Library entries
Search library
0
pcre2
Anything after a question mark
Captures anything after a question mark
Submitted by Mohamed Heiba — 17 hours ago
0
pcre2
Odysee video URL
Odysee is a free platform to watch LBRY videos.
osChannel = Creator
osVideo = individual movie
Submitted by anonymous — 19 hours ago
0
javascript
VidID: YouTube
ID of YouTube video with provider flag
Submitted by tomByrer — 19 hours ago
0
pcre2
OGSP-102503
customer regex
Submitted by anonymous — a day ago
0
pcre2
Trying
to search string in sip call log
Submitted by Sachin — 2 days ago
0
pcre2
huji-oop-ex6
regex for huji oop course ex6
Submitted by anonymous — 2 days ago
0
pcre2
Json formatter for text
With the format: text+.
Being + the end of each line, you can export a JSON formatted file with index field for you projects.
Submitted by anonymous — 2 days ago
0
python
Skillshare matcher regex
Skillshare matcher regex
Submitted by anonymous — 2 days ago
0
pcre2
Nigerian local phone number
validate a Nigerian local phone number
Submitted by anonymous — 3 days ago
0
pcre2
Match all of the words in arbitrary order
Specify words that all have to be contained in a line; the order is arbitrary and there may be other words around them. This is most useful for searching identifiers in source code as normal word boundaries (space or punctuation) cannot be used in these cases.
The example regular expression matches…
Submitted by Sebastian Zander — 3 days ago
0
java
Match gradle dependencies
.
Submitted by anonymous — 3 days ago
0
dotnet
nick anme
mvp
Submitted by doppler — 3 days ago
0
python
Emails
test
Submitted by anonymous — 3 days ago
0
python
Markdown Images (alt text, link, description)
Extract images in a Markdown text, matching 3 named groups:
caption = alternate text
image = link (URL or relative)
description = text
…
Submitted by GeoJulien — 3 days ago
0
pcre2
YouTube extract videoId
Extract Video ID from URL Youtube
Submitted by anonymous — 3 days ago
0
pcre2
Delete empty lines
Delete empty lines
Submitted by anonymous — 4 days ago
0
java
DSA
dsa
Submitted by DSA — 4 days ago
0
pcre2
HTML tag
Regex pattern which matches HTML tag with its attributes.
Submitted by Bobkorinek — 5 days ago
0
pcre2
named query log parse
It’s a simple regexp for dns-query.log
Submitted by anonymous — 5 days ago
0
javascript
Pass/Fail
gaming pass fail shortcut
Submitted by Steve Muchow — 5 days ago
1234…821
Содержание
- Шпаргалка по регулярным выражениям. В примерах
- Основы
- Оператор ИЛИ — | или []
- Флаги
- Средний уровень
- Скобочные группы ― ()
- Скобочные выражения ― []
- Жадные и ленивые сопоставления
- Продвинутый уровень
- Границы слов ― b и B
- Шпаргалка по регулярным выражениям
- Квантификаторы
- Модификаторы
- Спецсимволы
- Спецсимволы внутри символьного класса
- Позиция внутри строки
- Якоря
- Символьные классы
- POSIX
- Утверждения
- Кванторы
- Экранирование в регулярных выражениях
- Спецсимволы экранирования в регулярных выражениях
- Подстановка строк
- Группы и диапазоны
- Модификаторы шаблонов
- Мета-символы
- Регулярное выражение кадастровый номер
- Лучшее регулярное выражение для валидации email в web формах
- Проверка надежности пароля
- Код цвета в шестнадцатеричном формате
- Проверка адреса электронной почты
- IP-адрес (v4)
- IP-адрес (v6)
- Разделитель в больших числах
- Добавление протокола перед гиперссылкой
- «Вытягиваем» домен из URL-адреса.
- Сортировка ключевых фраз по количеству слов
- Поиск валидной строки Base64 в PHP
- Проверка телефонного номера
- Начальные и конечные пробелы
- «Вытягиваем» HTML-код изображения
- Проверяем дату на соответствие формату DD/MM/YYYY
- Совпадение строки с адресом видеоролика на YouTube
- Проверка ISBN
- Проверка почтового индекса (Zip Code)
- Проверка правильности имени пользователя Twitter
- Проверка номера кредитной карты
- Поиск CSS-атрибутов
- Удаление комментариев в HTML
- Проверка на соответствие ссылке на Facebook-аккаунт
- Проверка версии Internet Explorer
- «Вытягиваем» цену из строки
- Разбираем заголовки в e-mail
- Соответствие имени файла определенному типу
- Соответствие строки формату URL
- Добавление атрибута rel=”nofollow” в теге ссылки
- Работа с media query
- Синтаксис поисковых выражений Google
- Заключение
- Регулярные выражения. Всё проще, чем кажется
- Содержание
- Что такое регулярка и с чем ее едят?
- Где писать регулярки?
- Самые простые регулярки
- Квантификаторы
- Специальные символы квантификаторов
- Специальные символы
- Lookahead и lookbehind (опережающая и ретроспективная проверки)
- Регулярные выражения в разных языках программирования
- Заключение
Шпаргалка по регулярным выражениям. В примерах

Jan 6, 2019 · 5 min read
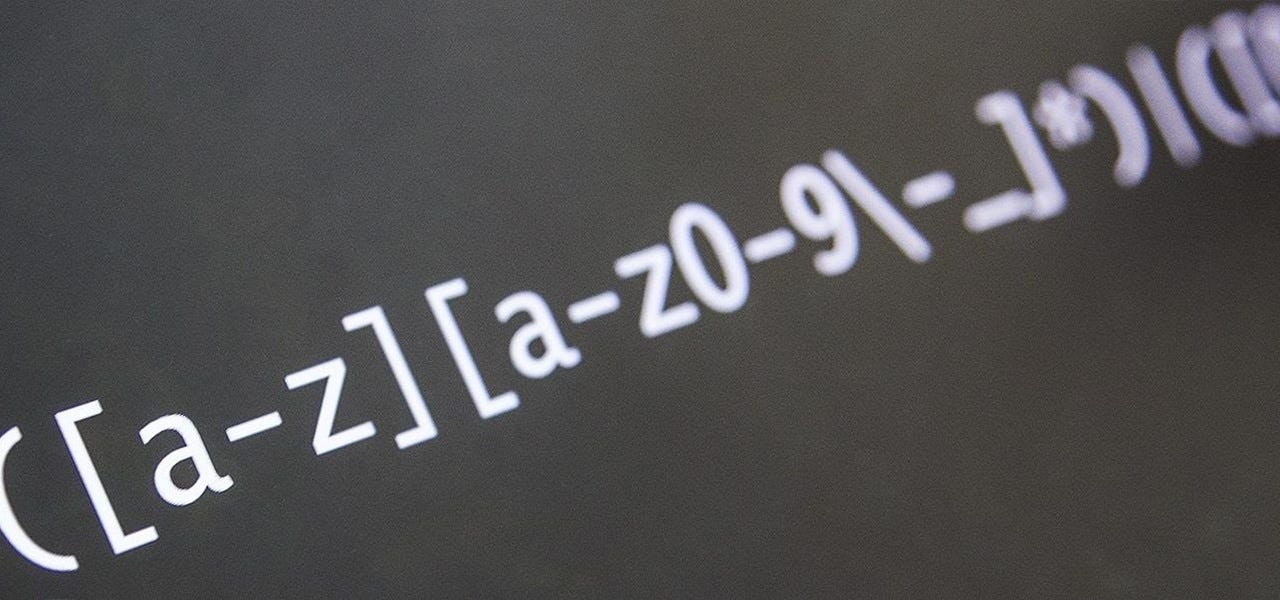
Регулярные выражения (regex или regexp) очень эффективны для извлечения информации из текста. Для этого нужно произвести поиск одного или нескольких совпадений по определённому шаблону (т. е. определённой последовательности символов ASCII или unicode).
Области применения regex разнообразны, от валидации до парсинга/замены строк, передачи данных в другие форматы и Web Scraping’а.
Одна из любопытных особенностей регулярных выражени й в их универсальности, стоит вам выучить синтаксис, и вы сможете применять их в любом (почти) языке программирования (JavaScript, Java, VB, C #, C / C++, Python, Perl, Ruby, Delphi, R, Tcl, и многих других). Небольшие отличия касаются только наиболее продвинутых функций и версий синтаксиса, поддерживаемых движком.
Давайте начнём с нескольких примеров.
Основы
Оператор ИЛИ — | или []
Флаги
Мы научились строить регулярные выражения, но забыли о фундаментальной концепции ― флагах.
Средний уровень
Скобочные группы ― ()
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Скобочные выражения ― []
Помните, что внутри скобочных выражений все специальные символы (включая обратную косую черту ) теряют своё служебное значение, поэтому нам ненужно их экранировать.
Жадные и ленивые сопоставления
Квантификаторы ( * + <> ) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.
Например, выражение соответствует
Продвинутый уровень
Границы слов ― b и B
Источник
Шпаргалка по регулярным выражениям
Квантификаторы
| Аналог | Пример | Описание | |
|---|---|---|---|
| ? | a? | одно или ноль вхождений «а» | |
| + | a+ | одно или более вхождений «а» | |
| * | a* | ноль или более вхождений «а» |
Модификаторы
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.
Спецсимволы
| Аналог | Описание | |
|---|---|---|
| () | подмаска, вложенное выражение | |
| [] | групповой символ | |
| количество вхождений от «a» до «b» | ||
| | | логическое «или», в случае с односимвольными альтернативами используйте [] | |
| экранирование спец символа | ||
| . | любой сивол, кроме перевода строки | |
| d | 2 | десятичная цифра |
| D | [^d] | любой символ, кроме десятичной цифры |
| f | конец (разрыв) страницы | |
| n | перевод строки | |
| pL | буква в кодировке UTF-8 при использовании модификатора u | |
| r | возврат каретки | |
| s | [ tvrnf] | пробельный символ |
| S | [^s] | любой символ, кроме промельного |
| t | табуляция | |
| w | [0-9a-z_] | любая цифра, буква или знак подчеркивания |
| W | [^w] | любой символ, кроме цифры, буквы или знака подчеркивания |
| v | вертикальная табуляция |
Спецсимволы внутри символьного класса
| Пример | Описание | |
|---|---|---|
| ^ | [^da] | отрицание, любой символ кроме «d» или «a» |
| — | [a-z] | интервал, любой симво от «a» до «z» |
Позиция внутри строки
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
Здесь символ ^ обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, d соответствует любой цифре от 0 до 9 включительно, w соответствует буквам и цифрам, а W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”».
Итак, парсер проверяет несколько следующих символов по предложенному шаблону ( werty ). Если они найдены, то утверждение ложно, а значит символ q будет «проигнорирован», т. е. не будет соответствовать шаблону. Если же werty не найдено, то утверждение верно, и с q все в порядке. Затем продолжается поиск любых символов, кроме пробела ( [^s]* ).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
Экранирование в регулярных выражениях
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк.
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции):
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
Модификаторы добавляются в конец этой строки, вот так:
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG.
Источник
Регулярное выражение кадастровый номер
Процесс разработки веб-приложений значительно отличается от разработки программного обеспечения, однако основные моменты при программировании одинаковы в обоих случаях, поэтому выгода от использования регулярных выражений будет видна всем.
Изучение регулярных выражений (regex) довольно сложный процесс, особенно для начинающих, но при правильном подходе, вы освоите чрезвычайно мощный и полезный инструмент.
Самым сложным этапом при обучении с нуля является понимание синтаксиса регулярных выражений. Чтобы не тратить время на написание своих собственных регулярных выражений, автор статьи собрал 30 различных примеров, которые чаще всего используются при работе над различными проектами.
Как известно, регулярные выражения не «привязаны» к какому-то определенному языку программирования, поэтому вы можете использовать приведенные ниже примеры выражений при разработке проектов на различных языках. Например, на JavaScript, PHP или Python.
Лучшее регулярное выражение для валидации email в web формах
Оговорка «на клиенте» сделана не просто так. Задача валидации на клиенте — подсказать пользователю, где он ошибся в написании email-а. Важно случайным образом не запретить пользователю с непредусмотренным емейлом воспользоваться формой. Учитывая то, какие варианты емейла могут быть (неожиданные домены, появляющиеся по пучку каждый месяц, ip адреса в качестве домена, и символы точки и симполы +, и другие неизвестные широкому обывателю вещи), напрашивается вывод, что лучшая валидация проверит емейл на наличие текста вида текст-собачка-текст-точка-текст.
Проверка надежности пароля
Код цвета в шестнадцатеричном формате
Шестнадцатеричные коды цветов используются при веб-разработке очень часто. Это регулярное выражение может быть поможет сравнить: совпадает ли какая-либо строка с шаблоном шестнадцатеричного кода.
Проверка адреса электронной почты
Одной из самых распространенных задач при разработке является проверка соответствия введенной пользователем строки формату адреса электронной почты. Существует множество различных вариантов выражений для решения этой задачи, автор этой статьи предлагает свой оригинальный вариант.
IP-адрес (v4)
Как e-mail может использоваться для идентификации посетителя, так IP-адрес является идентификатором конкретного компьютера в сети. Приведенное регулярное выражение проверяет соответствие строки формату IP-адреса v4.
IP-адрес (v6)
Вы также можете проверить строку на соответствие формату IP-адреса новой, шестой версии более продвинутым регулярным выражением.
Разделитель в больших числах
Традиционными разделителями в больших числах являются запятые, точки или другие знаки, повторяющиеся в числе через каждые 3 символа. Приведенный код регулярного выражения работает с любым числом и любым определенными вами символами для разделения трехзначных частей в больших числах: тысячах, миллионах и т.п.
Независимо от того, с каким языком вы работаете: JavaScript, Ruby или PHP, это регулярное выражение может оказаться очень полезным. С его помощью проверяется любой URL-адрес на наличие в строке протокола, и если протокол отсутствует, указанный код добавляет его в начало строки.
«Вытягиваем» домен из URL-адреса.
Как известно, любой URL-адрес состоит из нескольких частей: вначале указывается протокол (HTTP или HTTPS), иногда за ним идет субдомен, а в завершении добавляется путь к странице. Вы можете использовать это выражение, чтобы вернуть только доменное имя, исключив все остальные части адреса.
Сортировка ключевых фраз по количеству слов
Это действительно полезные выражения для пользователей Google Analytics и инструмента для веб-мастеров. Ведь с помощью них можно отсортировать ключевые фразы, используемые посетителями при поиске по количеству слов, входящих в них.
Выражения могут проверять фразы, содержащие определенное количество слов (например, 5), а также фразы количество слов в которых более двух, трех и т.д. Одно из самых мощных выражений, используемое для сортировки данных аналитики.
Поиск валидной строки Base64 в PHP
Если вы являетесь PHP-разработчиком, то иногда вам может понадобиться найти объект, закодированный в формате Base64. Указанное выше выражение может использоваться для поиска закодированных строк в любом PHP-коде.
Проверка телефонного номера
Это регулярное выражение применяется для проверки любого номера телефона, прежде всего, американского формата телефонных номеров.
Проверка телефонных номеров может стать довольно сложной задачей, поэтому автор статьи рекомендует детально ознакомиться с различными вариантами решения на сайте stackoverflow.com
Для проверки российских телефонных номеров используйте следующее выражение:
Начальные и конечные пробелы
Используйте это регулярное выражение для того, чтобы избавиться от начальных и конечных пробелом в строке. Это не особо распространенная задача, но иногда это выражение может быть полезным. Например, при получении данных из БД или передачи строки скрипту в другой кодировке.
«Вытягиваем» HTML-код изображения
Если по какой-либо причине вам необходимо «вытянуть» HTML-код изображения прямо из кода страницы, это регулярное выражение станет для вас идеальным решением. Хотя оно может без проблем работать на стороне сервера, для фронтенд-разработчиков приоритетней будет использовать метод attr() библиотеки jQuery вместо указанного регулярного выражения.
Проверяем дату на соответствие формату DD/MM/YYYY
Проверять даты сложно, потому что они могут быть представлены в различных форматах, в том числе содержащих и числа, и текст.
В PHP имеется отличная функция date(), но она не всегда подходит, ведь в нее может быть передана необработанная строка. Поэтому для проверки указанного формата даты нужно использовать приведенное выше регулярное выражение.
Совпадение строки с адресом видеоролика на YouTube
На протяжении нескольких лет на Youtube не меняется структура URL-адресов. Youtube является самым популярным видео хостингом в Интернет, благодаря этому, видео с Youtube набирают наибольший трафик.
Если вам необходимо получить ID какого-либо видеоролика с Youtube, воспользуйтесь приведенным выше регулярным выражением. Это наилучшее выражение, подходящее для всех вариантов URL-адресов на этом видео-хостинге.
Проверка ISBN
Информация обо всех печатные изданиях, хранится в системе, известной как ISBN, которая состоит из 2 систем: ISBN-10 и ISBN-13. Неспециалисту очень сложно увидеть различия между этими системами. Однако, представленное выше регулярное выражение позволяет проверять соответствие кода ISBN сразу обоим системам: будь то ISBN-10 или ISBN-13. Код написан на PHP, поэтому это решение подходит исключительно для веб-разработчиков.
Проверка почтового индекса (Zip Code)
Автор этого регулярного выражения не только придумал его, но и еще нашел время его описать. Это выражение будет полезно вам, если вы проверяете совпадение строки со стандартным пятизначным индексом или его удлиненным вариантом, содержащим 9 знаков. Обращаем ваше внимание, что это выражение подходит только для проверки американских почтовых индексов. Для индексов других стран необходима настройка.
Для проверки российских почтовых индексов используйте следующее выражение:
Проверка правильности имени пользователя Twitter
Это небольшое регулярное выражение помогает найти имя пользователя Twitter внутри текста. Оно проверяет наличие имени в твитах по шаблону: @username.
Проверка номера кредитной карты
Вы можете ознакомиться с более полным списком кодов для детальной проверки карт. Список включает в себя такие системы как Visa, MasterCard, Discover и многие другие.
Поиск CSS-атрибутов
Ситуация, когда придется воспользоваться указанным регулярным выражением, может сложиться очень редко, но не факт что не сложится никогда
Этот код можно использовать когда будет необходимо «вытянуть» какое-либо CSS-правило из списка правил для какого-нибудь селектора.
Удаление комментариев в HTML
Если вам необходимо удалить все комментарии из блока HTML-кода, воспользуйтесь этим регулярным выражением. Чтобы получить желаемый результат, вы можете воспользоваться PHP-функцией preg_replace().
Проверка на соответствие ссылке на Facebook-аккаунт
Если вам необходимо узнать у посетителя вашего сайта адрес его странички в Facebook, попробуйте это регулярное выражение. Оно поможет вам проверить правильность указанного пользователем URL. Этот код отлично подходит для проверки ссылок в этой соцсети.
Проверка версии Internet Explorer
Несмотря на то, что Microsoft выпустил новый браузер Edge, многие пользователи до сих пор пользуются Internet Explorer. Веб-разработчикам часто приходится проверять версию этого браузера, чтобы учитывать особенности разных версий при работе над своими проектами.
Вы можете использовать это регулярное выражения в JavaScript-коде чтобы узнать какая версия IE (5-11) используется.
«Вытягиваем» цену из строки
Цена какого-либо товара может быть указана в различных форматах: в ней могут встречаться запятые, знаки после запятой и символы валюты.
Указанное выше регулярное выражение учитывает различные форматы отображения цены, с его помощью вы сможете «вытянуть» цену из любой символьной строки.
Разбираем заголовки в e-mail
С помощью этого небольшого выражения вы сможете разобрать заголовок e-mail сообщения, чтобы извлечь оттуда список адресатов. Выражение может быть использовано и в случае, если адресатов несколько.
Вместо регулярных выражений, для разбора заголовков e-mail вы можете воспользуйтесь библиотекой на PHP.
Соответствие имени файла определенному типу
Если в вашем приложении существует возможность загрузки файлов на сервер, это регулярное выражение может помочь вам проверить файлы перед тем как посетитель их загрузит.
С помощью этого кода можно получить расширение загружаемого файла и проверить присутствует ли оно в списке разрешенных к загрузке.
Соответствие строки формату URL
Регулярное выражение может проверять URL-адреса с указанием протоколов HTTP и HTTPS на предмет соответствия синтаксису доменов TLD.
Существует простой способ проверки с использованием JavaScript RegExp.
Добавление атрибута rel=”nofollow” в теге ссылки
Если вы много работаете с HTML-кодом, то вам захочется автоматизировать часто повторяющиеся действия. Регулярные выражения отлично подходят для решения этой задачи и сэкономят много вашего времени.
Используя приведенный код, например, совместно с PHP, вы сможете «вытянуть» код ссылок из блоков HTML-кода и добавить в каждую из них атрибут rel=”nofollow”.
Работа с media query
Вы можете разбивать строки содержащие медиа-запросы на части, состоящие из параметров и свойств. Указанное выражение может быть полезно для анализа стороннего CSS-кода. Используя его вы сможете, например, более подробно понять как устроен чужой код.
Синтаксис поисковых выражений Google
Вы можете составить свои собственные регулярные выражения для манипулирования результатами поиска по вашим запросам в поисковой системе Google. Например, знак плюс (+) добавляет дополнительные ключевые слова, а минус (-) означает, что слова должны быть проигнорированы и удалены из результатов.
Это довольно сложное выражение, но если разобраться как использовать его должным образом, приведенный код может стать основой для построения собственного алгоритма поиска.
Заключение
Путь к пониманию регулярных выражений довольно труден, однако, если вы будете его придерживаться, результат вас не разочарует. Попробуйте использовать приведенные в статье регулярные выражения при создании своего веб-приложения. Таким образом вы сможете понять как работают выражения из примеров, приведенных в статье, в реальности.
Источник
Регулярные выражения. Всё проще, чем кажется
Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу 🙂
Содержание
Что такое регулярка и с чем ее едят?
Где писать регулярки?
Самые простые регулярки
Специальные символы квантификаторов
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Регулярные выражения в разных языках программирования
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.
Пример регулярки
 Пример регулярки
Пример регуляркиВот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание.
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
— символ повторяется ровно n раз
— символ повторяется в диапазоне от m до n раз
— символ повторяется минимум m раз (от m и более)
Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s ( <3,>обозначает, что символ s будет повторяться от трех раз и до бесконечности).
Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.
То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)
Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)
Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.
Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать . и тем самым говоря, что точка у нас будет как обычный символ.
Теперь идут, простые вещи. d у нас обозначает любую цифру. Например в тексте some text123, если написать d у нас будут выделяться только цифры.
D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать D будет браться все, кроме цифр (и пробелы, кстати, тоже).
w берет буквы, а W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]
Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)
Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)
Источник
Регулярные выражения — мощный инструмент, который должен быть в арсенале каждого разработчика. С их помощью можно находить совпадения в строках на основе довольно сложных шаблонах. Используя регулярные выражения при создании динамических веб-сайтов, разработчик экономит кучу времени.
Процесс разработки веб-приложений значительно отличается от разработки программного обеспечения, однако основные моменты при программировании одинаковы в обоих случаях, поэтому выгода от использования регулярных выражений будет видна всем.
Изучение регулярных выражений (regex) довольно сложный процесс, особенно для начинающих, но при правильном подходе, вы освоите чрезвычайно мощный и полезный инструмент.
Самым сложным этапом при обучении с нуля является понимание синтаксиса регулярных выражений. Чтобы не тратить время на написание своих собственных регулярных выражений, автор статьи собрал 30 различных примеров, которые чаще всего используются при работе над различными проектами.
Как известно, регулярные выражения не «привязаны» к какому-то определенному языку программирования, поэтому вы можете использовать приведенные ниже примеры выражений при разработке проектов на различных языках. Например, на JavaScript, PHP или Python.
Проверка надежности пароля
^(?=.*[A-Z].*[A-Z])(?=.*[!@#$&*])(?=.*[0-9].*[0-9])(?=.*[a-z].*[a-z].*[a-z]).{8}$Надежность пароля — довольно субъективное понятие, поэтому не существует универсального решения для проверки. Однако, приведенный выше пример регулярного выражения может стать хорошей отправной точкой, если вы не желаете придумывать выражение для проверки пароля с нуля.
Код цвета в шестнадцатеричном формате
Шестнадцатеричные коды цветов используются при веб-разработке очень часто. Это регулярное выражение может быть поможет сравнить: совпадает ли какая-либо строка с шаблоном шестнадцатеричного кода.
Проверка адреса электронной почты
/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igmОдной из самых распространенных задач при разработке является проверка соответствия введенной пользователем строки формату адреса электронной почты. Существует множество различных вариантов выражений для решения этой задачи, автор этой статьи предлагает свой оригинальный вариант.
IP-адрес (v4)
/b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)b/Как e-mail может использоваться для идентификации посетителя, так IP-адрес является идентификатором конкретного компьютера в сети. Приведенное регулярное выражение проверяет соответствие строки формату IP-адреса v4.
IP-адрес (v6)
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]).){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]).){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))Вы также можете проверить строку на соответствие формату IP-адреса новой, шестой версии более продвинутым регулярным выражением.
Разделитель в больших числах
/d{1,3}(?=(d{3})+(?!d))/gТрадиционными разделителями в больших числах являются запятые, точки или другие знаки, повторяющиеся в числе через каждые 3 символа. Приведенный код регулярного выражения работает с любым числом и любым определенными вами символами для разделения трехзначных частей в больших числах: тысячах, миллионах и т.п.
Добавление протокола перед гиперссылкой
if (!s.match(/^[a-zA-Z]+:///)) { s = 'http://' + s; }Независимо от того, с каким языком вы работаете: JavaScript, Ruby или PHP, это регулярное выражение может оказаться очень полезным. С его помощью проверяется любой URL-адрес на наличие в строке протокола, и если протокол отсутствует, указанный код добавляет его в начало строки.
«Вытягиваем» домен из URL-адреса.
/https?://(?:[-w]+.)?([-w]+).w+(?:.w+)?/?.*/iКак известно, любой URL-адрес состоит из нескольких частей: вначале указывается протокол (HTTP или HTTPS), иногда за ним идет субдомен, а в завершении добавляется путь к странице. Вы можете использовать это выражение, чтобы вернуть только доменное имя, исключив все остальные части адреса.
Сортировка ключевых фраз по количеству слов
^[^s]*$ //соответствует одному ключевому слову ^[^s]*s[^s]*$ //соответствует фразе из 2 ключевых слов ^[^s]*s[^s]* //соответствует фразе, содержащей по крайней мере 2 кючевых слова ^([^s]*s){2}[^s]*$ //соответствует фразе из 3 ключевых слов ^([^s]*s){4}[^s]*$ //соответствует фразе из 5 и более ключевых словЭто действительно полезные выражения для пользователей Google Analytics и инструмента для веб-мастеров. Ведь с помощью них можно отсортировать ключевые фразы, используемые посетителями при поиске по количеству слов, входящих в них.
Выражения могут проверять фразы, содержащие определенное количество слов (например, 5), а также фразы количество слов в которых более двух, трех и т.д. Одно из самых мощных выражений, используемое для сортировки данных аналитики.
Поиск валидной строки Base64 в PHP
?php[ t]eval(base64_decode('(([A-Za-z0-9+/]{4})*([A-Za-z0-9+/]{3}=|[A-Za-z0-9+/]{2}==)?){1}'));Если вы являетесь PHP-разработчиком, то иногда вам может понадобиться найти объект, закодированный в формате Base64. Указанное выше выражение может использоваться для поиска закодированных строк в любом PHP-коде.
Проверка телефонного номера
^+?d{1,3}?[- .]?(?(?:d{2,3}))?[- .]?ddd[- .]?dddd$Это регулярное выражение применяется для проверки любого номера телефона, прежде всего, американского формата телефонных номеров.
Проверка телефонных номеров может стать довольно сложной задачей, поэтому автор статьи рекомендует детально ознакомиться с различными вариантами решения на сайте stackoverflow.com
Комментарий mattweb.ru
Для проверки российских телефонных номеров используйте следующее выражение:
^((+?7|8)[ -] ?)?(((d{3}))|(d{3}))?([ -])?(d{3}[- ]?d{2}[- ]?d{2})$Начальные и конечные пробелы
Используйте это регулярное выражение для того, чтобы избавиться от начальных и конечных пробелом в строке. Это не особо распространенная задача, но иногда это выражение может быть полезным. Например, при получении данных из БД или передачи строки скрипту в другой кодировке.
«Вытягиваем» HTML-код изображения
< *[img][^>]*[src] *= *["']{0,1}([^"' >]*)Если по какой-либо причине вам необходимо «вытянуть» HTML-код изображения прямо из кода страницы, это регулярное выражение станет для вас идеальным решением. Хотя оно может без проблем работать на стороне сервера, для фронтенд-разработчиков приоритетней будет использовать метод attr() библиотеки jQuery вместо указанного регулярного выражения.
Проверяем дату на соответствие формату DD/MM/YYYY
^(?:(?:31(/|-|.)(?:0?[13578]|1[02]))1|(?:(?:29|30)(/|-|.)(?:0?[1,3-9]|1[0-2])2))(?:(?:1[6-9]|[2-9]d)?d{2})$|^(?:29(/|-|.)0?23(?:(?:(?:1[6-9]|[2-9]d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1d|2[0-8])(/|-|.)(?:(?:0?[1-9])|(?:1[0-2]))4(?:(?:1[6-9]|[2-9]d)?d{2})$Проверять даты сложно, потому что они могут быть представлены в различных форматах, в том числе содержащих и числа, и текст.
В PHP имеется отличная функция date(), но она не всегда подходит, ведь в нее может быть передана необработанная строка. Поэтому для проверки указанного формата даты нужно использовать приведенное выше регулярное выражение.
Совпадение строки с адресом видеоролика на YouTube
/http://(?:youtu.be/|(?:[a-z]{2,3}.)?youtube.com/watch(?:?|#!)v=)([w-]{11}).*/giНа протяжении нескольких лет на Youtube не меняется структура URL-адресов. Youtube является самым популярным видео хостингом в Интернет, благодаря этому, видео с Youtube набирают наибольший трафик.
Если вам необходимо получить ID какого-либо видеоролика с Youtube, воспользуйтесь приведенным выше регулярным выражением. Это наилучшее выражение, подходящее для всех вариантов URL-адресов на этом видео-хостинге.
Проверка ISBN
/b(?:ISBN(?:: ?| ))?((?:97[89])?d{9}[dx])b/iИнформация обо всех печатные изданиях, хранится в системе, известной как ISBN, которая состоит из 2 систем: ISBN-10 и ISBN-13. Неспециалисту очень сложно увидеть различия между этими системами. Однако, представленное выше регулярное выражение позволяет проверять соответствие кода ISBN сразу обоим системам: будь то ISBN-10 или ISBN-13. Код написан на PHP, поэтому это решение подходит исключительно для веб-разработчиков.
Проверка почтового индекса (Zip Code)
Автор этого регулярного выражения не только придумал его, но и еще нашел время его описать. Это выражение будет полезно вам, если вы проверяете совпадение строки со стандартным пятизначным индексом или его удлиненным вариантом, содержащим 9 знаков. Обращаем ваше внимание, что это выражение подходит только для проверки американских почтовых индексов. Для индексов других стран необходима настройка.
Комментарий mattweb.ru
Для проверки российских почтовых индексов используйте следующее выражение:
Проверка правильности имени пользователя Twitter
Это небольшое регулярное выражение помогает найти имя пользователя Twitter внутри текста. Оно проверяет наличие имени в твитах по шаблону: @username.
Проверка номера кредитной карты
^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6(?:011|5[0-9][0-9])[0-9]{12}|3[47][0-9]{13}|3(?:0[0-5]|[68][0-9])[0-9]{11}|(?:2131|1800|35d{3})d{11})$Проверка номера кредитной карты очень часто проводится при осуществлении платежей в различных платежных онлайн -системах. Однако, регулярное выражение обеспечивает минимальную проверку стандартной кредитной карты.
Вы можете ознакомиться с более полным списком кодов для детальной проверки карт. Список включает в себя такие системы как Visa, MasterCard, Discover и многие другие.
Поиск CSS-атрибутов
^s*[a-zA-Z-]+s*[:]{1}s[a-zA-Z0-9s.#]+[;]{1}Ситуация, когда придется воспользоваться указанным регулярным выражением, может сложиться очень редко, но не факт что не сложится никогда
Этот код можно использовать когда будет необходимо «вытянуть» какое-либо CSS-правило из списка правил для какого-нибудь селектора.
Удаление комментариев в HTML
Если вам необходимо удалить все комментарии из блока HTML-кода, воспользуйтесь этим регулярным выражением. Чтобы получить желаемый результат, вы можете воспользоваться PHP-функцией preg_replace().
Проверка на соответствие ссылке на Facebook-аккаунт
/(?:http://)?(?:www.)?facebook.com/(?:(?:w)*#!/)?(?:pages/)?(?:[w-]*/)*([w-]*)/Если вам необходимо узнать у посетителя вашего сайта адрес его странички в Facebook, попробуйте это регулярное выражение. Оно поможет вам проверить правильность указанного пользователем URL. Этот код отлично подходит для проверки ссылок в этой соцсети.
Проверка версии Internet Explorer
^.*MSIE [5-8](?:.[0-9]+)?(?!.*Trident/[5-9].0).*$Несмотря на то, что Microsoft выпустил новый браузер Edge, многие пользователи до сих пор пользуются Internet Explorer. Веб-разработчикам часто приходится проверять версию этого браузера, чтобы учитывать особенности разных версий при работе над своими проектами.
Вы можете использовать это регулярное выражения в JavaScript-коде чтобы узнать какая версия IE (5-11) используется.
«Вытягиваем» цену из строки
/($[0-9,]+(.[0-9]{2})?)/Цена какого-либо товара может быть указана в различных форматах: в ней могут встречаться запятые, знаки после запятой и символы валюты.
Указанное выше регулярное выражение учитывает различные форматы отображения цены, с его помощью вы сможете «вытянуть» цену из любой символьной строки.
Разбираем заголовки в e-mail
/b[A-Z0-9._%+-]+@(?:[A-Z0-9-]+.)+[A-Z]{2,6}b/iС помощью этого небольшого выражения вы сможете разобрать заголовок e-mail сообщения, чтобы извлечь оттуда список адресатов. Выражение может быть использовано и в случае, если адресатов несколько.
Вместо регулярных выражений, для разбора заголовков e-mail вы можете воспользуйтесь библиотекой на PHP.
Соответствие имени файла определенному типу
/^(.*.(?!(htm|html|class|js)$))?[^.]*$/iЕсли в вашем приложении существует возможность загрузки файлов на сервер, это регулярное выражение может помочь вам проверить файлы перед тем как посетитель их загрузит.
С помощью этого кода можно получить расширение загружаемого файла и проверить присутствует ли оно в списке разрешенных к загрузке.
Соответствие строки формату URL
/[-a-zA-Z0-9@:%_+.~#?&//=]{2,256}.[a-z]{2,4}b(/[-a-zA-Z0-9@:%_+.~#?&//=]*)?/giРегулярное выражение может проверять URL-адреса с указанием протоколов HTTP и HTTPS на предмет соответствия синтаксису доменов TLD.
Существует простой способ проверки с использованием JavaScript RegExp.
Добавление атрибута rel=”nofollow” в теге ссылки
(<as*(?!.*brel=)[^>]*)(href="/https?://)((?!(?:(?:www.)?'.implode('|(?:www.)?', $follow_list).'))[^"]+)"((?!.*brel=)[^>]*)(?:[^>]*)>Если вы много работаете с HTML-кодом, то вам захочется автоматизировать часто повторяющиеся действия. Регулярные выражения отлично подходят для решения этой задачи и сэкономят много вашего времени.
Используя приведенный код, например, совместно с PHP, вы сможете «вытянуть» код ссылок из блоков HTML-кода и добавить в каждую из них атрибут rel=”nofollow”.
Работа с media query
/@media([^{]+){([sS]+?})s*}/gВы можете разбивать строки содержащие медиа-запросы на части, состоящие из параметров и свойств. Указанное выражение может быть полезно для анализа стороннего CSS-кода. Используя его вы сможете, например, более подробно понять как устроен чужой код.
Синтаксис поисковых выражений Google
/([+-]?(?:'.+?'|".+?"|[^+- ]{1}[^ ]*))/gВы можете составить свои собственные регулярные выражения для манипулирования результатами поиска по вашим запросам в поисковой системе Google. Например, знак плюс (+) добавляет дополнительные ключевые слова, а минус (-) означает, что слова должны быть проигнорированы и удалены из результатов.
Это довольно сложное выражение, но если разобраться как использовать его должным образом, приведенный код может стать основой для построения собственного алгоритма поиска.
Заключение
Путь к пониманию регулярных выражений довольно труден, однако, если вы будете его придерживаться, результат вас не разочарует. Попробуйте использовать приведенные в статье регулярные выражения при создании своего веб-приложения. Таким образом вы сможете понять как работают выражения из примеров, приведенных в статье, в реальности.
Если у вас есть свои примеры полезных регулярных выражений, вы можете добавить их в качестве комментария к этой статье.
Почитать оригинал статьи
GET /objects/{cadNum}
Метод позволяет получить описание объекта недвижимости, который соответствует указанному в запросе кадастровому номеру.
Переменные
| Название | Тип | Формат | Обязательность | Описание |
|---|---|---|---|---|
| cadNum | string | ^d{2}:d{2}:d{6,7}:d+$ | true | Кадастровый номер |
Заголовки
| Название | Описание |
|---|---|
| Authorization | Заголовок авторизации |
Пример
GET /realty/address/v1/objects/54:35:061735:1199
Authorization: ReestroAuth apiKey=235dc85c-f7f9-4dc0-8bbf-dad9e0185afd&portal.orgid=1748b89b-7d34-4d47-b479-b06b40ab1a30
Ответы
200
Тело ответа
Ответ содержит описание найденного объекта.
| Название | Тип | Формат | Обязательность | Описание |
|---|---|---|---|---|
| cadastralNumber | string | ^d{2}:d{2}:d{6,7}:d+$ | true | Кадастровый номер объекта |
| address | object | Address | true | Адрес объекта недвижимости |
Заголовки ответа
| Название | Описание |
|---|---|
| Content-Type | Тип содержимого |
Пример ответа
HTTP 200
Content-Type: Application/json
{
"cadastralNumber": "54:35:061735:1199",
"address" :
{
"structuralAddress":
{
"region": "54",
"city": {
"name": "Новосибирск",
"abbreviation": "г"
},
"urbanDistrict":
{
"name": "Ленинский",
"abbreviation": "р-н"
},
"street":
{
"name": "Романтиков",
"abbreviation": "ул"
},
"house":
{
"name": "3",
"abbreviation": "д"
},
"apartment":
{
"name": "116",
"abbreviation": "кв"
}
},
"note": "Новосибирская область, город Новосибирск, Ленинский район, улица Романтиков, дом 3, квартира 116"
}
}
400
Ошибки валидации запроса. В теле ответа содержится описание ошибки Error.
Пример ответа
HTTP 400
Content-Type Application/json
{
"code": "validation",
"message": "Failed to validate input request",
"target": "api"
}
401
Ошибка авторизации: пользователь не авторизован
403
Ошибка аутентификации: пользователь не имеет доступа к ресурсам организации, которая указана в заголовке авторизации
404
Объекты, удовлетворяющие параметрам запроса, не найдены.