеруются числами от 1 до 5. Фосфат соединяется с третьим и пятым атомами углерода. Так нуклеинотиды соединяются в цепь нуклеиновой кислоты. Таким образом, мы можем выделить 3’ и 5’-концы цепи ДНК:

Рис. 6. Выделение 3’ и 5’-концов цепи ДНК
Две цепи ДНК образуют двойную спираль. Эти цепи в спирали сориентированы в противоположных направлениях. В разных цепях ДНК азотистые основания соединены между собой с помощью водородных связей. Аденин всегда соединяется с тимином, а цитозин – с гуанином. Это называется правилом комплементарности (см. принцип комплементарности).
Правило комплементарности:
Например, если нам дана цепь ДНК, имеющая последовательность
3’– ATGTCCTAGCTGCTCG – 5’,
то вторая ей цепь будет комплементарна и направлена в противоположном направлении – от 5’-конца к 3’-концу:
5’– TACAGGATCGACGAGC– 3’.

Рис. 7. Направленность цепей молекулы ДНК и соединение азотистых оснований с помощью водородных связей
РЕПЛИКАЦИЯ ДНК
Репликация ДНК – это процесс удвоения молекулы ДНК путем матричного синтеза. В большинстве случаев естественной репликации ДНК праймером для синтеза ДНК является короткий фрагмент РНК (создаваемый заново). Такой рибонуклеотидный праймер создается ферментом праймазой (ДНК-праймаза у прокариот, ДНК-полимераза у эукариот), и впоследствии заменяется дезоксирибонуклеотидами полимеразой, выполняющей в норме функции репарации (исправления химических повреждений и разрывов в молекле ДНК).
Репликация происходит по полуконсервативному механизму. Это значит, что двойная спираль ДНК расплетается и на каждой из ее цепей по принципу комплементарности достраивается новая цепь. Дочерняя молекула ДНК, таким образом, содержит в себе одну цепь от материнской молекулы и одну вновь синтезированную. Репликация происходит в направлении от 3’ к 5’ концу материнской цепи.

Рис. 8. Репликация (удвоение) молекулы ДНК
ДНК-синтез – это не такой сложный процесс, как может показаться на первый взгляд. Если подумать, то для начала нужно разобраться, что же такое синтез. Это процесс объединения чего-либо в одно целое. Образование новой молекулы ДНК проходит в несколько этапов:
1) ДНК-топоизомераза, располагаясь перед вилкой репликации, разрезает ДНК для того, чтобы облегчить ее расплетание и раскручивание.
2) ДНК-хеликаза вслед за топоизомеразой влияет на процесс «расплетения» спирали ДНК.
3) ДНК-связывающие белки осуществляют связывание нитей ДНК, а также проводят их стабилизацию, не допуская их прилипания друг к другу.
4) ДНК-полимераза δ (дельта), согласовано со скоростью движения репликативной вилки, осуществляет синтез ведущей цепи дочерней ДНК в направлении 5’→3′ на матрице материнской нити ДНК по направлению от ее 3′-конца к 5′-концу (скорость до 100 пар нуклеотидов в секунду). Этим события на данной материнской нити ДНК ограничиваются.

Рис. 9. Схематическое изображение процесса репликации ДНК: (1) Отстающая цепь (запаздывающая нить), (2) Ведущая цепь (лидирующая нить), (3) ДНК-полимераза α (Polα), (4) ДНК-лигаза, (5) РНК-праймер, (6) Праймаза, (7) Фрагмент Оказаки, (8) ДНК-полимераза δ (Polδ), (9) Хеликаза, (10) Однонитевые ДНК-связывающие белки, (11) Топоизомераза.
Далее описан синтез отстающей цепи дочерней ДНК (см. Схему репликативной вилки и функции ферментов репликации)
Нагляднее о репликации ДНК см. видео →
5) Непосредственно сразу после расплетания и стабилизации другой нити материнской молекулы к ней присоединяется ДНК-полимераза α (альфа) и в направлении 5’→3′ синтезирует праймер (РНК-затравку) – последовательность РНК на матрице ДНК длиной от 10 до 200 нуклеотидов. После этого фермент удаляется с нити ДНК.
Вместо ДНК-полимеразы α к 3′-концу праймера присоединяется ДНК-полимераза ε.
6) ДНК-полимераза ε (эпсилон) как бы продолжает удлинять праймер, но в качестве субстрата встраивает дезоксирибонуклеотиды (в количестве 150-200 нуклеотидов). В результате образуется цельная нить из двух частей – РНК (т.е. праймер) и ДНК. ДНК-полимераза ε работает до тех пор, пока не встретит праймер предыдущего фрагмента Оказаки (синтезированный чуть ранее). После этого данный фермент удаляется с цепи.
7) ДНК-полимераза β (бета) встает вместо ДНК-полимеразы ε, движется в том же направлении (5’→3′) и удаляет рибонуклеотиды праймера, одновременно встраивая дезоксирибонуклеотиды на их место. Фермент работает до полного удаления праймера, т.е. пока на его пути не встанет дезоксирибонуклеотид (еще более ранее синтезированный ДНК-полимеразой ε). Связать результат свой работы и впереди стоящую ДНК фермент не в состоянии, поэтому он сходит с цепи.
В результате на матрице материнской нити «лежит» фрагмент дочерней ДНК. Он называется фрагмент Оказаки.
 ДНК-лигаза производит сшивку двух соседних фрагментов Оказаки, т.е. 5′-конца отрезка, синтезированного ДНК-полимеразой ε, и 3′-конца цепи, встроенного ДНК-полимеразой β.
ДНК-лигаза производит сшивку двух соседних фрагментов Оказаки, т.е. 5′-конца отрезка, синтезированного ДНК-полимеразой ε, и 3′-конца цепи, встроенного ДНК-полимеразой β.
СТРОЕНИЕ РНК
Рибонуклеиновая кислота (РНК) — одна из трёх основных макромолекул (две другие — ДНК и белки), которые содержатся в клетках всех живых организмов.
Так же, как ДНК, РНК состоит из длинной цепи, в которой каждое звено называется нуклеотидом. Каждый нуклеотид состоит из азотистого основания, сахара рибозы и фосфатной группы. Однако в отличие от ДНК, РНК обычно имеет не две цепи, а одну. Пентоза в РНК представлена рибозой, а не дезоксирибозой (у рибозы присутствует дополнительная гидроксильная группа на втором атоме углевода). Наконец, ДНК отличается от РНК по составу азотистых оснований: вместо тимина (Т) в РНК представлен урацил (U), который также комплементарен аденину.
Последовательность нуклеотидов позволяет РНК кодировать генетическую информацию. Все клеточные организмы используют РНК (мРНК) для программирования синтеза белков.
Клеточные РНК образуются в ходе процесса, называемого транскрипцией, то есть синтеза РНК на матрице ДНК, осуществляемого специальными ферментами — РНК-полимеразами.
Затем матричные РНК (мРНК) принимают участие в процессе, называемом трансляцией, т.е. синтеза белка на матрице мРНК при участии рибосом. Другие РНК после транскрипции подвергаются химическим модификациям, и после образования вторичной и третичной структур выполняют функции, зависящие от типа РНК.

Рис. 10. Отличие ДНК от РНК по азотистому основанию: вместо тимина (Т) в РНК представлен урацил (U), который также комплементарен аденину.
ТРАНСКРИПЦИЯ
Транскрипция – это процесс синтеза РНК на матрице ДНК. ДНК раскручивается на одном из участков. На одной из цепей содержится информация, которую необходимо скопировать на молекулу РНК – эта цепь называется кодирующей. Вторая цепь ДНК, комплементарная кодирующей, называется матричной. В процессе транскрипции на матричной цепи в направлении 3’ – 5’ (по цепи ДНК) синтезируется комплементарная ей цепь РНК. Таким образом, создается РНК-копия кодирующей цепи.

Рис. 11. Схематическое изображение транскрипции
Например, если нам дана последовательность кодирующей цепи
3’– ATGTCCTAGCTGCTCG – 5’,
то, по правилу комплементарности, матричная цепь будет нести последовательность
5’– TACAGGATCGACGAGC– 3’,
а синтезируемая с нее РНК – последовательность
3’– AUGUCCUAGCUGCUCG – 5’.
ТРАНСЛЯЦИЯ
Рассмотрим механизм синтеза белка на матрице РНК, а также генетический код и его свойства. Также для наглядности по ниже приведенной ссылке рекомендуем посмотреть небольшое видео о процессах транскрипции и трансляции, происходящих в живой клетке:
|
| В представленном видоролике (кнопка-ссылка слева) показан процесс образования белка из аминокислот. Наглядно (в анимированном варианте) продемонстрированы процессы транскрипции и трансляции. Биосинтез белка на рибосоме также кратко описан в разделе Аминокислоты белков. Более подробное видео о геноме, ДНК и ее структуре, а также процессах кодировки представленно ниже на данной странице: Видео по теме ДНК |


Рис. 12. Процесс синтеза белка: ДНК кодирует РНК, РНК кодирует белок
Трансляция — это процесс, посредством которого генетическая информация преобразуется в белки, рабочие лошадки клетки. Небольшие молекулы, называемые переносными РНК («тРНК»), играют решающую роль в трансляции; они являются молекулами-адаптерами, которые соответствуют кодонам (строительным блокам генетической информации) с аминокислотами (строительными блоками белков). Организмы несут множество типов тРНК, каждая из которых кодируется одним или несколькими генами («набор генов тРНК»).
Вообще говоря, функция набора генов тРНК — переводить 61 тип кодонов в 20 различных типов аминокислот — сохраняется в разных организмах. Тем не менее, состав набора генов тРНК может значительно варьировать между организмами.
ГЕНЕТИЧЕСКИЙ КОД
Генетический код — способ кодирования аминокислотной последовательности белков с помощью последовательности нуклеотидов. Каждая аминокислота кодируется последовательностью из трех нуклеотидов — кодоном или триплетом.
Генетический код, общий для большинства про- и эукариот. В таблице приведены все 64 кодона и указаны соответствующие аминокислоты. Порядок оснований — от 5′ к 3′ концу мРНК.
Таблица 1. Стандартный генетический код
| 1-е ние | 2-е основание | 3-е ние | |||||||
| U | C | A | G | ||||||
| U | UUU | Фенилаланин (Phe/F) | UCU | Серин (Ser/S) | UAU | Тирозин (Tyr/Y) | UGU | Цистеин (Cys/C) | U |
| UUC | UCC | UAC | UGC | C | |||||
| UUA | Лейцин (Leu/L) | UCA | UAA | Стоп-кодон** | UGA | Стоп-кодон** | A | ||
| UUG | UCG | UAG | Стоп-кодон** | UGG | Триптофан (Trp/W) | G | |||
| C | CUU | CCU | Пролин (Pro/P) | CAU | Гистидин (His/H) | CGU | Аргинин (Arg/R) | U | |
| CUC | CCC | CAC | CGC | C | |||||
| CUA | CCA | CAA | Глутамин (Gln/Q) | CGA | A | ||||
| CUG | CCG | CAG | CGG | G | |||||
| A | AUU | Изолейцин (Ile/I) | ACU | Треонин (Thr/T) | AAU | Аспарагин (Asn/N) | AGU | Серин (Ser/S) | U |
| AUC | ACC | AAC | AGC | C | |||||
| AUA | ACA | AAA | Лизин (Lys/K) | AGA | Аргинин (Arg/R) | A | |||
| AUG | Метионин* (Met/M) | ACG | AAG | AGG | G | ||||
| G | GUU | Валин (Val/V) | GCU | Аланин (Ala/A) | GAU | Аспарагиновая кислота (Asp/D) | GGU | Глицин (Gly/G) | U |
| GUC | GCC | GAC | GGC | C | |||||
| GUA | GCA | GAA | Глутаминовая кислота (Glu/E) | GGA | A | ||||
| GUG | GCG | GAG | GGG | G |
Среди триплетов есть 4 специальных последовательности, выполняющих функции «знаков препинания»:
- *Триплет AUG, также кодирующий метионин, называется старт-кодоном. С этого кодона начинается синтез молекулы белка. Таким образом, во время синтеза белка, первой аминокислотой в последовательности всегда будет метионин.
- **Триплеты UAA, UAG и UGA называются стоп-кодонами и не кодируют ни одной аминокислоты. На этих последовательностях синтез белка прекращается.
Свойства генетического кода
1. Триплетность. Каждая аминокислота кодируется последовательностью из трех нуклеотидов – триплетом или кодоном.

2. Непрерывность. Между триплетами нет никаких дополнительных нуклеотидов, информация считывается непрерывно.

3. Неперекрываемость. Один нуклеотид не может входить одновременно в два триплета.

4. Однозначность. Один кодон может кодировать только одну аминокислоту.

5. Вырожденность. Одна аминокислота может кодироваться несколькими разными кодонами.

6. Универсальность. Генетический код одинаков для всех живых организмов.
Пример. Нам дана последовательность кодирующей цепи:
3’– CCGATTGCACGTCGATCGTATA– 5’.
Матричная цепь будет иметь последовательность:
5’– GGCTAACGTGCAGCTAGCATAT– 3’.
Теперь «синтезируем» с этой цепи информационную РНК:
3’– CCGAUUGCACGUCGAUCGUAUA– 5’.
Синтез белка идет в направлении 5’ → 3’, следовательно, нам нужно перевернуть последовательность, чтобы «прочитать» генетический код:
5’– AUAUGCUAGCUGCACGUUAGCC– 3’.
Теперь найдем старт-кодон AUG:
5’– AUAUGCUAGCUGCACGUUAGCC– 3’.
Разделим последовательность на триплеты:
![]()
Найдем стоп-кодон и согласно таблице генетического кода запишем последовательность аминокислот:

Центральная догма молекулярной биологии звучит следующим образом: информация с ДНК передается на РНК (транскрипция), с РНК – на белок (трансляция). ДНК также может удваиваться путем репликации, и также возможен процесс обратной транскрипции, когда по матрице РНК синтезируется ДНК, но такой процесс в основном характерен для вирусов.

Рис. 13. Центральная догма молекулярной биологии
ГЕНОМ: ГЕНЫ и ХРОМОСОМЫ
(общие понятия)
Геном — совокупность всех генов организма; его полный хромосомный набор.
Термин «геном» был предложен Г. Винклером в 1920 г. для описания совокупности генов, заключенных в гаплоидном наборе хромосом организмов одного биологического вида. Первоначальный смысл этого термина указывал на то, что понятие генома в отличие от генотипа является генетической характеристикой вида в целом, а не отдельной особи. С развитием молекулярной генетики значение данного термина изменилось. Известно, что ДНК, которая является носителем генетической информации у большинства организмов и, следовательно, составляет основу генома, включает в себя не только гены в современном смысле этого слова. Большая часть ДНК эукариотических клеток представлена некодирующими («избыточными») последовательностями нуклеотидов, которые не заключают в себе информации о белках и нуклеиновых кислотах. Таким образом, основную часть генома любого организма составляет вся ДНК его гаплоидного набора хромосом.
Гены — это участки молекул ДНК, кодирующие полипептиды и молекулы РНК
За последнее столетие наше представление о генах существенно изменилось. Ранее геном называли участок хромосомы, кодирующий или определяющий один признак или фенотипическое (видимое) свойство, например цвет глаз.
|
|
| Рис. 14. Соответствие между кодирующими участками ДНК, мРНК и аминокислотной последовательностью полипептидной цепи. |

В 1940 г. Джордж Бидл и Эдвард Тейтем предложили молекулярное определение гена. Ученые обрабатывали споры гриба Neurospora crassa рентгеновским излучением и другими агентами, вызывающими изменения в последовательности ДНК (мутации), и обнаружили мутантные штаммы гриба, утратившие некоторые специфические ферменты, что в некоторых случаях приводило к нарушению целого метаболического пути. Бидл и Тейтем пришли к выводу, что ген — это участок генетического материала, который определяет или кодирует один фермент. Так появилась гипотеза «один ген — один фермент». Позднее эта концепция была расширена до определения «один ген — один полипептид», поскольку многие гены кодируют белки, не являющиеся ферментами, а полипептид может оказаться субъединицей сложного белкового комплекса.
На рис. 14 показана схема того, как триплеты нуклеотидов в ДНК определяют полипептид — аминокислотную последовательность белка при посредничестве мРНК. Одна из цепей ДНК играет роль матрицы для синтеза мРНК, нуклеотидные триплеты (кодоны) которой комплементарны триплетам ДНК. У некоторых бактерий и многих эукариот кодирующие последовательности прерываются некодирующими участками(так называемыми интронами).
Современное биохимическое определение гена еще более конкретно. Генами называются все участки ДНК, кодирующие первичную последовательность конечных продуктов, к которым относятся полипептиды или РНК, обладающие структурной или каталитической функцией.
Наряду с генами ДНК содержит и другие последовательности, выполняющие исключительно регуляторную функцию. Регуляторные последовательности могут обозначать начало или конец генов, влиять на транскрипцию или указывать место инициации репликации или рекомбинации. Некоторые гены могут экспрессироваться разными путями, при этом один и тот же участок ДНК служит матрицей для образования разных продуктов.
Мы можем приблизительно рассчитать минимальный размер гена, кодирующего средний белок. Каждая аминокислота в полипептидной цепи кодируется последовательностью из трех нуклеотидов; последовательности этих триплетов (кодонов) соответствуют цепочке аминокислот в полипептиде, который кодируется данным геном. Полипептидная цепь из 350 аминокислотных остатков (цепь средней длины) соответствует последовательности из 1050 п.н. (пар нуклеотидов). Однако многие гены эукариот и некоторые гены прокариот прерываются сегментами ДНК, не несущими информации о белке, и поэтому оказываются значительно длиннее, чем показывает простой расчет.
Сколько генов в одной хромосоме?
Рис. 15. Вид хромосом в прокаритической (слева) и эукариотической клеках. Гистоны (Histones) — обширный класс ядерных белков, выполняющих две основные функции: они участвуют в упаковке нитей ДНК в ядре и в эпигенетической регуляции таких ядерных процессов, как транскрипция, репликация и репарация.

ДНК прокариот устроена более просто: их клетки не имеют ядра, поэтому ДНК находится непосредственно в цитоплазме в форме нуклеоида.
 Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Прокариоты (Бактерии).
 Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Большинство плазмид состоит всего из нескольких тысяч пар нуклеотидов, некоторые содержат более 10000 п. н. Они несут генетическую информацию и реплицируются с образованием дочерних плазмид, которые попадают в дочерние клетки в процессе деления родительской клетки. Плазмиды обнаружены не только в бактериях, но также в дрожжах и других грибах. Во многих случаях плазмиды не дают никаких преимуществ клеткам-хозяевам, и их единственная задача — независимое воспроизведение. Однако некоторые плазмиды несут полезные для хозяина гены. Например, содержащиеся в плазмидах гены могут придавать клеткам бактерий устойчивость к антибактериальным агентам. Плазмиды, несущие ген β-лактамазы, обеспечивают устойчивость к β-лактамным антибиотикам, таким как пенициллин и амоксициллин. Плазмиды могут переходить от клеток, устойчивых к антибиотикам, к другим клеткам того же или другого вида бактерий, в результате чего эти клетки также становятся резистентными. Интенсивное применение антибиотиков является мощным селективным фактором, способствующим распространению плазмид, кодирующих устойчивость к антибиотикам (а также транспозонов, которые кодируют аналогичные гены) среди болезнетворных бактерий, и приводит к появлению бактериальных штаммов с устойчивостью к нескольким антибиотикам. Врачи начинают понимать опасность широкого использования антибиотиков и назначают их только в случае острой необходимости. По аналогичным причинам ограничивается широкое использование антибиотиков для лечения сельскохозяйственных животных.
См. также: Равин Н.В., Шестаков С.В. Геном прокариот // Вавиловский журнал генетики и селекции, 2013. Т. 17. № 4/2. С. 972–984.
Эукариоты.
Таблица 2. ДНК, гены и хромосомы некоторых организмов
| Общая ДНК, п.н. | Число хромосом* | Примерное число генов | |
| Escherichia coli (бактерия) | 4 639 675 | 1 | 4 435 |
| Saccharomyces cerevisiae (дрожжи) | 12 080 000 | 16** | 5 860 |
| Caenorhabditis elegans (нематода) | 90 269 800 | 12*** | 23 000 |
| Arabidopsis thaliana (растение) | 119 186 200 | 10 | 33 000 |
| Drosophila melanogaster (плодовая мушка) | 120 367 260 | 18 | 20 000 |
| Oryza sativa (рис) | 480 000 000 | 24 | 57 000 |
| Mus musculus (мышь) | 2 634 266 500 | 40 | 27 000 |
| Homo sapiens (человек) | 3 070 128 600 | 46 | 29 000 |
Примечание. Информация постоянно обновляется; для получения более свежей информации обратитесь к сайтам, посвященным отдельным геномным проектам
*Для всех эукариот, кроме дрожжей, приводится диплоидный набор хромосом. Диплоидный набор хромосом (от греч. diploos- двойной и eidos- вид) – двойной набор хромосом (2n), каждая из которых имеет себе гомологичную.
**Гаплоидный набор. Дикие штаммы дрожжей обычно имеют восемь (октаплоидный) или больше наборов таких хромосом.
***Для самок с двумя Х хромосомами. У самцов есть Х хромосома, но нет Y, т. е. всего 11 хромосом.
В клетке дрожжей, одних из самых маленьких эукариот, в 2,6 раза больше ДНК, чем в клетке E. coli (табл. 2). Клетки плодовой мушки Drosophila, классического объекта генетических исследований, содержат в 35 раз больше ДНК, а клетки человека — примерно в 700 раз больше ДНК, чем клетки E. coli. Многие растения и амфибии содержат еще больше ДНК. Генетический материал клеток эукариот организован в виде хромосом. Диплоидный набор хромосом (2n) зависит от вида организма (табл. 2).
Например, в соматической клетке человека 46 хромосом (рис. 17). Каждая хромосома эукариотической клетки, как показано на рис. 17, а, содержит одну очень крупную двухспиральную молекулу ДНК. Двадцать четыре хромосомы человека (22 парные хромосомы и две половые хромосомы X и Y) различаются по длине более чем в 25 раз. Каждая хромосома эукариот содержит определенный набор генов.

Рис. 17. Хромосомы эукариот. а — пара связанных и конденсированных сестринских хроматид из хромосомы человека. В такой форме эукариотические хромосомы пребывают после репликации и в метафазе в процессе митоза. б — полный набор хромосом из лейкоцита одного из авторов книги. В каждой нормальной соматической клетке человека содержится 46 хромосом.

Размер и функция ДНК как матрицы для хранения и передачи наследственного материала объясняют наличие особых структурных элементов в организации этой молекулы. У высших организмов ДНК распределена между хромосомами.
Совокупность ДНК (хромосом) организма называется геномом. Хромосомы находятся в клеточном ядре и формируют структуру, называемую хроматином. Хроматин представляет собой комплекс ДНК и основных белков (гистонов) в соотношении 1:1. Длину ДНК обычно измеряют числом пар комплементарных нуклеотидов (п.н.). Например, 3-я хромосома человека представляет собой молекулу ДНК размером 160 млн п.н.. Выделенная линеаризованная ДНК размером 3*106 п.н. имеет длину примерно 1 мм, следовательно, линеаризованная молекула 3-й хромосомы человека была бы 5 мм в длину, а ДНК всех 23 хромосом (~3*109 п.н., MR = 1,8*1012) гаплоидной клетки – яйцеклетки или сперматозоида – в линеаризованном виде составляла бы 1 м. За исключением половых клеток, все клетки организма человека (их около 1013) содержат двойной набор хромосом. При клеточном делении все 46 молекул ДНК реплицируются и снова организуются в 46 хромосом.
Если соединить между собой молекулы ДНК человеческого генома (22 хромосомы и хромосомы X и Y или Х и Х), получится последовательность длиной около одного метра. Прим.: У всех млекопитающих и других организмов с гетерогаметным мужским полом, у самок две X-хромосомы (XX), а у самцов — одна X-хромосома и одна Y-хромосома (XY).
Большинство клеток человека диплоидны, поэтому общая длина ДНК таких клеток около 2м. У взрослого человека примерно 1014 клеток, таким образом, общая длина всех молекул ДНК составляет 2・1011 км. Для сравнения, окружность Земли — 4・104 км, а расстояние от Земли до Солнца — 1,5・108 км. Вот как удивительно компактно упакована ДНК в наших клетках!
В клетках эукариот есть и другие органеллы, содержащие ДНК, — это митохондрии и хлоропласты. Выдвигалось множество гипотез относительно происхождения ДНК митохондрий и хлоропластов. Общепризнанная сегодня точка зрения заключается в том, что они представляют собой рудименты хромосом древних бактерий, которые проникли в цитоплазму хозяйских клеток и стали предшественниками этих органелл. Митохондриальная ДНК кодирует митохондриальные тРНК и рРНК, а также несколько митохондриальных белков. Более 95% митохондриальных белков кодируется ядерной ДНК.
СТРОЕНИЕ ГЕНОВ
Рассмотрим строение гена у прокариот и эукариот, их сходства и различия. Несмотря на то, что ген — это участок ДНК, кодирующий всего один белок или РНК, кроме непосредственно кодирующей части, он также включает в себя регуляторные и иные структурные элементы, имеющие разное строение у прокариот и эукариот.
Кодирующая последовательность – основная структурно-функциональная единица гена, именно в ней находятся триплеты нуклеотидов, кодирующие аминокислотную последовательность. Она начинается со старт-кодона и заканчивается стоп-кодоном.
До и после кодирующей последовательности находятся нетранслируемые 5’- и 3’-последовательности. Они выполняют регуляторные и вспомогательные функции, например, обеспечивают посадку рибосомы на и-РНК.
Нетранслируемые и кодирующая последовательности составлют единицу транскрипции – транскрибируемый участок ДНК, то есть участок ДНК, с которого происходит синтез и-РНК.
Терминатор – нетранскрибируемый участок ДНК в конце гена, на котором останавливается синтез РНК.
В начале гена находится регуляторная область, включающая в себя промотор и оператор.
Промотор – последовательность, с которой связывается полимераза в процессе инициации транскрипции. Оператор – это область, с которой могут связываться специальные белки – репрессоры, которые могут уменьшать активность синтеза РНК с этого гена – иначе говоря, уменьшать его экспрессию.
Строение генов у прокариот
Общий план строения генов у прокариот и эукариот не отличается – и те, и другие содержат регуляторную область с промотором и оператором, единицу транскрипции с кодирующей и нетранслируемыми последовательностями и терминатор. Однако организация генов у прокариот и эукариот отличается.

Рис. 18. Схема строения гена у прокариот (бактерий) — изображение увеличивается
В начале и в конце оперона есть единые регуляторные области для нескольких структурных генов. С транскрибируемого участка оперона считывается одна молекула и-РНК, которая содержит несколько кодирующих последовательностей, в каждой из которых есть свой старт- и стоп-кодон. С каждого из таких участков синтезируется один белок. Таким образом, с одной молекулы и-РНК синтезируется несколько молекул белка.
Для прокариот характерно объединение нескольких генов в единую функциональную единицу – оперон. Работу оперона могут регулировать другие гены, которые могут быть заметно удалены от самого оперона – регуляторы. Белок, транслируемый с этого гена называется репрессор. Он связывается с оператором оперона, регулируя экспрессию сразу всех генов, в нем содержащихся.
Для прокариот также характерно явление сопряжения транскрипции и трансляции.

Рис. 19 Явление сопряжения транскрипции и трансляции у прокариот — изображение увеличивается
Такое сопряжение не встречается у эукариот из-за наличия у них ядерной оболочки, отделяющей цитоплазму, где происходит трансляция, от генетического материала, на котором происходит транскрипция. У прокариот во время синтеза РНК на матрице ДНК с синтезируемой молекулой РНК может сразу связываться рибосома. Таким образом, трансляция начинается еще до завершения транскрипции. Более того, с одной молекулой РНК может одновременно связываться несколько рибосом, синтезируя сразу несколько молекул одного белка.
Строение генов у эукариот
Гены и хромосомы эукариот очень сложно организованы
У бактерий многих видов всего одна хромосома, и почти во всех случаях в каждой хромосоме присутствует по одной копии каждого гена. Лишь немногие гены, например гены рРНК, содержатся в нескольких копиях. Гены и регуляторные последовательности составляют практически весь геном прокариот. Более того, почти каждый ген строго соответствует аминокислотной последовательности (или последовательности РНК), которую он кодирует (рис. 14).
Структурная и функциональная организация генов эукариот гораздо сложнее. Исследование хромосом эукариот, а позднее секвенирование полных последовательностей геномов эукариот принесло много сюрпризов. Многие, если не большинство, генов эукариот обладают интересной особенностью: их нуклеотидные последовательности содержат один или несколько участков ДНК, в которых не кодируется аминокислотная последовательность полипептидного продукта. Такие нетранслируемые вставки нарушают прямое соответствие между нуклеотидной последовательностью гена и аминокислотной последовательностью кодируемого полипептида. Эти нетранслируемые сегменты в составе генов называют интронами, или встроенными последовательностями, а кодирующие сегменты — экзонами. У прокариот лишь немногие гены содержат интроны.
Итак, у эукариот практически не встречается объединение генов в опероны, и кодирующая последовательность гена эукариот чаще всего разделена на транслируемые участки – экзоны, и нетранслируемые участки – интроны.
В большинстве случаев функция интронов не установлена. В целом, лишь около 1,5% ДНК человека являются ≪кодирующими≫, т. е. несут информацию о белках или РНК. Однако с учетом крупных интронов получается, что ДНК человека на 30% состоит из генов. Поскольку гены составляют относительно небольшую долю в геноме человека, значительная часть ДНК остается неучтенной.

Рис. 16. Схема строение гена у эукариот — изображение увеличивается
С каждого гена сначала синтезируется незрелая, или пре-РНК, которая содержит в себе как интроны, так и экзоны.
После этого проходит процесс сплайсинга, в результате которого интронные участки вырезаются, и образуется зрелая иРНК, с которой может быть синтезирован белок.

Рис. 20. Процесс альтернативного сплайсинга — изображение увеличивается
Такая организация генов позволяет, например, осуществить процесс альтернативного сплайсинга, когда с одного гена могут быть синтезированы разные формы белка, за счет того, что в процессе сплайсинга экзоны могут сшиваться в разных последовательностях.
Сравнение строения генов прокариот и эукариот

Рис. 21. Отличия в строении генов прокариот и эукариот — изображение увеличивается
МУТАЦИИ И МУТАГЕНЕЗ
Мутацией называется стойкое изменение генотипа, то есть изменение нуклеотидной последовательности.
Процесс, который приводит к возникновению мутаций называется мутагенезом, а организм, все клетки которого несут одну и ту же мутацию — мутантом.
Мутационная теория была впервые сформулирована Гуго де Фризом в 1903 году. Современный ее вариант включает в себя следующие положения:
1. Мутации возникают внезапно, скачкообразно.
2. Мутации передаются из поколения в поколение.
3. Мутации могут быть полезными, вредными или нейтральными, доминантными или рецессивными.
4. Вероятность обнаружения мутаций зависит от числа исследованных особей.
5. Сходные мутации могут возникать повторно.
6. Мутации не направленны.
Мутации могут возникать под действием различных факторов. Различают мутации, возникшие под действием мутагенных воздействий: физических (например, ультрафиолета или радиации), химических (например, колхицина или активных форм кислорода) и биологических (например, вирусов). Также мутации могут быть вызваны ошибками репликации.
В зависимости от условий появления мутации подразделяют на спонтанные — то есть мутации, возникшие в нормальных условиях, и индуцированые — то есть мутации, которые возникли при особых условиях.
Мутации могут возникать не только в ядерной ДНК, но и, например, в ДНК митохондрий или пластид. Соответственно, мы можем выделять ядерные и цитоплазматические мутации.
В результате возникновения мутаций часто могут появляться новые аллели. Если мутантный аллель подавляет действие нормального, мутация называется доминантной. Если нормальный аллель подавляет мутантный, такая мутация называется рецессивной. Большинство мутаций, приводящих к возникновению новых аллелей являются рецессивными.
По эффекту выделяют мутации адаптивные, приводящие к повышению приспособленности организма к среде, нейтральные, не влияющие на выживаемость, вредные, понижающие приспособленность организмов к условиям среды и летальные, приводящие к смерти организма на ранних стадиях развития.
По последствиям выделяются мутации, приводящие к потери функции белка, мутации, приводящие к возникновению у белка новой функции, а также мутации, которые изменяют дозу гена, и, соответственно, дозу белка синтезируемого с него.
Мутация может возникнуть к любой клетке организма. Если мутация возникает в половой клетке, она называется герминативной (герминальной, или генеративной). Такие мутации не проявляются у того организма, у которого они появились, но приводят к появлению мутантов в потомстве и передаются по наследству, поэтому они важны для генетики и эволюции. Если мутация возникает в любой другой клетке, она называется соматической. Такая мутация может в той или иной степени проявляться у того организма, у которого она возникла, например, приводить к образованию раковых опухолей. Однако такая мутация не передается по наследству и не влияет на потомков.
Мутации могут затрагивать разные по размеру участки генома. Выделяют генные, хромосомные и геномные мутации.
Генные мутации
Мутации, которые возникают в масштабе меньшем, чем один ген, называются генными, или точечными (точковыми). Такие мутации приводят к изменению одного и нескольких нуклеотидов в последовательности. Среди генных мутаций выделяют замены, приводящие к замене одного нуклеотида на другой, делеции, приводящие к выпадению одного из нуклеотидов, инсерции, приводящие к добавлению лишнего нуклеотида в последовательность.

Рис. 23. Генные (точечные) мутации
По механизму воздействия на белок, генные мутации делят на: синонимичные, которые (в результате вырожденности генетического кода) не приводят к изменению аминокислотного состава белкового продукта, миссенс-мутации, которые приводят к замене одной аминокислоты на другую и могут влиять на структуру синтезируемого белка, хотя часто они оказываются незначительными, нонсенс-мутации, приводящие к замене кодирующего кодона на стоп-кодон, мутации, приводящие к нарушению сплайсинга:

Рис. 24. Схемы мутаций
Также по механизму воздействия на белок выделяют мутации, приводящие к сдвигу рамки считывания, например, инсерции и делеции. Такие мутации, как и нонсенс-мутации, хоть и возникают в одной точке гена, часто воздействуют на всю структуру белка, что может привести к полному изменению его структуры.

Рис. 25. Схема мутации, приводящей к сдвигу рамки считывания
Хромосомные мутации

Рис. 26. Хромосомные абберации
Хромосомными мутациями называются мутации, которые затрагивают отдельные гены в рамках одной хромосомы. Различают делеции, когда теряется один или несколько генов, дупликации, когда удваивается тот или иной ген или несколько генов, инверсии, когда участок хромосомы поворачивается на 180 градусов, транслокации, когда гены переходят с одной хромосомы на другую.

Рис. 27. Схемы хромосомных мутаций: делеции, дупликации, инверсии
|
|
|
| Рис. 28. Транслокация | Рис. 29. Хромосома до и после дупликации |


Геномные мутации
Наконец, геномные мутации затрагивают весь геном целиком, то есть меняется количество хромосом. Выделяют полиплоидии — увеличение плоидности клетки, и анеуплоидии, то есть изменение количества хромосом, например, трисомии (наличие у одной из хромосом дополнительного гомолога) и моносомии (отсутствие у хромосомы гомолога).
Видео по теме ДНК
РЕПЛИКАЦИЯ ДНК, КОДИРОВАНИЕ РНК, СИНТЕЗ БЕЛКА
(Если видео не отображается оно доступно по ссылке→)
См. дополнительно:
- Нуклеиновые кислоты (PDF)
- Общие сведения о секвенировании биополимеров
- Метагеномика и микробиом
- Бактериальный иммунитет и система CRISPR/Cas
- Трансляция белка на рисбосоме (общие сведения)
- Раскрыт секрет спиральной структуры ДНК (новое о ДНК)
- Антимутагенные свойства пробиотиков (в свете защиты ДНК)
- МикроРНК, микробиом кишечника и иммунитет
- Эпигенетика, короткоцепочечные жирные кислоты и врожденная иммунная память
- Замедление старения: роль питательных веществ и микробиоты в модуляции эпигенома (о метилировании ДНК)
Литература в помощь:
Будьте здоровы!
ССЫЛКИ К РАЗДЕЛУ О ПРЕПАРАТАХ ПРОБИОТИКАХ
- ПРОБИОТИКИ
- ПРОБИОТИКИ И ПРЕБИОТИКИ
- СИНБИОТИКИ
- ДОМАШНИЕ ЗАКВАСКИ
- КОНЦЕНТРАТ БИФИДОБАКТЕРИЙ ЖИДКИЙ
- ПРОПИОНИКС
- ЙОДПРОПИОНИКС
- СЕЛЕНПРОПИОНИКС
- БИФИКАРДИО
- ПРОБИОТИКИ С ПНЖК
- МИКРОЭЛЕМЕНТНЫЙ СОСТАВ
- БИФИДОБАКТЕРИИ
- ПРОПИОНОВОКИСЛЫЕ БАКТЕРИИ
- МИКРОБИОМ ЧЕЛОВЕКА
- МИКРОФЛОРА ЖКТ
- ДИСБИОЗ КИШЕЧНИКА
- МИКРОБИОМ и ВЗК
- МИКРОБИОМ И РАК
- МИКРОБИОМ, СЕРДЦЕ И СОСУДЫ
- МИКРОБИОМ И ПЕЧЕНЬ
- МИКРОБИОМ И ПОЧКИ
- МИКРОБИОМ И ЛЕГКИЕ
- МИКРОБИОМ И ПОДЖЕЛУДОЧНАЯ ЖЕЛЕЗА
- МИКРОБИОМ И ЩИТОВИДНАЯ ЖЕЛЕЗА
- МИКРОБИОМ И КОЖНЫЕ БОЛЕЗНИ
- МИКРОБИОМ И КОСТИ
- МИКРОБИОМ И ОЖИРЕНИЕ
- МИКРОБИОМ И САХАРНЫЙ ДИАБЕТ
- МИКРОБИОМ И ФУНКЦИИ МОЗГА
- АНТИОКСИДАНТНЫЕ СВОЙСТВА
- АНТИОКСИДАНТНЫЕ ФЕРМЕНТЫ
- АНТИМУТАГЕННАЯ АКТИВНОСТЬ
- МИКРОБИОМ и ИММУНИТЕТ
- МИКРОБИОМ И АУТОИММУННЫЕ БОЛЕЗНИ
- ПРОБИОТИКИ и ГРУДНЫЕ ДЕТИ
- ПРОБИОТИКИ, БЕРЕМЕННОСТЬ, РОДЫ
- ВИТАМИННЫЙ СИНТЕЗ
- АМИНОКИСЛОТНЫЙ СИНТЕЗ
- АНТИМИКРОБНЫЕ СВОЙСТВА
- КОРОТКОЦЕПОЧЕЧНЫЕ ЖИРНЫЕ КИСЛОТЫ
- СИНТЕЗ БАКТЕРИОЦИНОВ
- АЛИМЕНТАРНЫЕ ЗАБОЛЕВАНИЯ
- МИКРОБИОМ И ПРЕЦИЗИОННОЕ ПИТАНИЕ
- ФУНКЦИОНАЛЬНОЕ ПИТАНИЕ
- ПРОБИОТИКИ ДЛЯ СПОРТСМЕНОВ
- ПРОИЗВОДСТВО ПРОБИОТИКОВ
- ЗАКВАСКИ ДЛЯ ПИЩЕВОЙ ПРОМЫШЛЕННОСТИ
- НОВОСТИ
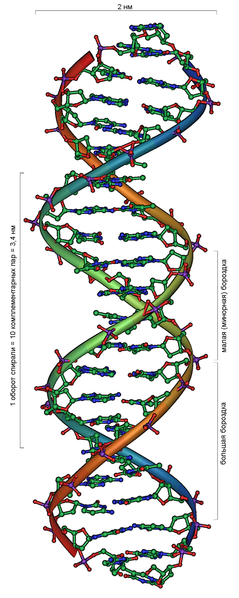
Двойная спираль ДНК
Дезоксирибонуклеи́новая кислота́ (ДНК) — один из двух типов нуклеиновых кислот, обеспечивающих хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов. Основная роль ДНК в клетках — долговременное хранение информации о структуре РНК и белков.
В клетках эукариот (например, животных или растений) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органоидах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У них и у низших эукариот (например, дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами. Кроме того, одно- или двухцепочечные молекулы ДНК могут образовывать геном ДНК-содержащих вирусов.
С химической точки зрения, ДНК — это длинная полимерная молекула, состоящая из повторяющихся блоков, нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в цепи образуются за счёт дезоксирибозы и фосфатной группы. В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух цепей, ориентированных азотистыми основаниями друг к другу. Эта двухцепочечная молекула спирализована. В целом структура молекулы ДНК получила название «двойной спирали».
В ДНК встречается четыре вида азотистых оснований (аденин, гуанин, тимин и цитозин). Азотистые основания одной из цепей соединены с азотистыми основаниями другой цепи водородными связями согласно принципу комплементарности: аденин соединяется только с тимином, гуанин — только с цитозином. Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции и принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК клеток содержит последовательности, выполняющие регуляторные и структурные функции. Кроме того, в геноме эукариот часто встречаются участки, принадлежащие «генетическим паразитам», например, транспозонам.
Расшифровка структуры ДНК (1953 г.) стала одним из поворотных моментов в истории биологии. За выдающийся вклад в это открытие Фрэнсису Крику, Джеймсу Уотсону, Морису Уилкинсу была присуждена Нобелевская премия по физиологии и медицине 1962 г.
Содержание
- 1 История изучения
- 2 Структура молекулы
- 2.1 Нуклеотиды
- 2.2 Двойная спираль
- 2.3 Образование связей между основаниями
- 2.4 Химические модификации оснований
- 2.5 Повреждение ДНК
- 2.6 Суперскрученность
- 2.7 Структуры на концах хромосом
- 3 Биологические функции
- 3.1 Структура генома
- 3.2 Последовательности генома, не кодирующие белок
- 3.3 Транскрипция и трансляция
- 3.4 Репликация
- 4 Взаимодействие с белками
- 4.1 Структурные и регуляторные белки
- 4.2 Ферменты, модифицирующие ДНК
- 4.2.1 Топоизомеразы и хеликазы
- 4.2.2 Нуклеазы и лигазы
- 4.2.3 Полимеразы
- 5 Генетическая рекомбинация
- 6 Эволюция метаболизма, основанного на ДНК
- 7 См. также
- 8 Ссылки
- 9 Рекомендуемая литература
- 10 Литература
История изучения


ДНК была открыта Иоганном Фридрихом Мишером в 1869 году. Вначале новое вещество получило название нуклеин, а позже, когда Мишер определил, что это вещество обладает кислотными свойствами, вещество получило название нуклеиновая кислота [1]. Биологическая функция новооткрытого вещества была неясна, и долгое время ДНК считалась запасником фосфора в организме. Более того, даже в начале XX века многие биологи считали, что ДНК не имеет никакого отношения к передаче информации, поскольку строение молекулы, по их мнению, было слишком однообразным и не могло содержать закодированную информацию.
Постепенно было доказано, что именно ДНК, а не белки, как считалось раньше, является носителем генетической информации. Одно из первых решающих доказательств принесли эксперименты О. Эвери, Колина Мак-Леода и Маклин Мак-Карти (1944 г.) по трансформации бактерий. Им удалось показать, что за так называемую трансформацию (приобретение болезнетворных свойств безвредной культурой в результате добавления в неё мёртвых болезнетворных бактерий) отвечают выделенные из пневмококков ДНК. Эксперимент американских учёных Алфреда Херши и Марты Чейз (Эксперимент Херши—Чейз, 1952 г.) с помеченными радиоактивными изотопами белками и ДНК бактериофагов показали, что в заражённую клетку передаётся только нуклеиновая кислота фага, а новое поколение фага содержит такие же белки и нуклеиновую кислоту, как исходный фаг[2].
Вплоть до 50-х годов XX века точное строение ДНК, как и способ передачи наследственной информации, оставалось неизвестным. Хотя и было доподлинно известно, что ДНК состоит из нескольких цепочек, состоящих из нуклеотидов, никто не знал точно, сколько этих цепочек и как они соединены.
Структура двойной спирали ДНК была предложена Френсисом Криком и Джеймсом Уотсоном в 1953 году на основании рентгеноструктурных данных, полученных Морисом Уилкинсом и Розалинд Франклин, и «правил Чаргаффа», согласно которым в каждой молекуле ДНК соблюдаются строгие соотношения, связывающие между собой количество азотистых оснований разных типов[3]. Позже предложенная Уотсоном и Криком модель строения ДНК была доказана, а их работа отмечена Нобелевской премией по физиологии и медицине 1962 г. Среди лауреатов не было скончавшейся к тому времени Розалинды Франклин, так как премия не присуждается посмертно[4].
Структура молекулы
Нуклеотиды
Структуры оснований, наиболее часто встречающихся в составе ДНК
Дезоксирибонуклеиновая кислота (ДНК) представляет собой биополимер (полианион), мономером которого является нуклеотид[5][6].
Каждый нуклеотид состоит из остатка фосфорной кислоты присоединённого по 5′-положению к сахару дезоксирибозе, к которому также через гликозидную связь (C—N) по 1′-положению присоединено одно из четырёх азотистых оснований. Именно наличие характерного сахара и составляет одно из главных различий между ДНК и РНК, зафиксированное в названиях этих нуклеиновых кислот (в состав РНК входит сахар рибоза)[7]. Пример нуклеотида — аденозинмонофосфат — где основание, присоединённое к фосфату и рибозе, это аденин, показан на рисунке.
Исходя из структуры молекул, основания, входящие в состав нуклеотидов, разделяют на две группы: пурины (аденин [A] и гуанин [G]) образованы соединёнными пяти- и шестичленным гетероциклами; пиримидины (цитозин [C] и тимин [T]) — шестичленным гетероциклом[8].
В виде исключения, например, у бактериофага PBS1, в ДНК встречается пятый тип оснований — урацил ([U]), пиримидиновое основание, отличающееся от тимина отсуствием метильной группы на кольце, обычно заменяющее тимин в РНК[9].
Следует отметить, что тимин и урацил не так строго приурочены к ДНК и РНК соответственно, как это считалось ранее. Так, после синтеза некоторых молекул РНК значительное число урацилов в этих молекулах метилируется с помощью специальных ферментов, превращаясь в тимин. Это происходит в транспортных и рибосомальных РНК[10].

В зависимости от концентрации ионов и нуклеотидного состава молекулы, двойная спираль ДНК в живых организмах существует в разных формах. На рисунке (слева направо) представлены A, B и Z формы
Двойная спираль
Полимер ДНК обладает довольно сложной структурой. Нуклеотиды соединены между собой ковалентно в длинные полинуклеотидные цепи. Эти цепи в подавляющем большинстве случаев (кроме некоторых вирусов, обладающих одноцепочечными ДНК-геномами), в свою очередь, попарно объединяются при помощи водородных связей в структуру, получившую название двойной спирали [3][7]. Остов каждой из цепей состоит из чередующихся фосфатов и сахаров[11]. Фосфатные группы формируют фосфодиэфирные связи между третьим и пятым атомами углерода соседних молекул дезоксирибозы, в результате взаимодействия между 3′-гидроксильной (3′ —ОН) группой одной молекулы дезоксирибозы и 5′-фосфатной группой (5′ —РО3) другой. Асимметричные концы цепи ДНК называются 3′ (три прим) и 5′ (пять прим). Полярность цепи играет важную роль при синтезе ДНК (удлинение цепи возможно только путём присоединения новых нуклеотидов к свободному 3′ концу).
Как уже было сказано выше, у подавляющего большинства живых организмов ДНК состоит не из одной, а из двух полинуклеотидных цепей. Эти две длинные цепи закручены одна вокруг другой в виде двойной спирали, стабилизированной водородными связями, образующимися между обращёнными друг к другу азотистыми основаниями входящих в неё цепей. В природе эта спираль, чаще всего, правозакрученная. Направления от 3′ конца к 5′ концу в двух цепях, из которых состоит молекула ДНК, противоположны (цепи «антипараллельны» друг другу).
Ширина двойной спирали составляет от 22 до 24 Å (ангстрем), или 2,2 — 2,4 нанометра, длина каждого нуклеотида 3,3 Å (0,33 нанометра)[12]. Подобно тому, как в винтовой лестнице сбоку можно увидеть ступеньки, на двойной спирали ДНК в промежутках между фосфатным остовом молекулы можно видеть ребра оснований, кольца которых расположены в плоскости, перпендикулярной по отношению к продольной оси макромолекулы.
В двойной спирали различают малую (12 Å) и большую (22 Å) бороздки[13]. Белки, например, факторы транскрипции, которые присоединяются к определённым последовательностям в двухцепочечной ДНК, обычно взаимодействуют с краями оснований в большой бороздке, где те более доступны.[14].
Образование связей между основаниями
Каждое основание на одной из цепей связывается с одним определённым основанием на второй цепи. Такое специфическое связывание называется комплементарным. Пурины комплементарны пиримидинам (то есть, способны к образованию водородных связей с ними): аденин образует связи только с тимином, а цитозин — с гуанином. В двойной спирали цепочки также связаны с помощью гидрофобных связей и стэкинга, которые не зависят от последовательности оснований ДНК[15].
Комплементарность двойной спирали означает, что информация, содержащаяся в одной цепи, содержится и в другой цепи. Обратимость и специфичность взаимодействий между комплементарными парами оснований важна для репликации ДНК и всех остальных функций ДНК в живых организмах.
Так как водородные связи нековалентны, они легко разрываются и восстанавливаются. Цепочки двойной спирали могут расходиться как замок-молния под действием ферментов (хеликазы) или при высокой температуре[16]. Разные пары оснований образуют разное количество водородных связей. АТ связаны двумя, ГЦ — тремя водородными связями, поэтому на разрыв ГЦ требуется больше энергии. Процент ГЦ пар и длина молекулы ДНК определяют количество энергии, необходимой для диссоциации цепей: длинные молекулы ДНК с большим содержанием ГЦ более тугоплавки[17].
Части молекул ДНК, которые из-за их функций должны быть легко разделяемы, например ТАТА последовательность в бактериальных промоторах, обычно содержат большое количество А и Т.

Интеркалированное химическое соединение, которое находится в середине спирали -бензопирен, основной мутаген табачного дыма[18]
Химические модификации оснований
Структура хроматина влияет на транскрипцию генов: участки гетерохроматина (отсутствие или низкий уровень транскрипции генов) коррелирует с метилированием цитозина. Например, метилирование цитозина с образованием 5-метилцитозина важно для инактивации Х-хромосомы[19]. Средний уровень метилирования отличается у разных организмов, так у нематоды Caenorhabditis elegans метилирование цитозина не наблюдается, а у позвоночных обнаружен высокий уровень метилирования — до 1% [20].
Несмотря на биологическую роль, 5-метилцитозин может спонтанно утрачивать аминную группу (деаминироваться), превращаясь в тимин, поэтому метилированные цитозины являются источником повышенного числа мутаций[21]. Другие модификации оснований включают метилирование аденина у бактерий и гликозилирование урацила с образованием «J-основания» в кинетопластах[22].
Повреждение ДНК
ДНК может повреждаться разнообразными мутагенами, к которым относятся окисляющие и алкилирующие вещества, а также высокоэнергетическая электромагнитная радиация — ультрафиолетовое и рентгеновское излучение. Тип повреждения ДНК зависит от типа мутагена. Например, ультрафиолет повреждает ДНК путём образования в ней димеров тимина, которые образуются при образовании ковалентных связей между соседними основаниями[23]. Оксиданты, такие как свободные радикалы или перекись водорода приводят к нескольким типам повреждения ДНК, включая модификации оснований, в особенности гуанозина, а также двуцепочечные разрывы в ДНК [24]. По некоторым оценкам в каждой клетке человека окисляющими соединениями ежедневно повреждается порядка 500 оснований[25][26]. Среди разных типов повреждений наиболее опасные — это двуцепочечные разрывы, потому что они трудно репарируются и могут привести к потерям участков хромосом (делециям) и транслокациям.
Многие молекулы мутагенов вставляются (интеркалируют) между двумя соседними парами оснований. Большинство этих соединений, например, этидий, дауномицин, доксорубицин и талидомид имеют ароматическую структуру. Для того, чтобы интеркалирующее соединение могло поместиться между основаниями, они должны разойтись, расплетая и нарушая структуру двойной спирали. Эти изменения в структуре ДНК мешают транскрипции и репликации, вызывая мутации. Поэтому интеркалирующие соединения часто являются канцерогенами, наиболее известные из которых — бензопирен, акридины, афлатоксин и бромистый этидий[27][28][29]. Несмотря на эти негативные свойства, в силу их способности подавлять транскрипцию и репликацию ДНК, интеркалирующие соединения используются в химиотерапии для подавления быстро растущих клеток рака[30].
Суперскрученность
Если взяться за концы верёвки и начать скручивать их в разные стороны, она становится короче и на верёвке образуются «супервитки». Так же может быть суперскручена и ДНК. В обычном состоянии цепочка ДНК делает один оборот на каждые 10,4 основания, но в суперскрученном состоянии спираль может быть свёрнута туже или расплетена[31]. Выделяют два типа суперскручивания: положительное — в направлении нормальных витков, при котором основания расположены ближе друг к другу; и отрицательное — в противоположном направлении. В природе молекулы ДНК обычно находятся в отрицательном суперскручивании, которое вносится ферментами — топоизомеразами[32]. Эти ферменты удаляют дополнительное скручивание, возникающее в ДНК в результате транскрипции и репликации[33].
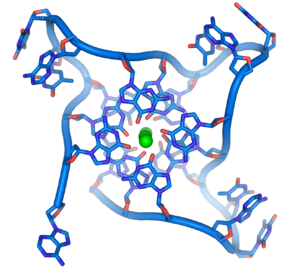
Структура теломер. Зелёным цветом показан ион металла, хелатированный в центре структуры[34]
Структуры на концах хромосом
На концах линейных хромосом находятся специализированные структуры ДНК, называемые теломерами. Основная функция этих участков — поддержание целостности концов хромосом[35]. Теломеры также защищают концы ДНК от деградации экзонуклеазами и предотвращают активацию системы репарации[36]. Поскольку обычные ДНК-полимеразы не могут реплицировать 3′ концы хромосом, это делает специальный фермент — теломераза.
В клетках человека теломеры обычно представлены одноцепочечной ДНК и состоят из несколько тысяч повторяющихся единиц последовательности ТТАГГГ[37]. Эти последовательности с высоким содержанием гуанина стабилизируют концы хромосом, формируя очень необычные структуры, называемые G-квадруплексами и состоящие из четырёх, а не двух взаимодействующих оснований. Четыре гуаниновых основания, все атомы которых находятся в одной плоскости, образуют пластинку, стабилизированную водородными связями между основаниями и хелатированием в центре неё иона металла (чаще всего калия). Эти пластинки располагаются стопкой друг над другом[38].
На концах хромосом могут образовываться и другие структуры: основания могут быть расположены в одной цепочке или в разных параллельных цепочках. Кроме этих «стопочных» структур теломеры формируют большие петлеобразные структуры, называемые Т-петли или теломерные петли. В них одноцепочечная ДНК располагается в виде широкого кольца, стабилизированного теломерными белками[39]. В конце Т-петли одноцепочечная теломерная ДНК присоединяется к двухцепочечной ДНК, нарушая спаривание цепочек в этой молекуле и образуя связи с одной из цепей. Это трёхцепочечное образование называется Д-петля (от англ. displacement loop)[38].
Биологические функции
ДНК является носителем генетической информации, записанной в виде последовательности нуклеотидов с помощью генетического кода. С молекулами ДНК связаны два основополагающих свойства живых организмов — наследственность и изменчивость. В ходе процесса, называемого репликацией ДНК, образуются две копии исходной цепочки, наследуемые дочерними клетками при делении, таким образом образовавшиеся клетки оказываются генетически идентичны исходной.
Генетическая информация реализуется при экспрессии генов в процессах транскрипции (синтеза молекул РНК на матрице ДНК) и трансляции (синтеза белков на матрице РНК).
Последовательность нуклеотидов «кодирует» информацию о различных типах РНК: информационных, или матричных (иРНК), рибосомальных (рРНК) и транспортных (тРНК). Все эти типы РНК синтезируются на основе ДНК в процессе транскрипции. Роль их в биосинтезе белков (процессе трансляции) различна. Информационная РНК содержит информацию о последовательности аминокислот в белке, рибосомальные РНК служат основой для рибосом (сложных нуклеопротеиновых комплексов, основная функция которых — сборка белка из отдельных аминокислот на основе иРНК), транспортные РНК доставляют аминокислоты к месту сборки белков — в активный центр рибосомы, «ползущей» по иРНК.
Структура генома
ДНК генома бактериофага: фотография под трансмиссионным электронным микроскопом.
Большинство природных ДНК имеет двухцепочечную структуру, линейную (эукариоты, некоторые вирусы и отдельные роды бактерий) или кольцевую (прокариоты, хлоропласты и митохондрии). Линейную одноцепочечную ДНК содержат некоторые вирусы и бактериофаги. В клетках эукариот ДНК располагается главным образом в ядре в виде набора хромосом. Бактериальная (прокариоты) ДНК обычно представлена одной кольцевой молекулой ДНК, расположенной в неправильной формы образовании в цитоплазме, называемым нуклеоидом [40]. Генетическая информация генома состоит из генов. Ген — единица передачи наследственной информации и участок ДНК, который влияет на определённую характеристику организма. Ген содержит открытую рамку считывания, которая транскрибируется, а также регуляторные последовательности, например, промотор и энхансер, которые контролируют экспрессию открытых рамок считывания.
У многих видов только малая часть общей последовательности генома кодирует белки. Так только около 1,5 % генома человека состоит из кодирующих белок экзонов, а больше 50 % ДНК человека состоит из некодирующих повторяющихся последовательностей ДНК[41]. Причины наличия такого большого количества некодирующей ДНК в эукариотических геномах и огромная разница в размерах геномов (С-значение) одна из неразрешённых научных загадок[42].
Последовательности генома, не кодирующие белок
-
Основная статья: Некодирующая ДНК
В настоящее время накапливается всё больше данных, противоречащих идее о некодирующих последовательностях как «мусорной ДНК» (англ. junk DNA). Теломеры и центромеры содержат малое число генов, но они важны для функционирования и стабильности хромосом[36][43]. Часто встречающаяся форма некодирующих последовательностей человека — псевдогены, копии генов, инактивированные в результате мутаций[44]. Эти последовательности нечто вроде молекулярных ископаемых, хотя иногда они могут служить исходным материалом для дупликации и последующей дивергенции генов[45]. Другой источник разнообразия белков в организме, это использование интронов в качестве «линий разреза и склеивания» в альтернативном сплайсинге[46]. Наконец, некодирующие белок последовательности могут кодировать вспомогательные клеточные РНК, например, мяРНК[47]. Недавнее исследование транскрипции генома человека показало, что 10 % генома даёт начало полиаденилированным РНК [48], а исследование и генома мыши показало, что 62 % его транскрибируется[49].
Транскрипция и трансляция
Генетическая информация, закодированная в ДНК, должна быть прочитана и в конечном итоге выражена в синтезе различных биополимеров, из которых состоят клетки. Последовательность оснований в цепочке ДНК напрямую определяет последовательность оснований в РНК, на которую она «переписывается» в процессе, называемом транскрипцией. В случае мРНК эта последовательность определяет аминокислоты белка. Соотношение между нуклеотидной последовательностью мРНК и аминокислотной последовательностью определяется правилами трансляции, которые называются генетическим кодом. Генетический код состоит из трёхбуквенных «слов», называемых кодонами, состоящих из трёх нуклеотидов (то есть ACT CAG TTT и т. п.). Во время транскрипции нуклеотиды гена копируются на синтезируемую РНК РНК-полимеразой. Эта копия в случае мРНК декодируется рибосомой, которая «читает» последовательность мРНК, осуществляя спаривание матричной РНК с транспортными РНК, которые присоединены к аминокислотам. Поскольку в трёхбуквенных комбинациях используются 4 основания, всего возможны 64 кодона (4³ комбинации). Кодоны кодируют 20 стандартных аминокислот, каждой из которых соответствует в большинстве случаев более одного кодона. Один из трёх кодонов, которые располагаются в конце мРНК, не означает аминокислоту и определяет конец белка, это «стоп» или «нонсенс» кодоны — TAA, TGA, TAG.
Репликация
Деление клеток необходимо для размножения одноклеточного и роста многоклеточного организма, но до деления клетка должна удвоить геном, чтобы дочерние клетки содержали ту же генетическую информацию, что и исходная клетка. Из нескольких теоретически возможных механизмов удвоения (репликации) ДНК реализуется полуконсервативный. Две цепочки разделяются и затем каждая недостающая комплементарная последовательность ДНК воспроизводится ферментом ДНК-полимеразой. Этот фермент строит полинуклеотидную цепь, находя правильное основание через комплементарное спаривание оснований и присоединяя его к растущей цепочке. ДНК-полимераза не может начинать новую цепь, а только лишь наращивать уже существующую, поэтому она нуждается в короткой цепочке нуклеотидов (праймере), синтезируемом праймазой. Так как ДНК-полимеразы могут строить цепочку только в направлении 5′ —> 3′, для копирования антипараллельных цепей используются разные механизмы[50].
Взаимодействие с белками
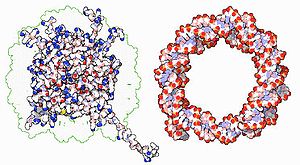
Взаимодействие ДНК с гистонами. Основные аминокислоты гистонов (на рисунке показаны голубым цветом) взаимодействуют с кислотными фосфатными группами ДНК (красный цвет).
Все функции ДНК зависят от её взаимодействия с белками. Взаимодействия могут быть как неспецифическими, когда белок присоединяется к любой молекуле ДНК или зависеть от наличия особой последовательности. Ферменты также могут взаимодействовать с ДНК, из них наиболее важные это РНК-полимеразы, которые копируют последовательность оснований ДНК на РНК в транскрипции или при синтезе новой цепи ДНК — репликации.
Структурные и регуляторные белки
Хорошо изученными примерами взаимодействия белков и ДНК, не зависящего от нуклеотидной последовательности ДНК, является взаимодействие со структурными белками. В клетке ДНК связана с этими белками, образуя компактную структуру, которая называется хроматин. У прокариот хроматин образован при присоединении к ДНК небольших щелочных белков — гистонов, менее упорядоченный хроматин прокариот содержит гистон-подобные белки[51][52]. Гистоны формируют дискообразную белковую структуру — нуклеосому, вокруг каждой из которых вмещается два оборота спирали ДНК. Неспецифические связи между гистонами и ДНК образуются за счёт ионных связей щелочных аминокислот гистонов и кислотных остатков сахарофостфатного остова ДНК[53]. Химические модификации этих аминокислот включают метилирование, фосфорилирование и ацетилирование[54]. Эти химические модификации изменяют силу взаимодействия между ДНК и гистонами, влияя на доступность специфических последовательностей для факторов транскрипции и изменяя скорость транскрипции[55]. Другие белки в составе хроматина, которые присоединяются к неспецифическим последовательностям — белки с высокой подвижностью в гелях, которые ассоциируют большей частью с согнутой ДНК[56]. Эти белки важны для образования в хроматине структур более высокого порядка[57]. Особая группа белков, присоединяющихся к ДНК это белки, которые ассоциируют с одноцепочечной ДНК. Наиболее хорошо охарактеризованный белок этой группы у человека — репликационный белок А, без которого невозможно протекание большинства процессов, где расплетается двойная спираль, включая репликацию, рекомбинацию, и репарацию. Белки этой группы стабилизируют одноцепочечную ДНК и предотвращают формирование стеблей-петель или деградации нуклеазами[58].
В то же время другие белки узнают и присоединяются к специфическим последовательностям. Наиболее изученная группа таких белков — различные классы факторов транскрипции, то есть белки, регулирующие транскрипцию. Каждый из этих белков узнаёт свою последовательность, часто в промоторе и активирует или подавляет транскрипцию гена. Это происходит при ассоциации факторов транскрипции с РНК-полимеразой либо напрямую, либо через белки-посредники. Полимераза ассоциирует сначала с белками, а потом начинает транскрипцию[59]. В других случаях факторы транскрипции могут присоединяться к ферментам, которые модифицируют находящиеся на промоторах гистоны, что изменяет доступность ДНК для полимераз[60].
Так как специфические последовательности встречаются во многих местах генома, изменения в активности одного типа фактора транскрипции может изменить активность тысяч генов[61]. Соответственно, эти белки часто регулируются в процессах ответа на изменения в окружающей среде, развития организма и дифференцировки клеток. Специфичность взаимодействия факторов транскрипции с ДНК обеспечивается многочисленными контактами между аминокислотами и основаниями ДНК, что позволяет им «читать» последовательность ДНК. Большинство контактов с основаниями происходит в главной бороздке, где основания более доступны[14].
Ферменты, модифицирующие ДНК
Топоизомеразы и хеликазы
В клетке ДНК находится в компактном т. н. суперскрученном состоянии, иначе она не смогла бы в ней уместится. Для протекания жизненноважных процессов ДНК должна быть раскручена, что производится двумя группами белков — топоизомеразами и хеликазами.
Топоизомеразы — ферменты, которые имеют и нуклеазную и лигазную активности. Эти белки изменяют степень суперскрученности в ДНК. Некоторые из этих ферментов разрезают спираль ДНК и позволяют вращаться одной из цепей, тем самым уменьшая уровень суперскрученности, после чего фермент заделывает разрыв[32]. Другие ферменты могут разрезать одну из цепей и проводить вторую цепь через разрыв, а потом лигировать разрыв в первой цепи[62]. Топоизомеразы необходимы во многих процессах, связанных с ДНК, таких как репликация и транкрипция[33].
Хеликазы — белки, которые являются одним из молекулярных моторов. Они используют химическую энергию нуклеотидтрифосфатов, чаще всего АТФ, для разрыва водородных связей между основаниями, раскручивая двойную спираль на отдельные цепочки[63]. Эти ферменты важны для большинства процессов, где белкам необходим доступ к основаниям ДНК.
Нуклеазы и лигазы
В различных процессах, происходящих в клетке, например, рекомбинации и репарации участвуют ферменты, способные разрезать и восстанавливать целостность нитей ДНК. Ферменты, разрезающие ДНК, носят название нуклеаз. Нуклеазы, которые гидролизуют нуклеотиды на концах молекулы ДНК называются экзонуклеазами, а эндонуклеазы разрезают ДНК внутри цепи. Наиболее часто используемые в молекулярной биологии и генетической инженерии нуклеазы — это рестриктазы, которые разрезают ДНК около специфических последовательностей. Например, фермент EcoRV (рестрикционный фермент № 5 из E. coli) узнаёт шестинуклеотидную последовательность 5′-GAT|ATC-3′ и разрезает ДНК в месте, указанном вертикальной линией. В природе эти ферменты защищают бактерии от заражения бактериофагами, разрезая ДНК фага, когда она вводится в бактериальную клетку. В этом случае нуклеазы — часть системы модификации-рестрикции[64]. ДНК-лигазы сшивают сахарофосфатные основания в молекуле ДНК, используя энергию АТФ. Рестрикционные нуклеазы и лигазы используются в клонировании и фингерпринтинге.
ДНК-полимераза I (кольцеобразная структура, состоящая из нескольких одинаковых молекул белка, показанных разными цветами), лигирующая повреждённую цепь ДНК
Полимеразы
Существует также важная для метаболизма ДНК группа ферментов, которые синтезируют цепи полинуклеотидов из нуклеозидтрифосфатов — ДНК-полимеразы. Они добавляют нуклеотиды к 3′-гидроксильной группе предыдущего нуклеотида в цепи ДНК, поэтому все полимеразы работают в направлении 5′—> 3′ [65]. В активном центре этих ферментов субстрат — нуклеозидтрифосфат — спаривается с комплементарным основанием в составе одноцепочечной полинулеотидной цепочки — матрицы.
В процессе репликации ДНК, ДНК-зависимая ДНК-полимераза синтезирует копию исходной последовательности ДНК. Точность очень важна в этом процессе, так как ошибки в полимеризации приведут к мутациям, поэтому многие полимеразы обладают способностью к «редактированию» — исправлению ошибок. Полимераза узнаёт ошибки в синтезе по отсутствию спаривания между неправильными нуклеотидами. После определения отсутствия спаривания активируется 3′—> 5′ экзонуклеазная активность полимеразы и неправильное основание удаляется[66]. В большинстве организмов ДНК-полимеразы работают в виде большого комплекса, называемого реплисомой, которая содержит многочисленные дополнительные субъединицы, например, хеликазы[67].
РНК-зависимые ДНК-полимеразы — специализированный тип полимераз, которые копируют последовательность РНК на ДНК. К этому типу относится вирусный фермент обратная транскриптаза, который используется ретровирусами при инфекции клеток, а также теломераза, необходимая для репликации теломер[68]. Теломераза — необычный фермент, потому что она содержит собственную матричную РНК[36].
Транскрипция осуществляется ДНК-зависимой РНК-полимеразой, которая копирует последовательность ДНК одной цепочки на мРНК. В начале транскрипции гена РНК-полимераза присоединяется к последовательности в начале гена, называемой промотором, и расплетает спираль ДНК. Потом она копирует последовательность гена на матричную РНК до тех пор, пока не дойдёт до участка ДНК в конце гена — терминатора, где она останавливается и отсоединяется от ДНК. Также как ДНК-зависимая ДНК-полимераза человека, РНК-полимераза II, которая транскрибирует большую часть генов в геноме человека, работает в составе большого белкового комплекса, содержащего регуляторные и дополнительные единицы [69].
Генетическая рекомбинация
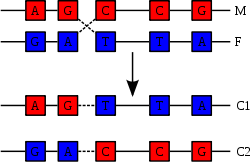
Рекомбинация происходит в результате физического разрыва в хромосомах (М) и (F) и их последующего соединения с образованием двух новых хромосом (C1 and C2)
Двойная спираль ДНК обычно не взаимодействует с другими сегментами ДНК, и в человеческих клетках разные хромосомы пространственно разделены в ядре[70]. Это расстояние между разными хромосомами важно для способности ДНК действовать в качестве стабильного носителя информации. В процессе рекомбинации с помощью ферментов две спирали ДНК разрываются, обмениваются участками, после чего непрерывность спиралей восстанавливается, поэтому обмен участками негомологичных хромосом может привести к повреждению целостности генетического материала.
Рекомбинация позволяет хромосомам обмениваться генетической информацией, в результате этого образуются новые комбинации генов, что увеличивает эффективность естественного отбора и важно для быстрой эволюции новых белков[71]. Генетическая рекомбинация также играет роль в репарации, особенно в ответе клетки на разрыв обеих цепей ДНК.[72]
Самая распространённая форма кроссинговера — это гомологичная рекомбинация, когда принимающие участие в рекомбинации хромосомы имеют очень похожие последовательности. Иногда в качестве участков гомологии выступают транспозоны. Негомологичная рекомбинация может привести к повреждению клетки, поскольку в результате такой рекомбинации возникают транслокации. Реакция рекомбинации катализируется ферментами, которые называются рекомбиназы, напрмер, Cre. На первом этапе реакции рекомбиназа делает разрыв в одной из цепей ДНК, позволяя этой цепи отделиться от комплементарной цепи и присоединится к одной из цепей второй хроматиды. Второй разрыв в цепи второй хроматиды позволяет ей также отделиться и присоединится к оставшейся без пары цепи из первой хроматиды, фомируя структуру Холлидея. Структура Холлидея может передвигаться вдоль соединённой пары хромосом, меняя цепи местами. Реакция рекомбинации завершается, когда фермент разрезает соединение, а две цепи лигируются.[73]
Эволюция метаболизма, основанного на ДНК
ДНК содержит генетическую информацию, которая делает возможной жизнедеятельность, рост, развитие и размножение всех современных организмов. Однако как долго в течение четырёх миллиардов лет истории жизни на Земле ДНК была главным носителем генетической информации, неизвестно. Существуют гипотезы, что РНК играла центральную роль в обмене веществ, поскольку она может и переносить генетическую информацию, и осуществлять катализ с помощью рибозимов[65][74] [75]. Кроме того, РНК — один из основных компонентов «фабрик белка» — рибосомы. Древний РНК-мир, где нуклеиновая кислота была использована и для катализа и для переноса информации мог послужить источником современного генетического кода, состоящего из четырёх оснований. Это могло произойти в результате того, что число оснований в организме было компромиссом между небольшим числом оснований, увеличивавшим точность репликации, и большим числом оснований, увеличивающим каталитическую активность рибозимов [76].
К сожалению, древние генетические системы не дошли до наших дней. ДНК в окружающей среде в среднем сохраняется в течение 1 миллиона лет, а потом деградирует до коротких фрагментов. Извлечение ДНК и определение последовательности их 16S рРНК генов из заключённых в кристаллах соли, образовавшихся 250 млн лет назад, бактериальных спор[77] служит темой оживлённой дискуссии в научной среде[78][79].
См. также
- Использование ДНК в технологии
- Вектор (биология)
- Генетическая генеалогия
- Действие излучений на структуру и функции ДНК
- Метилирование ДНК
- Мобильные элементы генома
- Мутация
- Нуклеопротеиды
- РНК
- Центральная догма молекулярной биологии
Ссылки
- Методы выделения и исследования ДНК
- Веб-адреса молекулярно-биологических журналов
- Международная база данных — последовательности ДНК из разных организмов (англ.).
- Репликация ДНК (анимация)(англ.)
- Веб-сайт Сэнгеровского Института одного из мировых лидеров в области определения последовательностей ДНК и их анализа (англ.)
- Software for forensic DNA Typing — eQMS::DNA
Рекомендуемая литература
- Альбертс Б.; Брей Д.; Льюис Дж. и др. Молекулярная биология клетки в 3-х томах. М.: Мир, 1994. 1558 с ISBN 5-03-001986-3
- Докинз Р. Эгоистичный ген, М.: Мир[80]
- История биологии с начала XX века до наших дней. М.: Наука, 1975. 660 с.
- Льюин Б. Гены. М.: Мир, 1987. 1064 с.
- Пташне М. Переключение генов. Регуляция генной активности и фаг лямбда. М.: Мир, 1989. 160 с,[81]
- Уотсон Дж. Д. Двойная спираль: воспоминания об открытии структуры ДНК. М.: Мир, 1969. 152 с.
Литература
- ↑ Dahm R (2005). «Friedrich Miescher and the discovery of DNA». Dev Biol 278 (2): 274–88. PMID 15680349.
- ↑ Hershey A, Chase M (1952). «Independent functions of viral protein and nucleic acid in growth of bacteriophage». J Gen Physiol 36 (1): 39–56. PMID 12981234.
- ↑ 1 2 Watson J, Crick F (1953). «Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid». Nature 171 (4356): 737 – 8. PMID 13054692.
- ↑ The Nobel Prize in Physiology or Medicine 1962 Nobelprize .org Accessed 22 Dec 06
- ↑ Bruce Alberts Molecular Biology of the Cell; Fourth Edition. — New York and London: Garland Science. — ISBN ISBN 0-8153-3218-1
- ↑ Butler, John M. (2001) Forensic DNA Typing «Elsevier». pp. 14 — 15. ISBN 978-0-12-147951-0
- ↑ 1 2 Berg J., Tymoczko J. and Stryer L. (2002) Biochemistry. W. H. Freeman and Company ISBN 0-7167-4955-6
- ↑ Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Accessed 03 Jan 2006
- ↑ Takahashi I, Marmur J. (1963). «Replacement of thymidylic acid by deoxyuridylic acid in the deoxyribonucleic acid of a transducing phage for Bacillus subtilis». Nature 197: 794 – 5. PMID 13980287.
- ↑ Agris P (2004). «Decoding the genome: a modified view». Nucleic Acids Res 32 (1): 223 – 38. PMID 14715921.
- ↑ Ghosh A, Bansal M (2003). «A glossary of DNA structures from A to Z». Acta Crystallogr D Biol Crystallogr 59 (Pt 4): 620 – 6. PMID 12657780.
- ↑ Mandelkern M, Elias J, Eden D, Crothers D (1981). «The dimensions of DNA in solution». J Mol Biol 152 (1): 153 – 61. PMID 7338906.
- ↑ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson R (1980). «Crystal structure analysis of a complete turn of B-DNA». Nature 287 (5784): 755 – 8. PMID 7432492.
- ↑ 1 2 Pabo C, Sauer R. «Protein-DNA recognition». Annu Rev Biochem 53: 293 – 321. PMID 6236744.
- ↑ Ponnuswamy P, Gromiha M (1994). «On the conformational stability of oligonucleotide duplexes and tRNA molecules». J Theor Biol 169 (4): 419–32. PMID 7526075.
- ↑ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub H (2000). «Mechanical stability of single DNA molecules». Biophys J 78 (4): 1997–2007. PMID 10733978.
- ↑ Chalikian T, Völker J, Plum G, Breslauer K (1999). «A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques». Proc Natl Acad Sci U S A 96 (14): 7853–8. PMID 10393911.
- ↑ Created from PDB 1JDG
- ↑ Klose R, Bird A (2006). «Genomic DNA methylation: the mark and its mediators». Trends Biochem Sci 31 (2): 89 – 97. PMID 16403636.
- ↑ Bird A (2002). «DNA methylation patterns and epigenetic memory». Genes Dev 16 (1): 6 – 21. PMID 11782440.
- ↑ Walsh C, Xu G. «Cytosine methylation and DNA repair». Curr Top Microbiol Immunol 301: 283 – 315. PMID 16570853.
- ↑ Gommers-Ampt J, Van Leeuwen F, de Beer A, Vliegenthart J, Dizdaroglu M, Kowalak J, Crain P, Borst P (1993). «beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei». Cell 75 (6): 1129 – 36. PMID 8261512.
- ↑ Douki T, Reynaud-Angelin A, Cadet J, Sage E (2003). «Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation». Biochemistry 42 (30): 9221 – 6. PMID 12885257.
- ↑ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget J, Ravanat J, Sauvaigo S (1999). «Hydroxyl radicals and DNA base damage». Mutat Res 424 (1 – 2): 9 – 21. PMID 10064846.
- ↑ Shigenaga M, Gimeno C, Ames B (1989). «Urinary 8-hydroxy-2′-deoxyguanosine as a biological marker of in vivo oxidative DNA damage». Proc Natl Acad Sci U S A 86 (24): 9697 – 701. PMID 2602371.
- ↑ Cathcart R, Schwiers E, Saul R, Ames B (1984). «Thymine glycol and thymidine glycol in human and rat urine: a possible assay for oxidative DNA damage». Proc Natl Acad Sci U S A 81 (18): 5633 – 7. PMID 6592579.
- ↑ Ferguson L, Denny W (1991). «The genetic toxicology of acridines». Mutat Res 258 (2): 123 – 60. PMID 1881402.
- ↑ Jeffrey A (1985). «DNA modification by chemical carcinogens». Pharmacol Ther 28 (2): 237 – 72. PMID 3936066.
- ↑ Stephens T, Bunde C, Fillmore B (2000). «Mechanism of action in thalidomide teratogenesis». Biochem Pharmacol 59 (12): 1489 – 99. PMID 10799645.
- ↑ Braña M, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (2001). «Intercalators as anticancer drugs». Curr Pharm Des 7 (17): 1745 – 80. PMID 11562309.
- ↑ Benham C, Mielke S (2005). «DNA mechanics». Annu Rev Biomed Eng 7: 21–53. PMID 16004565.
- ↑ 1 2 Champoux J (2001). «DNA topoisomerases: structure, function, and mechanism». Annu Rev Biochem 70: 369–413. PMID 11395412.
- ↑ 1 2 Wang J (2002). «Cellular roles of DNA topoisomerases: a molecular perspective». Nat Rev Mol Cell Biol 3 (6): 430–40. PMID 12042765.
- ↑ Created from NDB UD0017
- ↑ Greider C, Blackburn E (1985). «Identification of a specific telomere terminal transferase activity in Tetrahymena extracts». Cell 43 (2 Pt 1): 405–13. PMID 3907856.
- ↑ 1 2 3 Nugent C, Lundblad V (1998). «The telomerase reverse transcriptase: components and regulation». Genes Dev 12 (8): 1073–85. PMID 9553037.
- ↑ Wright W, Tesmer V, Huffman K, Levene S, Shay J (1997). «Normal human chromosomes have long G-rich telomeric overhangs at one end». Genes Dev 11 (21): 2801–9. PMID 9353250.
- ↑ 1 2 Burge S, Parkinson G, Hazel P, Todd A, Neidle S (2006). «Quadruplex DNA: sequence, topology and structure». Nucleic Acids Res 34 (19): 5402–15. PMID 17012276.
- ↑ Griffith J, Comeau L, Rosenfield S, Stansel R, Bianchi A, Moss H, de Lange T (1999). «Mammalian telomeres end in a large duplex loop». Cell 97 (4): 503–14. PMID 10338214.
- ↑ Thanbichler M, Wang S, Shapiro L (2005). «The bacterial nucleoid: a highly organized and dynamic structure». J Cell Biochem 96 (3): 506 – 21. PMID 15988757.
- ↑ Wolfsberg T, McEntyre J, Schuler G (2001). «Guide to the draft human genome». Nature 409 (6822): 824 – 6. PMID 11236998.
- ↑ Gregory T (2005). «The C-value enigma in plants and animals: a review of parallels and an appeal for partnership». Ann Bot (Lond) 95 (1): 133 – 46. PMID 15596463.
- ↑ Pidoux A, Allshire R (2005). «The role of heterochromatin in centromere function». Philos Trans R Soc Lond B Biol Sci 360 (1455): 569 – 79. PMID 15905142.
- ↑ Harrison P, Hegyi H, Balasubramanian S, Luscombe N, Bertone P, Echols N, Johnson T, Gerstein M (2002). «Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22». Genome Res 12 (2): 272 – 80. PMID 11827946.
- ↑ Harrison P, Gerstein M (2002). «Studying genomes through the aeons: protein families, pseudogenes and proteome evolution». J Mol Biol 318 (5): 1155 – 74. PMID 12083509.
- ↑ Soller M (2006). «Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22». Cell Mol Life Sci 63 (7-9): 796 – 819. PMID 16465448.
- ↑ Michalak P. (2006). «RNA world — the dark matter of evolutionary genomics» 19 (6): 1768 – 74. PMID 17040373.
- ↑ Cheng J, Kapranov P, Drenkow J, Dike S, Brubaker S et al. (2005). «RNA world — the dark matter of evolutionary genomics» 308: 1149 – 54. PMID 15790807.
- ↑ Mattick JS (2004). «RNA regulation: a new genetics?». Nat Rev Genet 5: 316-323. PMID 15131654.
- ↑ Albà M (2001). «Replicative DNA polymerases». Genome Biol 2 (1): REVIEWS3002. PMID 11178285.
- ↑ Sandman K, Pereira S, Reeve J (1998). «Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome». Cell Mol Life Sci 54 (12): 1350 – 64. PMID 9893710.
- ↑ Dame RT (2005). «The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin». Mol. Microbiol. 56 (4): 858-70. PMID 15853876.
- ↑ Luger K, Mäder A, Richmond R, Sargent D, Richmond T (1997). «Crystal structure of the nucleosome core particle at 2.8 A resolution». Nature 389 (6648): 251 – 60. PMID 9305837.
- ↑ Jenuwein T, Allis C (2001). «Translating the histone code». Science 293 (5532): 1074 – 80. PMID 11498575.
- ↑ Ito T. «Nucleosome assembly and remodelling». Curr Top Microbiol Immunol 274: 1 – 22. PMID 12596902.
- ↑ Thomas J (2001). «HMG1 and 2: architectural DNA-binding proteins». Biochem Soc Trans 29 (Pt 4): 395 – 401. PMID 11497996.
- ↑ Grosschedl R, Giese K, Pagel J (1994). «HMG domain proteins: architectural elements in the assembly of nucleoprotein structures». Trends Genet 10 (3): 94–100. PMID 8178371.
- ↑ Iftode C, Daniely Y, Borowiec J (1999). «Replication protein A (RPA): the eukaryotic SSB». Crit Rev Biochem Mol Biol 34 (3): 141 – 80. PMID 10473346.
- ↑ Myers L, Kornberg R. «Mediator of transcriptional regulation». Annu Rev Biochem 69: 729 – 49. PMID 10966474.
- ↑ Spiegelman B, Heinrich R (2004). «Biological control through regulated transcriptional coactivators». Cell 119 (2): 157-67. PMID 15479634.
- ↑ Li Z, Van Calcar S, Qu C, Cavenee W, Zhang M, Ren B (2003). «A global transcriptional regulatory role for c-Myc in Burkitt’s lymphoma cells». Proc Natl Acad Sci U S A 100 (14): 8164 – 9. PMID 12808131.
- ↑ Schoeffler A, Berger J (2005). «Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism». Biochem Soc Trans 33 (Pt 6): 1465 – 70. PMID 16246147.
- ↑ Tuteja N, Tuteja R (2004). «Unraveling DNA helicases. Motif, structure, mechanism and function». Eur J Biochem 271 (10): 1849–63. PMID 15128295.
- ↑ Bickle T, Krüger D (1993). «Biology of DNA restriction». Microbiol Rev 57 (2): 434 – 50. PMID 8336674.
- ↑ 1 2 Joyce C, Steitz T (1995). «Polymerase structures and function: variations on a theme?». J Bacteriol 177 (22): 6321 – 9. PMID 7592405.
- ↑ Hubscher U, Maga G, Spadari S. «Eukaryotic DNA polymerases». Annu Rev Biochem 71: 133 – 63. PMID 12045093.
- ↑ Johnson A, O’Donnell M. «Cellular DNA replicases: components and dynamics at the replication fork». Annu Rev Biochem 74: 283 – 315. PMID 15952889.
- ↑ Tarrago-Litvak L, Andréola M, Nevinsky G, Sarih-Cottin L, Litvak S (1994). «The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention». FASEB J 8 (8): 497–503. PMID 7514143.
- ↑ Martinez E (2002). «Multi-protein complexes in eukaryotic gene transcription». Plant Mol Biol 50 (6): 925 – 47. PMID 12516863.
- ↑ Cremer T, Cremer C (2001). «Chromosome territories, nuclear architecture and gene regulation in mammalian cells». Nat Rev Genet 2 (4): 292-301. PMID 11283701.
- ↑ Pál C, Papp B, Lercher M (2006). «An integrated view of protein evolution». Nat Rev Genet 7 (5): 337 – 48. PMID 16619049.
- ↑ O’Driscoll M, Jeggo P (2006). «The role of double-strand break repair — insights from human genetics». Nat Rev Genet 7 (1): 45 – 54. PMID 16369571.
- ↑ Dickman M, Ingleston S, Sedelnikova S, Rafferty J, Lloyd R, Grasby J, Hornby D (2002). «The RuvABC resolvasome». Eur J Biochem 269 (22): 5492 – 501. PMID 12423347.
- ↑ Orgel L. «Prebiotic chemistry and the origin of the RNA world». Crit Rev Biochem Mol Biol 39 (2): 99 – 123. PMID 15217990.
- ↑ Davenport R (2001). «Ribozymes. Making copies in the RNA world». Science 292 (5520): 1278. PMID 11360970.
- ↑ Szathmáry E (1992). «What is the optimum size for the genetic alphabet?». Proc Natl Acad Sci U S A 89 (7): 2614 – 8. PMID 1372984.
- ↑ Vreeland R, Rosenzweig W, Powers D (2000). «Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal». Nature 407 (6806): 897 – 900. PMID 11057666.
- ↑ Hebsgaard M, Phillips M, Willerslev E (2005). «Geologically ancient DNA: fact or artefact?». Trends Microbiol 13 (5): 212 – 20. PMID 15866038.
- ↑ Nickle D, Learn G, Rain M, Mullins J, Mittler J (2002). «Curiously modern DNA for a «250 million-year-old» bacterium». J Mol Evol 54 (1): 134 – 7. PMID 11734907.
- ↑ Эгоистичный ген в библиотеке FictionBook
- ↑ Все форумы > Книга «переключение генов» М. Пташне
| Типы нуклеиновых кислот | |
|---|---|
| Азотистые основания | Пурины (Аденин, Гуанин) | Пиримидины (Урацил, Тимин, Цитозин) |
| Нуклеозиды | Аденозин | Гуанозин | Уридин | Тимидин | Цитидин |
| Нуклеотиды | монофосфаты (АМФ, ГМФ, UMP, ЦМФ) | дифосфаты (АДФ, ГДФ, УДФ, ЦДФ) | трифосфаты (АТФ, ГТФ, УТФ, ЦТФ) | циклические (цАМФ, цГМФ, cADPR) |
| Рибонуклеиновые кислоты | РНК | мРНК | тРНК | рРНК | антисмысловые РНК | микроРНК | некодирующие РНК | piwi-interacting RNA | малые интерферирующие РНК | малые ядерные РНК | малые ядрышковые РНК | тмРНК |
| Дезоксирибонуклеиновые кислоты | ДНК | кДНК | Геном | msDNA | Митохондриальная ДНК |
| Аналоги нуклеиновых кислот | GNA | LNA | ПНК | TNA | Морфолино |
| Типы векторов | en:phagemid | Плазмиды | Фаг лямбда | en:cosmid | en:P1 phage | en:fosmid | BAC | YAC | HAC |
| Основные группы биохимических молекул Аминокислоты · Пептиды · Белки · Углеводы · Нуклеотиды · Нуклеиновые кислоты · Липиды · Терпены · Каротиноиды · Стероиды · Флавоноиды · Алкалоиды · Гликозиды |
Wikimedia Foundation.
2010.
http://www.biochemistry.ru/biohimija_severina/B5873Content.html
В каждом живом
организме присутствуют 2 типа нуклеиновых
кислот: рибонуклеиновая кислота (РНК)
и дезоксирибонуклеиновая кислота (ДНК).
Молекулярная масса самой «маленькой»
из известных нуклеиновых кислот —
транспортной РНК (тРНК) составляет
примерно 25 кД. ДНК — наиболее крупные
полимерные молекулы; их молекулярная
масса варьирует от 1 000 до 1 000 000 кД. ДНК
и РНК состоят из мономерных единиц —
нуклеотидов, поэтому нуклеиновые кислоты
называют полинуклеотидами.
Каждый нуклеотид
содержит 3 химически различных компонента:
гетероциклическое азотистое основание,
моносахарид (пентозу) и остаток фосфорной
кислоты. В зависимости от числа имеющихся
в молекуле остатков фосфорной кислоты
различают нуклеозидмонофосфаты (НМФ),
нуклеозиддифосфаты (НДФ), нуклео-зидтрифосфаты
(НТФ) (рис. 4-1).
В состав нуклеиновых
кислот входят азотистые основания двух
типов: пуриновые — аденин (А), гуанин (G)
и пиримидиновые — цитозин (С), тимин (Т)
и урацил (U). Нумерация атомов в основаниях
записывается внутри цикла (рис. 4-2).
Номенклатура нуклеотидов приведена в
табл. 4-1.
Пентозы в нуклеотидах
представлены либо рибозой (в составе
РНК), либо дезоксирибозой (в составе
ДНК). Чтобы отличить номера атомов в
пентозах от нумерации атомов в основаниях,
запись производят с внешней стороны
цикла и к цифре добавляют штрих (‘) — 1′,
2′, 3′, 4′ и 5’ (рис. 4-3).
Пентозу соединяет
с основанием N-гликозидная связь,
образованная С1-атомом пентозы (рибозы
или дезоксирибозы) и N1 -атомом пиримидина
или N9-aтомом пурина (рис. 4-4).
Нуклеотиды, в которых
пентоза представлена рибозой, называют
рибонуклеотидами, а нуклеиновые кислоты,
построенные из рибонуклеотидов, —
рибонуклеиновыми кислотами, или РНК.
Нуклеиновые кислоты, в мономеры которых
входит дезоксирибоза, называют
дезоксири-бонуклеиновыми кислотами,
или ДНК. Нуклеиновые кислоты по своему
строению относят к классу линейных
полимеров. Остов нуклеиновой кислоты
имеет одинаковое строение по всей длине
молекулы и состоит из чередующихся
групп — пентоза-фосфат-пентоза- (рис.
4-5). Вариабельными группами в полинуклеотидных
цепях служат азотистые основания —
пурины и пиримидины. В молекулы РНК
входят аденин (А), урацил (U), гуанин (G) и
цитозин (С), в ДНК — аденин (А), тимин (Т),
гуанин (G) и цитозин (С). Уникальность
структуры и функциональная индивидуальность
молекул ДНК и РНК определяются их
первичной структурой — последовательностью
азотистых оснований в полинуклеотидной
цепи.
Рис. 4-1. Нуклеозидмоно-,
ди- и трифосфаты аденозина. Нуклеотиды
— фосфорные эфиры нуклеозидов. Остаток
фосфорной кислоты присоединён к
5′-углеродному атому пентозы (5′-фосфоэфирная
связь).

Рис. 4-2. Пуриновые
и пиримидиновые основания.

Таблица 4-1.
Номенклатура нуклеотидов
| Азотистое | Нуклеозид | Нуклеозид | Нуклеотид | Нуклеотид |
| основание | РНК | ДНК | РНК | ДНК |
| аденин | аденозин | дезоксиаденозин | аденозин-5′-монофосфат | дезоксиаденозин-5′ |
| (А) | (dA) | (рА) | монофосфат | |
| гуанин | гуанозин | дезоксигуанозин | гуанозин-5′-монофосфат | дезоксигуанозин-5′ |
| (G) | (<Ю) | (pG) | монофосфат | |
| урацил | уридин | — | уридин-5′-монофосфат | — |
| (U) | (PU) | |||
| тимин | — | тимидин | — | тимидин-5′- |
| (dT) | монофосфат | |||
| цитозин | цитидин | дезоксицитидин | цитидин-5′-монофосфат | дезоксицитидин-5′ |
| (С) | (dC) | (рС) | монофосфат |
Рис.
4-3. Пентозы. Присутствуют 2 вида — β-D-рибоза
в составе нуклеотидов РНК и
β-D-2-дезоксирибоза в составе нуклеотидов
ДНК.

Рис.
4-4. Пуриновый и пиримидиновый нуклеотиды.

Рис.
4-5. Фрагмент цепи ДНК.

Первичная
структура ДНК —
порядок чередования
дезоксирибонуклеозидмонофосфатов
(дНМФ) в полинукпеотидной цепи.
Каждая
фосфатная группа в полинукпеотидной
цепи, за исключением фосфорного остатка
на 5′-конце молекулы, участвует в
образовании двух эфирных связей с
участием 3′- и 5′-углеродных атомов двух
соседних дезоксирибоз, поэтому связь
между мономерами обозначают 3′,
5′-фосфодиэфирной.
Концевые
нуклеотиды ДНК различают по структуре:
на 5′-конце находится фосфатная группа,
а на 3′-конце цепи — свободная ОН-группа.
Эти концы называют 5′- и 3′-концами. Линейная
последовательность дезоксирибонуклеотидов
в полимерной цепи ДНК обычно сокращённо
записывают с помощью однобуквенного
кода, например -A-G-C-T-T-A-C-A- от 5′- к 3′-концу.
В
каждом мономере нуклеиновой кислоты
присутствует остаток фосфорной кислоты.
При рН 7 фосфатная группа полностью
ионизирована, поэтому in vivo нуклеиновые
кислоты существуют в виде полианионов
(имеют множественный отрицательный
заряд). Остатки пентоз тоже проявляют
гидрофильные свойства. Азотистые
основания почти нерастворимы в воде,
но некоторые атомы пуринового и
пиримидинового циклов способны
образовывать водородные связи.
Представляет
собой цепочку последовательно связанных
нуклеотидов. Эта последовательность
несет информацию о структуре белковых
молекул. Для первичной структуры ДНК
установлены следующие закономерности
(закономерности Чаргаффа):
-
молярное
соотношение аденина к тимину равно 1; -
молярное
соотношение гуанина к цитозину равно
1; -
сумма
пуриновых нуклеотидов равна сумме
пиримидиновых
нуклеотидов; -
в
ДНК из разных источников соотношение
Г+Ц7А+Т неодинаково (коэффициент
специфичности).

Вторичная
структура ДНК.
В 1953 г. Дж. Уотсоном и Ф. Криком была
предложена модель пространственной
структуры ДНК. Согласно этой модели,
молекула ДНК имеет форму спирали,
образованную двумя полинуклеотидными
цепями, закрученными относительно друг
друга и вокруг общей оси. Двойная спираль
правозакрученная, полинуклеотидньхе
цепи в ней антипараллельны (рис. 4-6), т.е.
если одна из них ориентирована в
направлении 3’→5′, то вторая — в направлении
5’→3′. Поэтому на каждом из концов молекулы
ДНК расположены 5′-конец одной цепи и
3′-конец другой цепи.
се
основания цепей ДНК расположены внутри
двойной спирали, а пентозофосфатный
остов — снаружи. Полинуклеотидные цепи
удерживаются относительно друг друга
за счёт водородных связей между
комплементарными пуриновыми и
пиримидиновыми азотистыми основаниями
А и Т (две связи) и между G и С (три связи)
(рис. 4-7). При таком сочетании каждая ра
содержит по три кольца, поэтому общий
размер этих пар оснований одинаков по
всей длине молекулы. Водородные связи
при других сочетаниях оснований в паре
возможны, но они значительно слабее.
Последовательность нуклеотидов одной
цепи полностью комплементарна
последовательности нуклеотидов второй
цепи. Поэтому, согласно правилу Чаргаффа
(Эрвин Чаргафф в 1951 г. установил
закономерности в соотношении пуриновых
и пиримидиновых оснований в молекуле
ДНК), число пуриновых оснований (А + G)
равно числу пиримидиновых оснований
(Т + С). Комплементарые основания уложены
в стопку в сердцевине спирали. Между
основаниями двухцепочечной молекулы
в стопке возникают гидрофобные
взаимодействия, стабилизирующие двойную
спираль.
Такая
структура исключает контакт азотистых
остатков с водой, но стопка оснований
не может быть абсолютно вертикальной.
Пары оснований слегка смещены относительно
друг друга. В образованной структуре
различают две бороздки — большую, шириной
2,2 нм, и малую, шириной 1,2 нм. Азотистые
основания в области большой и малой
бороздок взаимодействуют со специфическими
белками, участвующими в организации
структуры хроматина.

Третичная
структура ДНК
(суперспирализация ДНК)
Каждая
молекула ДНК упакована в отдельную
хромосому. В диплоидных клетках человека
содержится 46 хромосом. Общая длина ДНК
всех хромосом клетки составляет 1,74 м,
но она упакована в ядре, диаметр которого
в миллионы раз меньше. Чтобы расположить
ДНК в ядре клетки, должна быть сформирована
очень компактная структура. Компактизация
и суперспирализация ДНК осуществляются
с помощью разнообразных белков,
взаимодействующих с определёнными
последовательностями в структуре ДНК.
Все связывающиеся с ДНК эукариотов
белки можно разделить на 2 группы:
гисгоновые
и негистоновые белки.
Комплекс белков с ядерной ДНК клеток
называют хроматином.
Гистоны
— белки с молекулярной массой 11-21 кД,
содержащие много остатков аргинина и
лизина. Благодаря положительному заряду
гистоны образуют ионные связи с
отрицательно заряженными фосфатными
группами, расположенными на внешней
стороне двойной спирали ДНК.
Существует
5 типов гистонов. Четыре гистона Н2А,
Н2В, НЗ и Н4 образуют октамерный белковый
комплекс (Н2А, Н2В, НЗ, Н4)2, который называют
«нуклеосомный кор» (от англ.
nucleosome core). Молекула ДНК «накручивается»
на поверхность гистонового октамера,
совершая 1,75 оборота (около 146 пар
нуклеоти-дов). Такой комплекс гистоновых
белков с ДНК служит основной структурной
единицей хроматина, её называют
«нуклеосома». ДНК, связывающую
нуклеосомные частицы, называют линкерной
ДНК. В среднем линкерная ДНК составляет
60 пар нуклеотидных остатков. Молекулы
гистона H1 связываются с ДНК в межнуклеосомных
участках (линкерных последовательностях)
и защищают эти участки от действия
нуклеаз (рис. 4-8).
В
ядре каждой клетки присутствует около
60 млн молекул каждого типа гистонов, а
общая масса гистонов примерно равна
содержанию ДНК. Аминокислотные остатки
лизина, аргинина и концевые аминогруппы
гистонов могут модифицироваться:
ацетилироваться, фосфорилироваться,
метилироваться или взаимодействовать
с белком убиквитином (неги-стоновый
белок). Модификации бывают обратимыми
и необратимыми, они изменяют заряд и
конформацию гистонов, а это влияет на
взаимодействие гистонов между собой и
с ДНК. Активность ферментов, ответственных
за модификации, регулируется и зависит
от стадии клеточного цикла. Модификации
делают возможными конформационные
перестройки хроматина.
Негистоновые
белки хроматина
В
ядре эукариотической клетки присутствуют
сотни самых разнообразных ДНК-связывающих
негистоновых белков. Каждый белок
комплементарен определённой
последовательности нуклео-тидов ДНК
(сайт ДНК). К этой группе относят семейство
сайт-специфических белков типа «цинковые
пальцы» (см. раздел 1). Каждый «цинковый
палец» узнаёт определённый сайт,
состоящий из 5 нуклеотидных пар. Другое
семейство сайт-специфических белков —
гомодимеры. Фрагмент такого белка,
контактирующий с ДНК, имеет структуру
«спираль-поворот-спираль» (см.
раздел 1). К группе структурных и
регуляторных белков, которые постоянно
ассоциированы с хроматином, относят
белки высокой подвижности (HMG-белки — от
англ, high mobility gel proteins). Они имеют молекулярную
массу менее 30 кД и характеризуются
высоким содержанием заряженных
аминокислот. Благодаря небольшой
молекулярной массе HMG-белки обладают
высокой подвижностью при электрофорезе
в полиакриламидном геле. К негистоновым
белкам принадлежат также ферменты
репликации, транскрипции и репарации.
При участии структурных, регуляторных
белков и ферментов, участвующих в синтезе
ДНК и РНК, нить нуклео-сом преобразуется
в высококонденсированный комплекс
белков и ДНК. Образованная структура в
10 000 раз короче исходной молекулы ДНК.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #